02_05 python机器学习_第二章监督学习_决策树
第二章监督学习_决策树
01 什么是决策树
就是没完没了的问,直到问出答案
书上例子:
import mglearn
import matplotlib.pyplot as plt
mglearn.plots.plot_animal_tree()
plt.show()
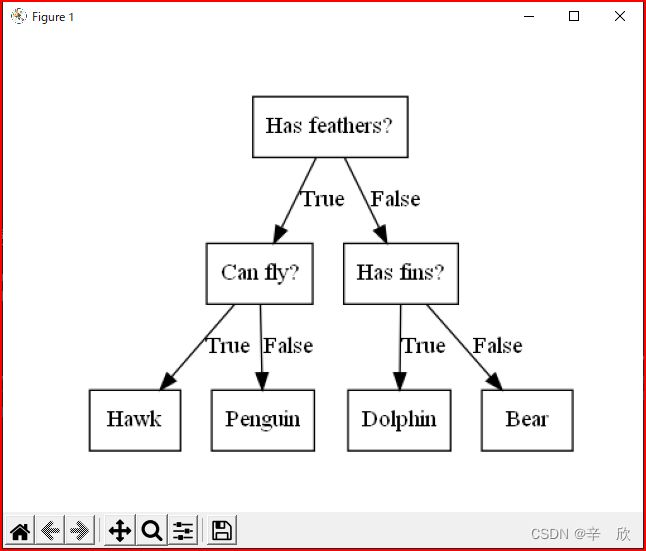 这里不得不吐槽一下.就不能多写几句话,为了能运行出图像调查了半小时.
这里不得不吐槽一下.就不能多写几句话,为了能运行出图像调查了半小时.
中间的坎坷就不展示了,直接上正确配置手顺.
- 代码原封不动copy
- 去官网下载Graphviz, Graphviz相关百度说明. 软件不到5M. 开源软件, 趋势扫描无毒.
别问我为啥要下软件? 我也想知道… 一运行就报错找不到包,pip安装后有找不到dot,一顿查发现python就是个调用,成像需要graphviz软件来绘图. - 安装时候注意了: 用户path里必须配置 graphviz的bin, 系统path里必须加入 graphviz下bin文件夹中的dot. 别问为什么,不想浪费时间照着配置就行.
- python pip install graphviz 安装python调用然间的三方包.
- 至此,你可以成功运行代码了…
上图中黑色箭头指向的"问题"或"答案"称作叶节点
02 决策数的实现原理
决策树的原理用图片描述比用语言来的更直接.
书上的例子不错,可惜只给了图,没说怎么画出来的,如果是一直跟着我学习,相信你也能猜到mglearn里可能有现成的绘图范例.
对于刚接触的领域,要抱着学习的态度去揣摩书里的每一句话水平才可能有提高.
# 决策树原理范例
import mglearn
import matplotlib.pyplot as plt
mglearn.plots.plot_tree_progressive()
plt.show()
首先说一下数据样本.
100个数据样本, 共分2类,每类50个, 每个数据样本有2个数据特征,即(100,2)的结构.
 决策树开始前的准备
决策树开始前的准备
这里先不说决策边界怎么算出来的,因为看到目前我也不知道,先留着问题往下学.
我的理解:
- 模型首先会在数据样本中找到一个位置,使其中的一类数据尽可能的多.
- 因为是作用在数据样本也就是1维即X轴上,因此线与X轴平行.
我的理解
疑问:为啥不先用特征分类? 我的理解:
分类一定是从大分类开始,大分类可以将某一类的对象尽可能多的汇聚到一起,然后再细化就容易了.先从最小单位细化分类会让问题处理起来很麻烦.
数据样本中种类就是大分类, 数据特征就是小分类. 疑问:数据样本绘图中,X轴也是数据特征,大分类为啥横着画? 我的理解:
这个可能需要抛开第一张图, 因该用numpy.array()来看待, 把数据要想象成矩阵图, 横轴代表样本,纵轴代表特征.

下图是深度1划分
- 深度1的决策边界为啥与Y轴平行?
我的理解
关于数据种类(大分类)的分类我们已经做完了.接下来的划分只能按照(小分类)特征来划分.特征位于Y轴,因此与Y轴平行.
