leveldb代码阅读笔记(一)
leveldb代码阅读笔记
above all
leveldb是一个单机的键值存储的内存数据库,其内部使用了 LSM tree 作为底层存储结构,支持多版本数据控制,代码设计巧妙且简洁高效,十分值得作为LSM tree的实践范本进行学习。
剩下的你只需要知道他的作者是Jeff Dean,那么也就知道阅读这个存储系统源码的价值了。
代码目录
阅读指南:各文件夹下的文件功能

功能特性
/doc 文件夹下面的 .md 文件介绍了在开始看源码前的你需要了解的各种预备知识,index.md具体介绍了leveldb从功能层面上的各种使用特性,推荐阅读。这里也放一个从网上看到的翻译版:
https://zhuanlan.zhihu.com/p/203595407
整体架构

- lock:DB锁文件
- current:指向当前版本 manifest
- manifest:SSTable管理文件
- ldb:DB实例描述文件
- log:log文件
- sst:SSTable文件
API
Open
DB::Open
Open 函数用来打开一个 DB 实例,若对应名称的数据库实例已存在,则从文件中恢复该 DB 实例原先的状态,若否,则创建新的 DB 实例。函数传入三个参数,options中传入打开DB实例的各种参数,而dbname对应数据库唯一的名字,dbptr 保存回传的数据库实例指针。Open 函数首先调用 Recover 函数,检查当前名称的数据库实例是否已存在,或者仍存在相关的数据文件。若当前数据库实例并非在使用中,无论之前的文件是否存在,都需要建立新的 .log 文件以及新的 memtable 实例。
Status DB::Open(const Options& options, const std::string& dbname, DB** dbptr) {
*dbptr = nullptr;
DBImpl* impl = new DBImpl(options, dbname); //根据Options中的对象参数创建新的DB实例
impl->mutex_.Lock();
VersionEdit edit;
// Recover handles create_if_missing, error_if_exists
bool save_manifest = false;
Status s = impl->Recover(&edit, &save_manifest); // 检查当前DB实例是否之前就存在,如果存在,从旧文件中恢复
if (s.ok() && impl->mem_ == nullptr) { // 创建新的log文件以及memtable对象
// Create new log and a corresponding memtable.
uint64_t new_log_number = impl->versions_->NewFileNumber();
WritableFile* lfile;
s = options.env->NewWritableFile(LogFileName(dbname, new_log_number),
&lfile);
if (s.ok()) {
edit.SetLogNumber(new_log_number);
impl->logfile_ = lfile;
impl->logfile_number_ = new_log_number;
impl->log_ = new log::Writer(lfile);
impl->mem_ = new MemTable(impl->internal_comparator_);
impl->mem_->Ref();
}
}
if (s.ok() && save_manifest) { //设置新的日志号,在实例之前就存在的情况下执行
edit.SetPrevLogNumber(0); // No older logs needed after recovery.
edit.SetLogNumber(impl->logfile_number_);
s = impl->versions_->LogAndApply(&edit, &impl->mutex_);
}
if (s.ok()) { //删除不需要文件,检查是否需要进行compact流程
impl->RemoveObsoleteFiles();
impl->MaybeScheduleCompaction();
}
impl->mutex_.Unlock();
if (s.ok()) {
assert(impl->mem_ != nullptr);
*dbptr = impl;
} else {
delete impl;
}
return s;
}
Recover
LevelDB包含多种不同的数据文件,包括日志文件,manifest管理文件,数据文件等等。Recover函数的流程分为三个部分,第一部分检测数据库是存在,如果数据库实例是第一次创建,需要创建这些文件,并进行必要的初始化。否则,将读入这些文件,在内存中依据这些文件创建DB实例,第二部分是根据对多版本并发控制的需要生成对应的版本管理对象 VersionSet,Version;第三部分的代码主要负责检测是否有已经写入但是尚未执行的log日志存在,对这些存在遗漏的log日志进行处理。
-
NewDB
NewDB 负责创建对应 VersionEdit 并添加到新的 mainfest 文件,由manifest文件管理不同 level 的 sstable 。
-
VersionSet::Recover
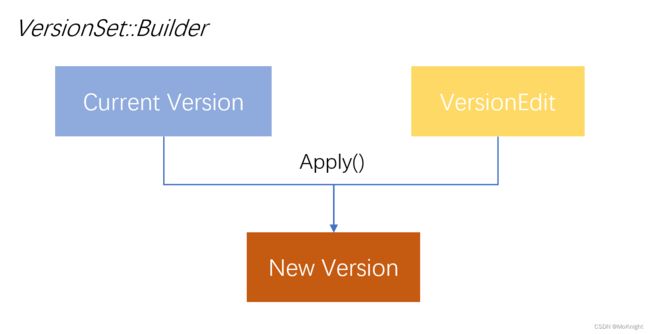
当manifest文件复原之后,开始恢复 VersionSet和Version的对象,利用Builder对象合并已有的VersionEdit,创建出一个最新的 Version 对象并添加到VersionSet中作为 current_ 对象。
-
RecoverLogFile
针对尚已记录到 log 中但未执行的日志项,RecoverLogFile 将log 中的日志项进行执行并添加到 memtable 中。
Get
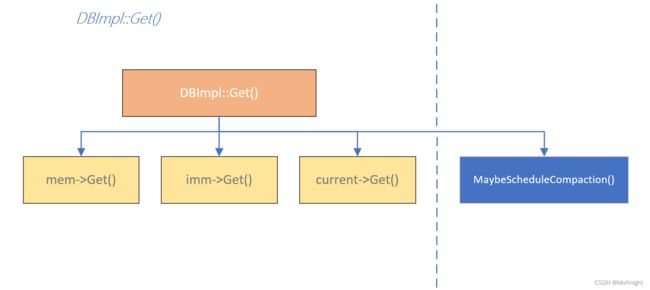
DBImpl::Get
LevelDB 的 Get 操作可以细分为对 Memtable 和 SSTable 两部分分别的 Get,其中 Memtable 有两种形式的存在,分别是 mem_ 和 imm_ ,即可以修改的 memtable 和只读的 memtable ,但他们的 Get 操作是一样的。
MemTable Get
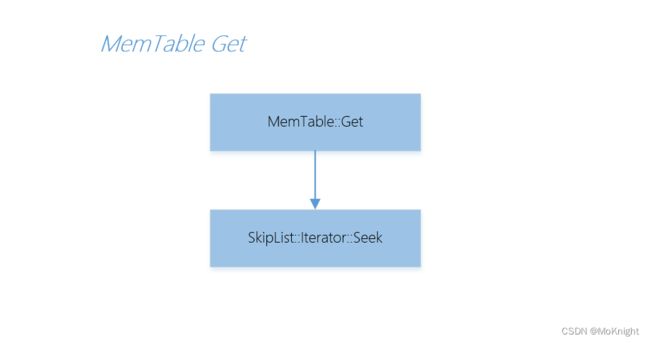
MemTable::Get
memtable 的 Get 流程即是对底层存储结构 SkipList 对象的 Seek 操作,如果能在 memtable 中找到对应的数据,也需要判断其对应的类型后再返回,因为在 memtable 上存储的数据条目可能有已删除的标记(kTypeDeletion),这样的情况下无需任何返回。
关于 SkipList d的 seek 操作会在 SkipList 的相关部分展示。
SSTable Get
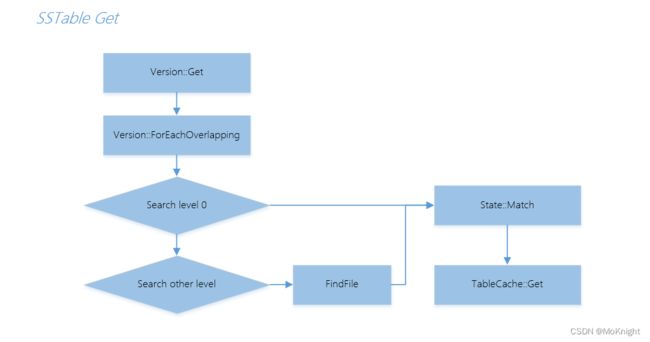
LevelDB 的 SSTable 共有7层,Get的步骤是首先检测 level 0 的 SSTable,之后检测其他 level,比对目标 key 和文件 key 的范围,将包含 key 的对应的 SSTable 文件传入 State::Match 进行比对,State::Match 的核心代码是关于将 sst 文件读入Cache,然后检测其中 key 对应的 value。

-
TableCache::FindTable
当确认了包含 key 值的目标 SSTable 文件,就需要读取文件数据到内存中,由于 LevelDB 拥有缓存区,并不会将使用的数据立即释放,因此在将对应的 SSTable 再次读入内存之前,首先在内存中查找对应的 Table 是否存在,否则从 SSTable 中读入,这样可以避免读入冗余数据:
Status TableCache::FindTable(uint64_t file_number, uint64_t file_size, Cache::Handle** handle) { Status s; char buf[sizeof(file_number)]; EncodeFixed64(buf, file_number); Slice key(buf, sizeof(buf)); *handle = cache_->Lookup(key); if (*handle == nullptr) { std::string fname = TableFileName(dbname_, file_number); RandomAccessFile* file = nullptr; Table* table = nullptr; s = env_->NewRandomAccessFile(fname, &file); if (!s.ok()) { std::string old_fname = SSTTableFileName(dbname_, file_number); if (env_->NewRandomAccessFile(old_fname, &file).ok()) { s = Status::OK(); } } if (s.ok()) { s = Table::Open(options_, file, file_size, &table); } if (!s.ok()) { assert(table == nullptr); delete file; // We do not cache error results so that if the error is transient, // or somebody repairs the file, we recover automatically. } else { TableAndFile* tf = new TableAndFile; tf->file = file; tf->table = table; *handle = cache_->Insert(key, tf, 1, &DeleteEntry); } } return s; } -
Table::InternalGet
当 SSTable 中的数据被读入内存中的数据块后,数据以 Table 的形式保存。Table 中的 rep_ 结构保存了所有的数据。读取Tbale中的数据,首先需要读取Index_block中的索引数据,之后根据索引数据在 data block 中寻找,最终利用函数指针 SaveValue 处理迭代器指向的数据。
