【机器学习】用户画像
用户画像-案例
基于用户搜索关键词数据为用户打上标签(年龄,性别,学历)
整体流程
(一)数据预处理
- 编码方式转换
- 对数据搜索内容进行分词
- 词性过滤
- 数据检查
(二)特征选择
- 建立word2vec词向量模型
- 对所有搜索数据求平均向量
(三)建模预测
- 不同机器学习模型对比
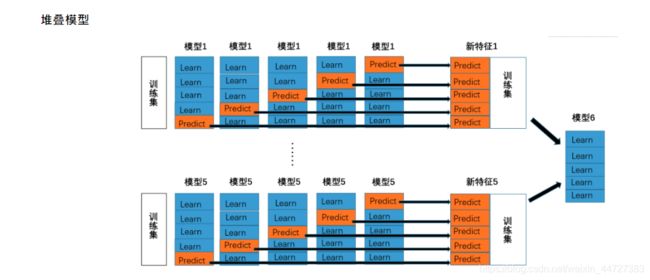
- 堆叠模型
将原始数据转换成utf-8编码,防止后续出现各种编码问题
由于原始数据比较大,在分词与过滤阶段会比较慢,这里我们选择了原始数据中的1W个
import csv
#原始数据存储路径
data_path = './data/user_tag_query.10W.TRAIN'
#生成数据路径
csvfile = open(data_path + '-1w.csv', 'w')
writer = csv.writer(csvfile)
writer.writerow(['ID', 'age', 'Gender', 'Education', 'QueryList'])
#转换成utf-8编码的格式
with open(data_path, 'r',encoding='gb18030',errors='ignore') as f:
lines = f.readlines()
for line in lines[0:10000]:
try:
line.strip()
data = line.split("\t")
writedata = [data[0], data[1], data[2], data[3]]
querystr = ''
data[-1]=data[-1][:-1]
for d in data[4:]:
try:
cur_str = d.encode('utf8')
cur_str = cur_str.decode('utf8')
querystr += cur_str + '\t'
except:
continue
#print (data[0][0:10])
querystr = querystr[:-1]
writedata.append(querystr)
writer.writerow(writedata)
except:
#print (data[0][0:20])
continue
data_path = './data/user_tag_query.10W.TEST'
csvfile = open(data_path + '-1w.csv', 'w')
writer = csv.writer(csvfile)
writer.writerow(['ID', 'QueryList'])
with open(data_path, 'r',encoding='gb18030',errors='ignore') as f:
lines = f.readlines()
for line in lines[0:10000]:
try:
data = line.split("\t")
writedata = [data[0]]
querystr = ''
data[-1]=data[-1][:-1]
for d in data[1:]:
try:
cur_str = d.encode('utf8')
cur_str = cur_str.decode('utf8')
querystr += cur_str + '\t'
except:
#print (data[0][0:10])
continue
querystr = querystr[:-1]
writedata.append(querystr)
writer.writerow(writedata)
except:
#print (data[0][0:20])
continue
生成对应的数据表
import pandas as pd
#编码转换完成的数据,取的是1W的子集
trainname = './data/user_tag_query.10W.TRAIN-1w.csv'
testname = './data/user_tag_query.10W.TEST-1w.csv'
data = pd.read_csv(trainname,encoding='gbk')
print (data.info())
#分别生成三种标签数据(性别,年龄,学历)
data.age.to_csv("./data/train_age.csv", index=False)
data.Gender.to_csv("./data/train_gender.csv", index=False)
data.Education.to_csv("./data/train_education.csv", index=False)
#将搜索数据单独拿出来
data.QueryList.to_csv("./data/train_querylist.csv", index=False)
data = pd.read_csv(testname,encoding='gbk')
print (data.info())
data.QueryList.to_csv("./data/test_querylist.csv", index=False)
对用户的搜索数据进行分词与词性过滤
import pandas as pd
import jieba.analyse
import time
import jieba
import jieba.posseg
import os, sys
def input(trainname):
traindata = []
with open(trainname, 'rb') as f:
line = f.readline()
count = 0
while line:
try:
traindata.append(line)
count += 1
except:
print ("error:", line, count)
line=f.readline()
return traindata
start = time.clock()
filepath = './data/test_querylist.csv'
QueryList = input(filepath)
writepath = './data/test_querylist_writefile-1w.csv'
csvfile = open(writepath, 'w')
POS = {}
for i in range(len(QueryList)):
#print (i)
if i%2000 == 0 and i >=1000:
print (i,'finished')
s = []
str = ""
words = jieba.posseg.cut(QueryList[i])# 带有词性的精确分词模式
allowPOS = ['n','v','j']
for word, flag in words:
POS[flag]=POS.get(flag,0)+1
if (flag[0] in allowPOS) and len(word)>=2:
str += word + " "
cur_str = str.encode('utf8')
cur_str = cur_str.decode('utf8')
s.append(cur_str)
csvfile.write(" ".join(s)+'\n')
csvfile.close()
end = time.clock()
print ("total time: %f s" % (end - start))
使用Gensim库建立word2vec词向量模型
参数定义:
-
sentences:可以是一个list
-
sg: 用于设置训练算法,默认为0,对应CBOW算法;sg=1则采用skip-gram算法。
-
size:是指特征向量的维度,默认为100。大的size需要更多的训练数据,但是效果会更好. 推荐值为几十到几百。
-
window:表示当前词与预测词在一个句子中的最大距离是多少
-
alpha: 是学习速率
-
seed:用于随机数发生器。与初始化词向量有关。
-
min_count: 可以对字典做截断. 词频少于min_count次数的单词会被丢弃掉, 默认值为5
-
max_vocab_size: 设置词向量构建期间的RAM限制。如果所有独立单词个数超过这个,则就消除掉其中最不频繁的一个。每一千万个单词需要大约1GB的RAM。设置成None则没有限制。
-
workers参数控制训练的并行数。
-
hs: 如果为1则会采用hierarchica·softmax技巧。如果设置为0(defau·t),则negative sampling会被使用。
-
negative: 如果>0,则会采用negativesamp·ing,用于设置多少个noise words
-
iter: 迭代次数,默认为5
from gensim.models import word2vec
#将数据变换成list of list格式
train_path = './data/train_querylist_writefile-1w.csv'
with open(train_path, 'r') as f:
My_list = []
lines = f.readlines()
for line in lines:
cur_list = []
line = line.strip()
data = line.split(" ")
for d in data:
cur_list.append(d)
My_list.append(cur_list)
model = word2vec.Word2Vec(My_list, size=300, window=10,workers=4)
savepath = '1w_word2vec_' + '300'+'.model' # 保存model的路径
model.save(savepath)
加载训练好的word2vec模型,求用户搜索结果的平均向量
import numpy as np
file_name = './data/train_querylist_writefile-1w.csv'
cur_model = gensim.models.Word2Vec.load('1w_word2vec_300.model')
with open(file_name, 'r') as f:
cur_index = 0
lines = f.readlines()
doc_cev = np.zeros((len(lines),300))
for line in lines:
word_vec = np.zeros((1,300))
words = line.strip().split(' ')
wrod_num = 0
#求模型的平均向量
for word in words:
if word in cur_model:
wrod_num += 1
word_vec += np.array([cur_model[word]])
doc_cev[cur_index] = word_vec / float(wrod_num)
cur_index += 1
import numpy as np
file_name = './data/test_querylist_writefile-1w.csv'
cur_model = gensim.models.Word2Vec.load('1w_word2vec_300.model')
with open(file_name, 'r') as f:
cur_index = 0
lines = f.readlines()
doc_cev = np.zeros((len(lines),300))
for line in lines:
word_vec = np.zeros((1,300))
words = line.strip().split(' ')
wrod_num = 0
#求模型的平均向量
for word in words:
if word in cur_model:
wrod_num += 1
word_vec += np.array([cur_model[word]])
doc_cev[cur_index] = word_vec / float(wrod_num)
cur_index += 1
genderlabel = np.loadtxt(open('./data/train_gender.csv', 'r')).astype(int)
educationlabel = np.loadtxt(open('./data/train_education.csv', 'r')).astype(int)
agelabel = np.loadtxt(open('./data/train_age.csv', 'r')).astype(int)
处理一些为0的数据
def removezero(x, y):
nozero = np.nonzero(y)
y = y[nozero]
x = np.array(x)
x = x[nozero]
return x, y
gender_train, genderlabel = removezero(doc_cev, genderlabel)
age_train, agelabel = removezero(doc_cev, agelabel)
education_train, educationlabel = removezero(doc_cev, educationlabel)
绘图函数,绘制混淆矩阵
import matplotlib.pyplot as plt
import itertools
def plot_confusion_matrix(cm, classes,
title='Confusion matrix',
cmap=plt.cm.Blues):
"""
This function prints and plots the confusion matrix.
