AVOD-代码理解系列(四)
AVOD-代码理解(四)
前段时间博主准备开题去了,现在回来继续更新。拖了好长一段时间,还是不要半途而废。最近发现AVOD代码的一些小trick还是存在一些不理解之处,如果哪位朋友懂了可以讨论一下,我会把一些暂时不能明白的地方指出来。最近有个同事一直催促我跟他一起仔细研读那些小tricks的地方,等哪天我把课题的想法与思路再捋捋后再研究。
RPN->NMS
上一篇我们说到使用全连接层进行物体与背景判定,并生成bbox的6个回归值。接下来是整个网络结构的这一部分(不包括最后的部分):

代码块如下:
#并没有用.就是一个可视化、可以自己选择是否可视化
with tf.variable_scope('histograms_feature_extractor'):
with tf.variable_scope('bev_vgg'):
for end_point in self.bev_end_points:
tf.summary.histogram(
end_point, self.bev_end_points[end_point])
with tf.variable_scope('img_vgg'):
for end_point in self.img_end_points:
tf.summary.histogram(
end_point, self.img_end_points[end_point])
with tf.variable_scope('histograms_rpn'):
with tf.variable_scope('anchor_predictor'):
fc_layers = [cls_fc6, cls_fc7, cls_fc8, objectness,
reg_fc6, reg_fc7, reg_fc8, offsets]
for fc_layer in fc_layers:
# fix the name to avoid tf warnings
tf.summary.histogram(fc_layer.name.replace(':', '_'),
fc_layer)
# Return the proposals
with tf.variable_scope('proposals'):
#手动输入的?
anchors = self.placeholders[self.PL_ANCHORS]
# Decode anchor regression offsets
with tf.variable_scope('decoding'):
#得到回归后的(x,y,z,dx,dy,dz).由最初的输入变为回归的值
regressed_anchors = anchor_encoder.offset_to_anchor(
anchors, offsets)
with tf.variable_scope('bev_projection'):
#[[-40,40],[0,70]]
#返回bev_box_corner,bev_box_corners_norm
_, bev_proposal_boxes_norm = anchor_projector.project_to_bev(
regressed_anchors, self._bev_extents)
with tf.variable_scope('softmax'):
objectness_softmax = tf.nn.softmax(objectness)
with tf.variable_scope('nms'):
objectness_scores = objectness_softmax[:, 1]
# Do NMS on regressed anchors
#实现极大值抑制non max suppression,
# 其中boxes是不同boxes的坐标,scores是不同boxes预测的分数,max_boxes是保留的最大box的个数。
# iou_threshold是一个阈值,去掉大于这个阈值的所有boxes?。
#_nms_size=1024,0.8
#筛选出来的序数
top_indices = tf.image.non_max_suppression(
bev_proposal_boxes_norm, objectness_scores,
max_output_size=self._nms_size,
iou_threshold=self._nms_iou_thresh)
#选择筛选后的anchors和objectness
top_anchors = tf.gather(regressed_anchors, top_indices)
top_objectness_softmax = tf.gather(objectness_scores,
top_indices)
# top_offsets = tf.gather(offsets, top_indices)
# top_objectness = tf.gather(objectness, top_indices)
在上诉部分,regressed_anchors = anchor_encoder.offset_to_anchor(anchors, offsets)的解释如下:
def offset_to_anchor(anchors, offsets):
"""Decodes the anchor regression predictions with the
anchor.
这一部分的主要工作就是根据公式计算回归的anchor的参数值,包括[x,y,z,dx,dy,dz]
Args:
anchors: A numpy array or a tensor of shape [N, 6]
representing the generated anchors.
offsets: A numpy array or a tensor of shape
[N, 6] containing the predicted offsets in the
anchor format [x, y, z, dim_x, dim_y, dim_z].
Returns:
anchors: A numpy array of shape [N, 6]
representing the predicted anchor boxes.
"""
#确保anchors的shape是n*6
fc.check_anchor_format(anchors)
fc.check_anchor_format(offsets)
# x = dx * dim_x + x_anch
x_pred = (offsets[:, 0] * anchors[:, 3]) + anchors[:, 0]
# y = dy * dim_y + y_anch
y_pred = (offsets[:, 1] * anchors[:, 4]) + anchors[:, 1]
# z = dz * dim_z + z_anch
z_pred = (offsets[:, 2] * anchors[:, 5]) + anchors[:, 2]
tensor_format = isinstance(anchors, tf.Tensor)
if tensor_format:
# dim_x = exp(log(dim_x) + dx)
dx_pred = tf.exp(tf.log(anchors[:, 3]) + offsets[:, 3])
# dim_y = exp(log(dim_y) + dy)
dy_pred = tf.exp(tf.log(anchors[:, 4]) + offsets[:, 4])
# dim_z = exp(log(dim_z) + dz)
dz_pred = tf.exp(tf.log(anchors[:, 5]) + offsets[:, 5])
anchors = tf.stack((x_pred,
y_pred,
z_pred,
dx_pred,
dy_pred,
dz_pred), axis=1)
else:
dx_pred = np.exp(np.log(anchors[:, 3]) + offsets[:, 3])
dy_pred = np.exp(np.log(anchors[:, 4]) + offsets[:, 4])
dz_pred = np.exp(np.log(anchors[:, 5]) + offsets[:, 5])
anchors = np.stack((x_pred,
y_pred,
z_pred,
dx_pred,
dy_pred,
dz_pred), axis=1)
return anchors
前文的 _, bev_proposal_boxes_norm = anchor_projector.project_to_bev( regressed_anchors, self._bev_extents)部分的解释如下:
def project_to_bev(anchors, bev_extents):
"""
Projects an array of 3D anchors into bird's eye view
在查看kitti的数据集后,我发现它的数据采集系统的坐标系是这样的:
Camera:x=right,y=down,z=forward
Velodyne:x=forward,y=left,z=up
GPS/IMU:x=fprward,y=left,z=up
那就是说明实际上是在camera坐标下进行的,所以鸟瞰图上实际就是xz轴。之后再细看,如何进行的点云鸟瞰图投影!