Status Table::InternalGet(const ReadOptions& options, const Slice& k, void* arg, void (*handle_result)(void*, const Slice&, const Slice&)) { Status s; Iterator* iiter = rep_->index_block->NewIterator(rep_->options.comparator); iiter->Seek(k); //利用二分查找法在index block中寻找对应key的位置 if (iiter->Valid()) { Slice handle_value = iiter->value(); FilterBlockReader* filter = rep_->filter; BlockHandle handle; if (filter != nullptr && handle.DecodeFrom(&handle_value).ok() && !filter->KeyMayMatch(handle.offset(), k)) { //如果有过滤器,可以先从过滤器中判断是否存在 // Not found } else { Iterator* block_iter = BlockReader(this, options, iiter->value()); //将index_block的值转换成data block的迭代器指针 block_iter->Seek(k); if (block_iter->Valid()) { (*handle_result)(arg, block_iter->key(), block_iter->value()); //使用SaveValue处理数据块指针 } s = block_iter->status(); delete block_iter; } } if (s.ok()) { s = iiter->status(); } delete iiter; return s; } -
SaveValue
利用 Saver 对象将搜索到的 value 值进行保存
static void SaveValue(void* arg, const Slice& ikey, const Slice& v) { Saver* s = reinterpret_cast
Put
在默认情况下,DBImpl 的 Put 函数直接调用父类 DB 的 Put 函数,而 DB::Put 间接调用 Write 函数,因此具体流程分析见 Write 函数。
Status DB::Put(const WriteOptions& opt, const Slice& key, const Slice& value) {
WriteBatch batch;
batch.Put(key, value);
return Write(opt, &batch);
}
Delete
在默认情况下,DBImpl 的 Delete 函数直接调用父类 DB 的 Delete 函数,而 DB::Delete 间接调用 Write 函数,因此具体流程分析见 Write 函数。
Status DB::Delete(const WriteOptions& opt, const Slice& key) {
WriteBatch batch;
batch.Delete(key);
return Write(opt, &batch);
}
Write
关于 Write 函数:整个 Write 函数负责对 DBImpl 更新数据,大致流程可以分为以下几个部分:
- 首先获取一个用于整个写入流程的文件Writer,并加入执行队列中,当执行队列执行到当前任务时,进行以下步骤
- 数据首先会被写到 log,保证持久性;
- 然后写入 mutable memtable 中,返回;
- 当 mutable 内存到达一定大小之后就会变成 immutable memtable;
- 当到达一定的条件后,后台的 Compaction 线程会把 immutable memtable 刷到盘中 Level 0 中 sstable;
- 当 level i 到一定条件后(某个 level 中的数据量或者 sstable 文件数据等)就会和 level i+1 中的 sstable 进行 Compaction,合并成 level i+1 的 sst 文件。
在Write函数的主流程中。仅出现前三步,后三步是在间接调用时发生的,这里暂不展开。
可以看到,LevelDB 的整个写入流程严格执行 WAL 机制,先写 log 日志后写 memtable,最后在 memtable 的写入重触发其他的流程执行,以及如果 log 日志的写入正确而 memtable 的执行出现问题时,也有对应的处理机制。
db_impl.cc
Status DBImpl::Write(const WriteOptions& options, WriteBatch* updates) {
// 生成用于写入的文件writer
Writer w(&mutex_);
w.batch = updates;
w.sync = options.sync;
w.done = false;
// 将生成的writer加入队列中,如果当前writer已在队列最前面,则执行此writer,
// 这里为了不让队列检查持续进行导致cpu做无用功,使用了cv条件锁,可以在必要时才唤醒流程,减少cpu空转
MutexLock l(&mutex_);
writers_.push_back(&w);
while (!w.done && &w != writers_.front()) {
w.cv.Wait();
}
if (w.done) {
return w.status;
}
// May temporarily unlock and wait.
