百度 paddle OCR 简单配置
百度 paddle OCR
- 百度 paddle OCR 简单使用
-
- 1、代码下载
- 2、简单测试
- 3、更换模型测试
百度 paddle OCR 简单使用
1、代码下载
可以直接去paddle OCR的github或者gitee去寻找源码
链接: github链接
链接: gitee链接

下载完成之后,解压压缩包,用pycharm将文件夹作为工程打开
打开后,需要安装各种依赖包,这里提供一种思路
1、创建虚拟环境venv,注意打红勾处不要勾选(为了将本工程的依赖包和python解释器下的依赖包隔离起来,方便工程的开发和转移)
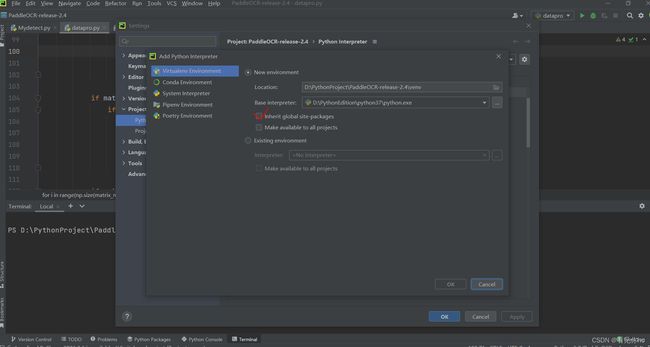
2、创建玩虚拟环境后,在pycharm的Terminal中进入虚拟环境目录(使用命令行安装依赖包)!注意,创建完虚拟环境就直接执行pip命令,通过官方给的命令,就可以保证运行,自己一个个安装的话可能会有依赖包之间彼此版本不兼容的问题。

3、进入虚拟环境的子文件夹中(其中pip list可以用于查看安装了那些依赖包),如果出现了无法进入环境的错误,参考这篇博文:
链接: 解决方案

4、执行官方的pip 命令(划红线的代码,根据自己是GPU或者CPU进行选择)
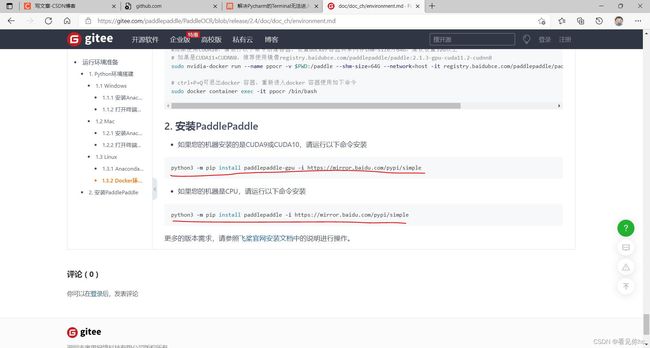
再执行下面划红线的代码
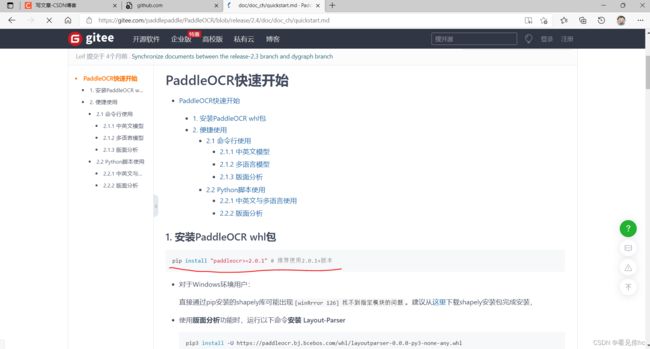
//
到这里环境基本就完成了,如果有问题可以在讨论区咨询,博主有时间就回复。
2、简单测试
这里可以直接新建一个Mydetect.py文件,与paddleocr.py保持同一级目录。之后在里面复制官方的测试程序

针对自己的需要可以对红线里的代码进行修改,实测可以用opencv来读写图片。
3、更换模型测试
首先给出官方的链接:
链接: link
1、博主下载的检测阶段模型(只用了推理模型,暂不考虑训练模型),标红线处

博主下载的识别阶段模型(只用了推理模型,暂不考虑训练模型),标红线处

2、下载完之后解压压缩包,之后将文件夹移动到默认的模型下载位置


3、在首次运行Mydetect.py文件时,会自动下载模型,要记录下模型下载的位置,方面后续更换别的模型进行测试。

4、完成模型文件的下载和更换后,修改Mydetect.py中的函数使用新的模型进行检测

到此,全部完成!!!