Args:
anchors: list of anchors in anchor format (N x 6):
N x [x, y, z, dim_x, dim_y, dim_z],
can be a numpy array or tensor
bev_extents: xz extents of the 3d area
[[min_x, max_x], [min_z, max_z]]
Returns:
box_corners_norm: corners as a percentage of the map size, in the
format N x [x1, y1, x2, y2]. Origin is the top left corner(原点是左上角)
"""
#[[-40,40],[0,70]]
tensor_format = isinstance(anchors, tf.Tensor)
if not tensor_format:
anchors = np.asarray(anchors)
#这里的鸟瞰图坐标是xz!
#x,y,z是框的中心点,dx,dy,dz则分别是宽,高,长(以人在车里的视角看)!
x = anchors[:, 0]
z = anchors[:, 2]
half_dim_x = anchors[:, 3] / 2.0
half_dim_z = anchors[:, 5] / 2.0
# Calculate extent ranges
#[[-40,40],[0,70]]。z的方向才是车前方。所以只有正数。在观察kitti的数据时可以看到应该是只涉及前方的物
#体,然而现有的车载感知系统实际上是车周围除开某个盲区都有。
bev_x_extents_min = bev_extents[0][0]
bev_z_extents_min = bev_extents[1][0]
bev_x_extents_max = bev_extents[0][1]
bev_z_extents_max = bev_extents[1][1]
#80
bev_x_extents_range = bev_x_extents_max - bev_x_extents_min
#70
bev_z_extents_range = bev_z_extents_max - bev_z_extents_min
# 2D corners (top left, bottom right)
#左上角与右下角
x1 = x - half_dim_x
x2 = x + half_dim_x
# Flip z co-ordinates (origin changes from bottom left to top left)
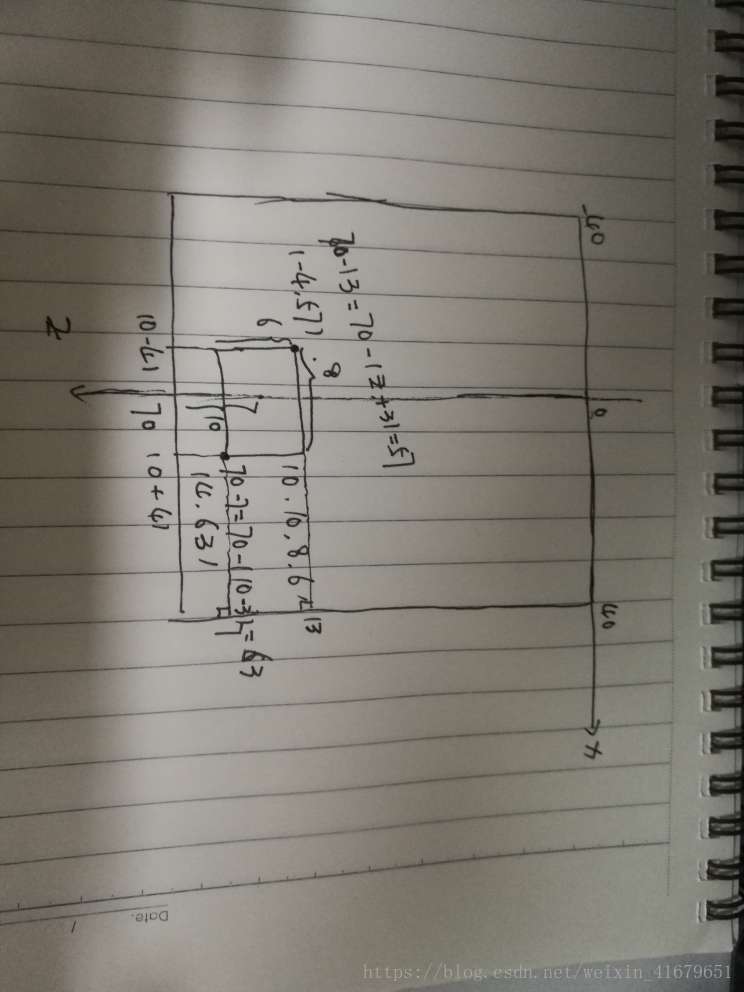
#翻转z轴,原点从左下角变为左上角。这个地方为了防止有人不能理解究竟是怎么回事,我在下面画了一张
#草图,可以加深理解。
z1 = bev_z_extents_max - (z + half_dim_z)
z2 = bev_z_extents_max - (z - half_dim_z)
# Stack into (N x 4)
if tensor_format:
bev_box_corners = tf.stack([x1, z1, x2, z2], axis=1)
else:
bev_box_corners = np.stack([x1, z1, x2, z2], axis=1)
# Convert from original xz into bev xz, origin moves to top left
#[-40,0,40,70]
bev_extents_min_tiled = [bev_x_extents_min, bev_z_extents_min,
bev_x_extents_min, bev_z_extents_min]
bev_box_corners = bev_box_corners - bev_extents_min_tiled
# Calculate normalized box corners for ROI pooling
#计算ROI池的标准化方框角
extents_tiled = [bev_x_extents_range, bev_z_extents_range,
bev_x_extents_range, bev_z_extents_range]
#标准化
bev_box_corners_norm = bev_box_corners / extents_tiled
#[x1,z1,x2,z2],[]
return bev_box_corners, bev_box_corners_norm
anchor投影计算: