hadoop权威指南-MapReduce气象程序实现过程
hadoop权威指南-MapReduce气象程序实验
- 准备工作
-
- 数据准备
- 整理数据
- 代码部分
- 编译程序
- 运行程序
准备工作
数据准备
下载本次实验的所需数据,数据量可跟实际需求下载。本例使用2018年部分数据。
下载地址:ftp://ftp.ncdc.noaa.gov/pub/data/noaa
linux中下载方法:wget -r ftp://ftp.ncdc.noaa.gov/pub/data/noaa/2018
整理数据
下载后的所有文件都为xxx.gz格式。如果在下载过程中出现意外终止的情况,需删除最后一个不完整文件。否则继续操作会报不必要的错误。查看xxx.gz文件使用“ zcat xxx.gz |less ”翻页查看
将所有的xxx.gz文件内容复制到一个txt中。
方法:zcat *.gz > sample.txt
此时生成一个sample.txt文件。同样使用“cat sample.txt |less”查看。内容格式如下:

将sample.txt文件上传到hadoop hdfs文件服务器的“/user/hadoop”文件夹下。
方法:hadoop fs -put sample.txt /user/hadoop
查看上传的文件: hadoop fs -ls /user/hadoop
代码部分
1.MaxTemperature部分
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
public class MaxTemperature extends Configured implements Tool {
public static void main(String[] args) throws Exception {
if (args.length != 2) {
System.err
.println("Usage: MaxTemperature );
System.exit(-1);
}
Configuration conf = new Configuration();
conf.set("mapred.jar", "MaxTemperature.jar");
Job job = Job.getInstance(conf);
job.setJarByClass(MaxTemperature.class);
job.setJobName("Max temperature");
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setMapperClass(MaxTemperatureMapper.class);
job.setReducerClass(MaxTemperatureReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
@Override
public int run(String[] arg0) throws Exception {
// TODO Auto-generated method stub
return 0;
}
}
2.MaxTemperatureMapper 部分
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class MaxTemperatureMapper extends
Mapper<LongWritable, Text, Text, IntWritable> {
private static final int MISSING = 9999;
@Override
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
String data = line.substring(15, 21);
int airTemperature;
if (line.charAt(87) == '+') {
airTemperature = Integer.parseInt(line.substring(88, 92));
} else {
airTemperature = Integer.parseInt(line.substring(87, 92));
}
String quality = line.substring(92, 93);
if (airTemperature != MISSING && quality.matches("[01459]")) {
context.write(new Text(data), new IntWritable(airTemperature));
}
}
}
3.MaxTemperatureReducer 部分
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class MaxTemperatureReducer extends
Reducer<Text, IntWritable, Text, IntWritable> {
@Override
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int maxValue = Integer.MIN_VALUE;
for (IntWritable value : values) {
maxValue = Math.max(maxValue, value.get());
}
context.write(key, new IntWritable(maxValue));
}
}
三个java文件创建好为以下样式

编译程序
设置classpath路径:
修改hadoop\etc\hadoop文件夹中的hadoop-evn.sh文件
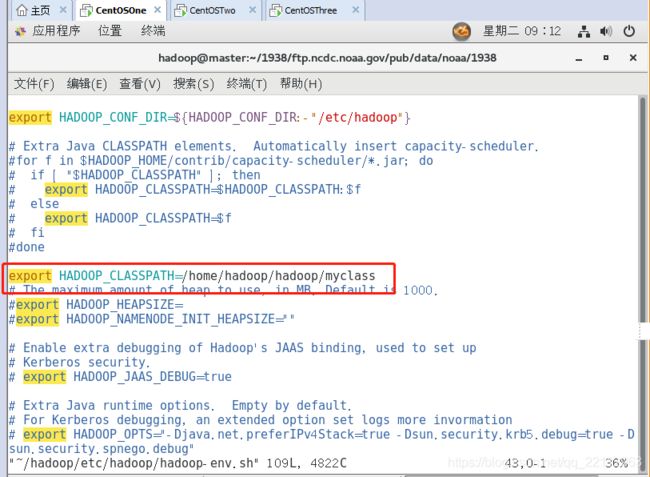
编译程序使用javac本地编辑。
方法:javac -classpath $HADOOP_HOME/share/hadoop/common/hadoop-common-2.8.4.jar: $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.8.4.jar: $HADOOP_HOME/share/hadoop/common/lib/commons-cli-1.2.jar *.java
如下:

编译后回生成三个.class文件

将三个文件打包为一个jar文件
方法:jar cvf ./MaxTemperature.jar ./*.class

此时生成了一个MaxTemperature.jar文件,然后删除上一步生成的三个.class文件。
运行程序
最后一步运行程序,前提是保证前面没有错误的情况下进行。
方法: hadoop jar MaxTemperature.jar MaxTemperature /user/hadoop/sample.txt /user/hadoop/out3
解释:用hadoop jar 方法运行 MaxTemperature.jar ,执行主类为MaxTemperature.jar中的MaxTemperature类,
数据源为/user/hadoop/sample.txt , 执行输出到/user/hadoop/out3中。
执行完成后用“hadoop fs -ls /user/hadoop”查询是否有out3文件夹

查询out3文件夹

如果最后out3输出文件夹中有这样的文件就说明运行成功了。如果文件夹为空则运行失败。
文件part-r-00000就是本次计算的结果。
查看结果
方法:hadoop fs -cat /user/hadoop/out3/part-r-00000

成功输出结果。