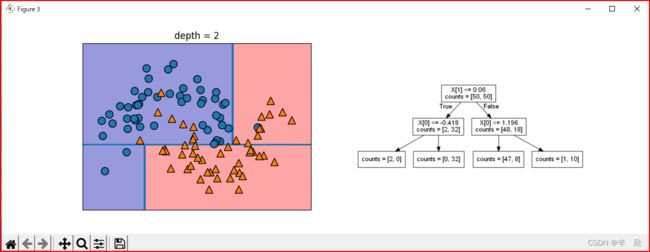
下图是最大深度划分:
疑问: 分类问题已经在第一次做完了,怎么又出现了横轴方向的决策边界?
我的理解
第一次分类只是为了尽可能多的汇聚各种类数据,当数据划分逐渐细化后,会发现仅仅靠特征已经无法再继续划分,这时如果不是纯点(完全都是一类的数据)的时候,模型会尝试再从分类上区分数据,然后再用特征区分,就这样递归下去,直到把数据都划分完.
 上面删除部分是我在学习过程中产生的问题,理解些偏差,需要重新整理.
上面删除部分是我在学习过程中产生的问题,理解些偏差,需要重新整理.
汇总一下其实就是一个问题, 决策边界的产生规则.
- 决策边界的每一次产生因该都是调用相同的逻辑,只不过大于1的深度需要递归调用.
- 决策边界的每一次划分都是以数据特征来划分,目的就是尽可能多的决策出这一次的纯点(完全是某一类数据,没有夹杂其它类别)
- 只有产生不纯点的时候,才可能产生下一次的决策
- 不用纠结决策边界为啥一会X轴一会Y轴, 完全由算法和特征数据来决定样本的边界如何画
03 训练树模型的得分如何
# 绘图
import matplotlib.pyplot as plt
# 数据样本
from sklearn.datasets import load_breast_cancer
# 数据分离
from sklearn.model_selection import train_test_split
# 决策树模型 预剪枝
from sklearn.tree import DecisionTreeClassifier
# 获得数据
cancer = load_breast_cancer()
# 拆分数据
X_train, X_test, y_train, y_test = train_test_split(
cancer.data, cancer.target, random_state=42)
# 使用默认决策树
tree_default = DecisionTreeClassifier()
# 使用深度为4的决策树
tree_deep4 = DecisionTreeClassifier(max_depth=4, random_state=0)
# 喂数据
tree_default.fit(X_train, y_train)
tree_deep4.fit(X_train, y_train)
# 记录各模型得分
tree_default_train_score = tree_default.score(X_train, y_train)
tree_default_test_score = tree_default.score(X_test, y_test)
tree_deep4_train_score = tree_deep4.score(X_train, y_train)
tree_deep4_test_score = tree_deep4.score(X_test, y_test)
# 绘制图片
plt.plot(0, tree_default_train_score, marker='^', label="default train")
plt.plot(0, tree_default_test_score, marker='^', label="default test")
plt.plot(0, tree_deep4_train_score, marker='^', label="deep4 train")
plt.plot(0, tree_deep4_test_score, marker='^', label="deep4 test")
# 绘制图标
plt.legend(loc='best')
# 显示画布
plt.show()

图中可以看出来,默认情况下的训练精度已经达到恐怖的100%,这么强的匹配可能会造成过拟合,通过该观察默认模型的训练得分值也验证了这一想法.
使用深度为4的决策树采样时,虽然损失了一部分训练精度,但是模型的泛化能力缺提高了不少.
这里提到的深度就是模型需要决策几次,对于复杂的数据而言想要得到纯数据,可能要决策N次才行,这也是决策树模型的默认设置.但是通常情况下如果完全划分每类数据的决策边界,势必要加大计算量,而且泛化能力也不好.看看我们第一个例子中的最后一个图就会发现,为了区别中间范围的个别点,模型绘制了还多区域,有些几乎再y轴重合的点,也硬性的划分出了界限,为了个别点影响整个模型的效率的算法一般情况下我们是不会采用的.
对于复杂数据的决策树是有方案优化的:
- 在事情变得恶化前及时止损的方法叫预剪枝, 理解起来就是觉得差不多这样就行了,别再细分了.