Status status = MakeRoomForWrite(updates == nullptr);
uint64_t last_sequence = versions_->LastSequence(); //获取上一个版本最后的序列号,用于设置当前任务中writeBatch的序列号
Writer* last_writer = &w;
if (status.ok() && updates != nullptr) { // nullptr batch is for compactions
//这里有一个关于Group commit的处理,后面会解释
WriteBatch* write_batch = BuildBatchGroup(&last_writer);
WriteBatchInternal::SetSequence(write_batch, last_sequence + 1);
last_sequence += WriteBatchInternal::Count(write_batch);
// Add to log and apply to memtable. We can release the lock
// during this phase since &w is currently responsible for logging
// and protects against concurrent loggers and concurrent writes
// into mem_.
{
mutex_.Unlock();
status = log_->AddRecord(WriteBatchInternal::Contents(write_batch)); // 首先向log日志中写入操作内容(WAL)
bool sync_error = false;
if (status.ok() && options.sync) {
status = logfile_->Sync(); //如果需要同步,则将log日志内容刷出缓冲区
if (!status.ok()) {
sync_error = true;
}
}
if (status.ok()) {
// 当log日志添加成功后,将writeBatch对象添加到当前的memtable中
status = WriteBatchInternal::InsertInto(write_batch, mem_);
}
mutex_.Lock();
if (sync_error) {
// The state of the log file is indeterminate: the log record we
// just added may or may not show up when the DB is re-opened.
// So we force the DB into a mode where all future writes fail.
// 这部分是一个错误处理的分支,在log日志成功写入而向memtable中添加数据失败时,需要对已写入的日志内容进行处理
RecordBackgroundError(status);
}
}
if (write_batch == tmp_batch_) tmp_batch_->Clear();
versions_->SetLastSequence(last_sequence);
}
while (true) {
Writer* ready = writers_.front();
writers_.pop_front();
if (ready != &w) {
ready->status = status;
ready->done = true;
ready->cv.Signal();
}
if (ready == last_writer) break;
}
// Notify new head of write queue
if (!writers_.empty()) {
writers_.front()->cv.Signal();
}
return status;
}
Compact
Compact 是 LevelDB 中极为重要的一个步骤,前面已经概述了LevelDB的整体存储架构,以及他被称为LevelDB的原因。其中低 level 的 SSTable 在一定条件下不断转换为高 level 的 SSTable,这也就是 Compact 流程的主要工作,下面将展开介绍 LevelDB 的 Compact 流程。
分类
在 LevelDB 中 Compaction 从大的类别中分为两种,分别是:
- Minor Compaction,指的是 immutable memtable持久化为 sst 文件。
- Major Compaction,指的是 sst 文件之间的 compaction。
而Major Compaction主要有三种分别为:
(1)Manual Compaction,是人工触发的Compaction,由外部接口调用产生,例如在ceph调用的Compaction都是Manual Compaction,实际其内部触发调用的接口是:
void DBImpl::CompactRange(const Slice begin, const Slice end)
(2)Size Compaction,是根据每个level的总文件大小来触发,注意Size Compation的优先级高于Seek Compaction,具体描述参见Notes 2;
(3)Seek Compaction,每个文件的 seek miss 次数都有一个阈值,如果超过了这个阈值,那么认为这个文件需要Compact。
优先级
其中这些 Compaction 的优先级不一样(详细可以参见 BackgroundCompaction 函数),具体优先级的大小为:
Minor > Manual > Size > Seek
LevelDB 是在 MayBeScheduleCompaction 的 Compation 调度函数中完成各种 Compaction 的调度的,而关于Compaction的优先级可以在函数 BackgroundCompaction()查看。在执行Compact流程中,