- 先细化再分类筛选的方法叫后剪枝,理解起来就是该干的活都给我干完喽,我最后决定要哪些.
从表面上看我感觉预剪枝要计算的快一些.
实例中是用决策树模型属于预剪枝,书上说python没有后剪枝模型,这个先不去研究,有预剪枝就先学预剪枝.
04 预剪枝决策树模型 DecisionTreeClassifier,DecisionTreeRegressor
| 模型名 | 位置 | 参数 | 说明 |
|---|---|---|---|
| DecisionTreeClassifier | from sklearn.tree import DecisionTreeClassifier | max_depth | max_depth越大训练模型越精确,泛化能力越弱 |
| DecisionTreeRegressor | from sklearn.tree import DecisionTreeRegressor | max_depth | max_depth越大训练模型越精确,泛化能力越弱 |
05 分析决策树
# 分析决策树
# 绘图
import matplotlib.pyplot as plt
# 数据样本
from sklearn.datasets import load_breast_cancer
# 数据分离
from sklearn.model_selection import train_test_split
# 决策树模型 预剪枝
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import export_graphviz
dot_file = r"D:\999_Temp\999_Tmp\tree.dot"
pdf_file = r"D:\999_Temp\999_Tmp\tree.dot"
# 获得数据
cancer = load_breast_cancer()
# 拆分数据
X_train, X_test, y_train, y_test = train_test_split(
cancer.data, cancer.target, random_state=42)
# 使用默认决策树
tree_default = DecisionTreeClassifier()
# 喂数据
tree_default.fit(X_train, y_train)
# 生成分析报告
# out_file
# 做成的分析报告名
# class_names
# 决策各分支的名, 决策分支个数应当与数据样本的个数一样
# feature_names
# 特征名
# impurity
# True表示显示各个决策含有的杂志率
# filled
# 填充颜色,用于演示的话建议打开能好看点.
export_graphviz(tree_default, out_file=dot_file, class_names=["malignat", "begin"],
feature_names=cancer.feature_names, impurity=True, filled=True)
###############
# 用python查看dot文件方法
###############
# 思路: dot文件转存成PDf文件
import graphviz
with open(dot_file) as f:
dot_grap = f.read()
# 读取dot并转换
# 因为这个不是重点,所以不深入研究,会用就行
gh = graphviz.Source(dot_grap)
gh.render(pdf_file)
效果图: 分析报告中可以看出每一模型决策的条件

- 为什么我的运行结果没有图
仔细看代码可以知道程序只是生成了一个tree.dot的文件, 这个会放在你的工程目录的根目录中(也可以自定义目录) ,如果只是学习的话,我建议安装一个vscode,这个万能IED插件它的集成度很高,插件也很丰富,用vscode打开.dot文件,它就会提示你安装插件.
06 决策树如何解决多分类
# 分析决策树 处理多分类
#######
# 数据样本
#######
# In[30]: lr.data.shape
# Out[30]: (150, 4)
# In[31]: lr.target_names
# Out[31]: array(['setosa', 'versicolor', 'virginica'], dtype='
from sklearn.datasets import load_iris
#######
# 决策树算法模型 预剪枝
#######
from sklearn.tree import DecisionTreeClassifier
#######
# 数据转换
#######
# 将算法数据导出绘图数据
from sklearn.tree import export_graphviz
# 绘图数据编辑
import graphviz
#######
# 内存
#######
# 使用内存来完成算法与绘图的转换
from io import StringIO
#######
# 图像处理
#######
# 读入图片
from imageio import imread
#######
# 绘图
#######
# 显示图片
import matplotlib.pyplot as plt
# 转话后数据的保存位置
fout = r"D:\999_Temp\999_Tmp\tree_iris"
# 获得数据
lr = load_iris()
# 使用默认决策树
tree_default = DecisionTreeClassifier()
# 喂数据
tree_default.fit(lr.data, lr.target)