- 首先判断 immutable memtable 的存在,那就需要优先将其转化为低 level 的 sst 文件(这里的转化不一定是转化为 level0 ,视情况而定,也有可能转化为 level1 或者其他 level 的 sst 文件),
- 第二步判断是不是 is_Manual情况下主动调用的 compact 。
- 最后调用 PickCompaction() 函数,它的内部会判断是不是有 Size Compaction 或者 Seek Compaction,进而进行处理。
具体每一种Compact的细节,下面一一展开。

Minor Compaction
Minor Compaction 是将 immutable memtable 持久化为 sst 文件。
-
执行条件
触发是在 Wirte(如put(key, value))新数据进入leveldb的时候,会在适当的时机检查内存中 memtable 占用内存大小,一旦超过 options_.write_buffer_size (default 4M),就会尝试 Minor Compaction。
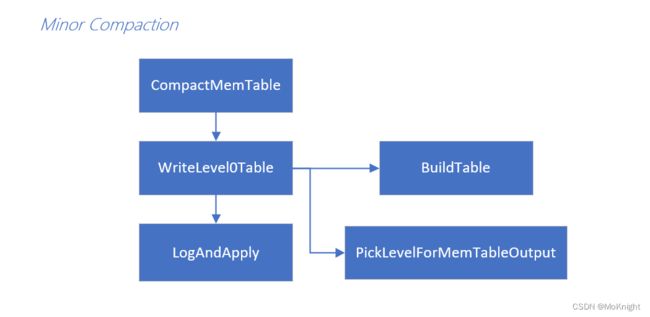
Minor Compaction 调用 BuildTable 函数将 memtable 对象转换成 SSTable 对象,通过 TableBuilder 对象存储到文件中。
新产生出来的sstable 并不一定总是处于level 0, 尽管大多数情况下,处于level 0。但最终放置于那一层还是由 PickLevelForMemTableOutput 函数来计算:
从策略上要尽量将新 compact 的文件推至高level,毕竟在 level 0 需要控制文件过多,compaction IO 和查找都比较耗费,另一方面也不能推至过高 level,一定程度上控制查找的次数,而且若某些范围的key更新比较频繁,后续往高层compaction IO消耗也很大。 所以PickLevelForMemTableOutput就是个权衡折中。
如果新生成的 SSTable 和 level 0 的 SSTable 有交叠,那么新产生的 SSTable 就直接加入 level 0,否则根据一定的策略,向上推到 level1 甚至是 level 2,但是最高推到 level2,这里有一个控制参数:kMaxMemCompactLevel。
-
流程

- BuildTable
LevelDB 通过 BuildTable 函数转换 memetable 为 SSTable,TableBuilder 包含一个指向 SSTable 文件的指针,一条记录的写入,需要同时要向 index_block,filter_block,data_block 写入记录到 block buffer 中,最后通过 Finish 函数写入文件。更加具体的吸入流程,可以在 BlockBuilder 和 TableBuilder 类中查看。
Major Compaction
LevelDB不断将 memtable 转化为 sst 文件,但如果不进行控制,最终 Major compaction 是将不同层级的 sst 的文件进行合并,目的是将
- 均衡各个level的数据,保证 read 的性能;
- 合并delete数据,释放磁盘空间,因为leveldb是采用的延迟(标记)删除;
- 合并update的数据,例如put同一个key,新put的会替换旧put的,虽然数据做了update,但是update类似于delete,是采用的延迟(标记)update,实际的update是在compact中完成,并实现空间的释放。
如上所述,Major Compaction主要有三种分别为,Manual Compaction,Size Compaction 和 Seek Compaction。
Manual Compaction
Manual Compaction,是人为触发的Compaction,由外部接口调用产生,实际其内部触发调用的接口是:void DBImpl::CompactRange(const Slice begin, const Slice end)。在 Manual Compaction 中会指定的 begin 和 end,它会对 Version 中所有 level 层查找与begin 和 end 有重叠(overlap)的 sst 文件。
-
执行条件
Manual Compaction仅由外部调用接口触发调用,内部的接口不会触发。

Size Compaction
Size Compaction是levelDB的核心Compact过程,其主要是为了均衡各个level的数据, 从而保证读写的性能均衡。
- 执行条件
levelDB会计算每个level的总的文件大小,并根据此计算出一个score,最后会根据这个score来选择合适 level 和文件进行Compact。具体的计算方式是由
VersionSet::Finalize()计算每一层level的score:
void VersionSet::Finalize(Version* v) {
// Precomputed best level for next compaction
int best_level = -1;
double best_score = -1;
for (int level = 0; level < config::kNumLevels - 1; level++) {
double score;
if (level == 0) {
// We treat level-0 specially by bounding the number of files
// instead of number of bytes for two reasons:
//
// (1) With larger write-buffer sizes, it is nice not to do too
// many level-0 compactions.