# 生成分析报告
# 算法数据写入到out_file接口中
# out_file
# 做成的分析报告名
# class_names
# 决策各分支的名, 决策分支个数应当与数据样本的个数一样
# feature_names
# 特征名
# impurity
# True表示显示各个决策含有的杂志率
# filled
# 填充颜色,用于演示的话建议打开能好看点.
dot_data = StringIO()
export_graphviz(tree_default, out_file=dot_data, class_names=["1", "2", '3'],
feature_names=lr.feature_names, impurity=True, filled=True)
data = dot_data.getvalue()
# 格式话算法数据
graph = graphviz.Source(data, format="png")
# 导出格式化后的值
graph.render(fout)
# 读入图片数据,设置到当前画布中
plt.imshow(imread(fout + ".png"))
# 显示画布
plt.show()
# 画布中有多个绘图的时候像下面这样设置就可以
# plt.figure() # 画布初始化
# ax = plt.gca() # GCF: Get Current Figure" GCA: "Get Current Axes"
# ax.imshow(imread(fout + ".png"))
# plt.show()

- 可以看出来凡是得到纯点的"叶节点"就不会在继续决策下去了.只有非纯点才能继续向下决策(这也验证了[02 决策树的实现原理中出现的问题],算法上一定会以最大纯数据的叶节点为目标来拆分)
- 数据模型共有3类,绘图是指定了填充色.上图中每一类都有一种类型的颜色,很容辨识
- 即使是3分类,每次的决策支依然只有2个分支
07 决策树模型属性_特征重要性(feature_importance_)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
lr = load_iris()
tree = DecisionTreeClassifier().fit(lr.data, lr.target)
n_feature = len(lr.feature_names)
# 在Y轴上显示 指定宽度的bar
# 第一个参数:
# 参数的Y轴位置
# 第二参数:
# bar的宽度
plt.barh(range(n_feature), tree.feature_importances_, align='center')
# 在Y中指定位置加label
plt.yticks(np.arange(n_feature), lr.feature_names)
plt.show()
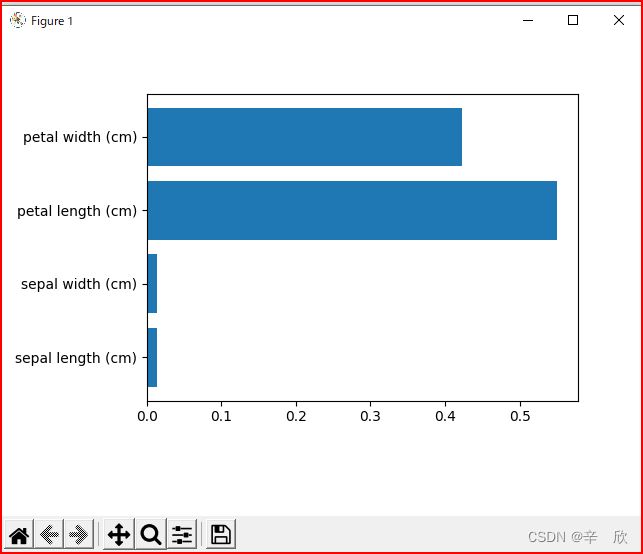
我的测试结果与书中的不太一样.虽然鸢尾花的最重要特征是[petal length]但是第一次的决策并不是用这个划分的.
因此,数据的特征重要性仅是作为决策的参考,最终还是要看哪一种决策产生的分类数据最多.
08 决策树对测试数据的预测能力如何
# 决策树对测试数据的预测能力如何
# 思路:
# 1.将数据样以2000年为界限划分成训练数据和测试数据
# 2.用训练数据分别训练决策树模型和线性回归模型
# 3.为确认模型泛化能力,将含有训练数据和测试数据的完整数据样本应用于数据模型
# 4.用直接计算而不是模型计算的结果先绘制出预想图形
# 5.分别将两个模型计算结果绘制成图形
# 6.分别比较两个模型的预测结果和实际图形的差别
# 即:
# module(X_train, 10^y_train).predit(X).exp() == y
# 数据表单处理库
import pandas as pd
# 多维数组处理库
import numpy as np
# 绘图库
import matplotlib.pyplot as plt
# 机器学习线性回归模型
from sklearn.linear_model import LinearRegression
# 机器学习决策树模型
from sklearn.tree import DecisionTreeRegressor
###################
# 数据准备
###################
# 数据样本位置
csv_data = r'D:\001_Work\002_DevelopSource\Python_Project\python_numpy\.venv\Lib\site-packages\mglearn\data\ram_price.csv'