//
// (2) The files in level-0 are merged on every read and
// therefore we wish to avoid too many files when the individual
// file size is small (perhaps because of a small write-buffer
// setting, or very high compression ratios, or lots of
// overwrites/deletions).
score = v->files_[level].size() /
static_cast(config::kL0_CompactionTrigger);
} else {
// Compute the ratio of current size to size limit.
const uint64_t level_bytes = TotalFileSize(v->files_[level]);
score =
static_cast(level_bytes) / MaxBytesForLevel(options_, level);
}
if (score > best_score) {
best_level = level;
best_score = score;
}
}
v->compaction_level_ = best_level;
v->compaction_score_ = best_score;
}
-
执行流程
- 触发 compaction_score_ 的计算流程

Seek Compation
LevelDB中寻找任意key值时,都会由低到高,逐层 level 进行寻找,而在一个 level 总是没找到时,就说明当前 level 的 sst 文件需要进行一定的调整。
在levelDB中,每一个新的sst文件,都有一个 allowed_seeks 的初始阈值,表示最多容忍 seek miss 多少次,每个调用 Get seek miss 的时候,就会执行减1(allowed_seeks --)。其中 allowed_seeks 的初始阈值的计算方式为:
allowed_seeks = (sst文件的file size / 16384); // 16348——16kb
if ( allowed_seeks < 100 )
allowed_seeks = 100;
LevelDB认为如果一个 sst 文件在 level i 中总是没找到,而是在 level i+1 中找到,那么当这种 seek miss 积累到一定次数之后,就考虑将其从 level i 中合并到 level i+1 中,这样可以避免不必要的 seek miss 消耗 read I/O。当然在引入布隆过滤器后,这种查找消耗的 IO 就会变小很多。
-
执行条件
当 allowed_seeks 不断递减到阈值之下,并且在Version::RecordReadSample 函数中被检测到,就会触发Seek Compaction
-
执行流程
- 触发 allowed_seeks 的计算流程

- 触发 allowed_seeks 的计算流程
SnapShot
LevelDB 中的 Snapshot 并非一个真实的独立存储的 Snapshot,只是一个与特定数字绑定的版本号,根据 index.md中的说法:
Snapshots provide consistent read-only views over the entire state of the
key-value store. `ReadOptions::snapshot` may be non-NULL to indicate that a
read should operate on a particular version of the DB state. If
`ReadOptions::snapshot` is NULL, the read will operate on an implicit snapshot
of the current state.
GetSnapshot
用户可以通过这个函数接口对 DB 实例创建快照,LevelDB的快照由 SnapshotList 对象以双向链表的形式进行串联管理。创建新的快照依赖于参数 SequenceNumber,这个参数标识着关于已执行的 log 日志的日志号,每一个创建的快照依赖的sequenceNumber必须要小于最新的SequenceNumber。
const Snapshot* DBImpl::GetSnapshot() {
MutexLock l(&mutex_);
return snapshots_.New(versions_->LastSequence());
}
ReleaseSnapshot
释放 SnapshotList 对象上管理的特定SnapShot,当一个版本的 Snapshot 不再需要时尽可能释放 SnapShot 对象,节省不必要的空间。
RecordReadSample
在 Compact 的流程中,提及过 size compact ,是指当在搜索一个特定的键值时,横跨了太多层level,这代表在用户搜索一个键值对的最新状态时效率会很低,因此有必要进行compact,而如何检测,就是由 DBImpl::RecordReadSample 函数执行的,他会在 SSTable 中对指定的键进行搜索,以此触发可能的 size compact。
void DBImpl::RecordReadSample(Slice key) {
MutexLock l(&mutex_);
if (versions_->current()->RecordReadSample(key)) {
MaybeScheduleCompaction();
}
}