# csv -> array
# In [5]: ram_prices
# Out[5]:
# Unnamed: 0 date price
# 0 0 1957.00 4.110418e+08
# 1 1 1959.00 6.794772e+07
# ......
ram_prices = pd.read_csv(csv_data)
# 数据拆分
data_train = ram_prices[ram_prices.date < 2000]
data_test = ram_prices[ram_prices.date >= 2000]
# 取得数据样本种关于日期的那一列的值
dates = data_train.date
# 将数组新追加一个维度, 使一维数组变成二维数组
# 将原有数据的任何一个数据都放到新维度数组的一维位置
# In [19]: data_train.date[:3]
# Out[19]:
# 0 1957.0
# 1 1959.0
# 2 1960.0
# In[20]: data_train.date[:, np.newaxis][:3]
# Out[20]:
# array([[1957.],
# [1959.],
# [1960.]])
X_train = dates[:, np.newaxis]
# np.log 幂运算 底数为10
# 求 a^b 的运算叫乘方运算,运算的结果叫幂 a为底数, b为真数
y_train = np.log(data_train.price)
###################
# 建模
###################
# 决策树建模
tree = DecisionTreeRegressor().fit(X_train, y_train)
# 线性回归模型建模
linear = LinearRegression().fit(X_train, y_train)
###################
# 模型验证
###################
# 将数据样本中的所有时间数据取出,重新格式化成二维数组,
# 将时间数据的每个数据重置在新数据的一维位置
X_all = ram_prices.date[:, np.newaxis]
# 记录通过训练数据做成的决策树模型对真个数据样本的预测得分
pred_tree = tree.predict(X_all)
# 同理,纪律线性模型的预测得分
pred_lr = linear.predict(X_all)
# 将模型预测出来的得分做开方运算, 为了确认能否得到数据样本中相同的价格
# a^b 中,求 a 的逆运算叫开方运算 ,求 b 的逆运算叫对数运算。
price_tree = np.exp(pred_tree)
price_lr = np.exp(pred_lr)
# semilogy函数是对y坐标点取常用对数(底为10)后生成的对数坐标函数。
# 因为模型预测值都是幂运算结果,因此绘图时也是用幂运算结果表示才更能看清结果
# semilogy 帮助文档:
# https://ww2.mathworks.cn/help/matlab/ref/semilogx.html?s_tid=srchtitle_semilogx_1
# 使用原始数据样本2000年以前的数据不通过决策树模型直接直接算出结果并绘制线的前半段
plt.semilogy(data_train.date, data_train.price, label='Train data')
# 使用原始数据样本2000年以后的数据不通过决策树模型直接直接算出结果并绘制线的后半段
plt.semilogy(data_test.date, data_test.price, label='Train test')
# 用2000年以前数据训练的决策树模型尝试分析数据全体并绘制完整线
plt.semilogy(ram_prices.date, price_tree, label='Tree prediction')
# 同上,使用线性模型来绘制
plt.semilogy(ram_prices.date, price_lr, label='Linear prediction')
# 绘制图标
plt.legend()
# 显示画布
plt.show()

这个图怎么看,按照顺序说一下:
- train data: 表示2000前的数据样本不通过训练模型直接计算结果
- train test: 表示2000后的数据样本不通过训练模型直接计算结果
- tree prediction: 表示完整数据的决策树训练模型计算结果
- linear prediction: 表示完整的线性模型训练模型计算结果
train data看不到的原因在于决策树对于训练数据是100%匹配,后面显示的线把前面的覆盖了.
图中可以直观看出来的内容是: 对于决策树训练模型,针对未参加训练的测试数据样本,几乎没什么预测能力. 我猜想决策树模型适合那些需要精确匹配过往数据的需要而创建的.
| 模型 | 建模数据匹配度 | 测试数据泛化能力 |
|---|---|---|
| 决策树模型 | 100%匹配 | 0% 没有预测能力 |
| 线性模型 | <100%匹配 | >0% 有一定的预测能力 |
09 决策树总结
优点:
- 决策树因为能完美匹配训练数据,非常适合过往数据的分析,同时也能比较好的再现数据的走势曲线.
缺点:
- 因为100%的匹配程度,因此存在过拟合,所以不适合训练数据以外的数据的预测