"""
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=0)
plt.yticks(tick_marks, classes)
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, cm[i, j],
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
建立一个基础预测模型
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix
from sklearn.cross_validation import train_test_split
X_train, X_test, y_train, y_test = train_test_split(gender_train,genderlabel,test_size = 0.2, random_state = 0)
LR_model = LogisticRegression()
LR_model.fit(X_train,y_train)
y_pred = LR_model.predict(X_test)
print (LR_model.score(X_test,y_test))
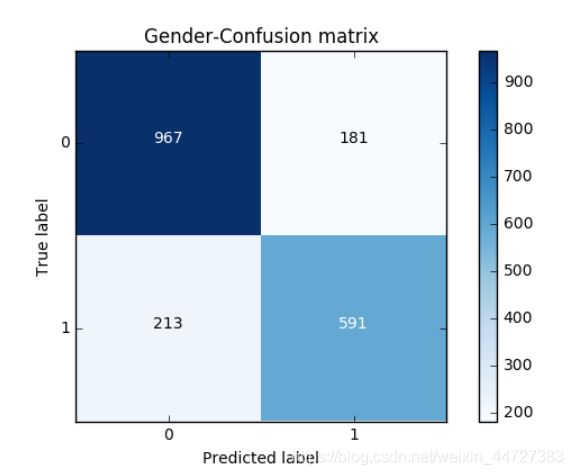
cnf_matrix = confusion_matrix(y_test,y_pred)
print("Recall metric in the testing dataset: ", cnf_matrix[1,1]/(cnf_matrix[1,0]+cnf_matrix[1,1]))
print("accuracy metric in the testing dataset: ", (cnf_matrix[1,1]+cnf_matrix[0,0])/(cnf_matrix[0,0]+cnf_matrix[1,1]+cnf_matrix[1,0]+cnf_matrix[0,1]))
# Plot non-normalized confusion matrix
class_names = [0,1]
plt.figure()
plot_confusion_matrix(cnf_matrix
, classes=class_names
, title='Gender-Confusion matrix')
plt.show()
0.798155737705
Recall metric in the testing dataset: 0.735074626866
accuracy metric in the testing dataset: 0.798155737705
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import confusion_matrix
from sklearn.cross_validation import train_test_split
X_train, X_test, y_train, y_test = train_test_split(gender_train,genderlabel,test_size = 0.2, random_state = 0)
RF_model = RandomForestClassifier(n_estimators=100,min_samples_split=5,max_depth=10)
RF_model.fit(X_train,y_train)
y_pred = RF_model.predict(X_test)
print (RF_model.score(X_test,y_test))
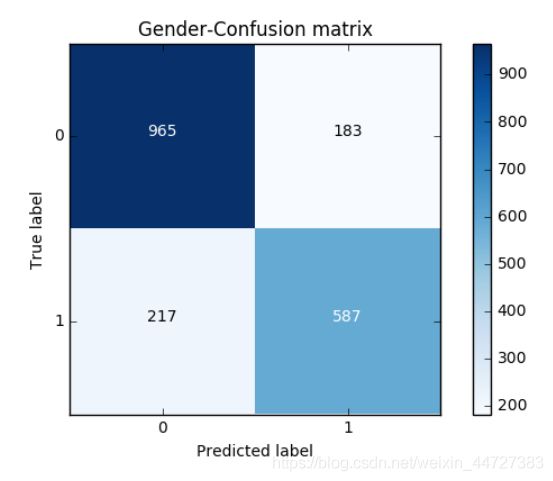
cnf_matrix = confusion_matrix(y_test,y_pred)
print("Recall metric in the testing dataset: ", cnf_matrix[1,1]/(cnf_matrix[1,0]+cnf_matrix[1,1]))
print("accuracy metric in the testing dataset: ", (cnf_matrix[1,1]+cnf_matrix[0,0])/(cnf_matrix[0,0]+cnf_matrix[1,1]+cnf_matrix[1,0]+cnf_matrix[0,1]))
# Plot non-normalized confusion matrix
class_names = [0,1]
plt.figure()
plot_confusion_matrix(cnf_matrix
, classes=class_names
, title='Gender-Confusion matrix')
plt.show()
0.795081967213
Recall metric in the testing dataset: 0.730099502488
accuracy metric in the testing dataset: 0.795081967213
堆叠模型
from sklearn.svm import SVC
from sklearn.naive_bayes import MultinomialNB
clf1 = RandomForestClassifier(n_estimators=100,min_samples_split=5,max_depth=10)
clf2 = SVC()
clf3 = LogisticRegression()
basemodes = [
['rf', clf1],
['svm', clf2],
['lr', clf3]
]
from sklearn.cross_validation import KFold, StratifiedKFold
models = basemodes
#X_train, X_test, y_train, y_test
folds = list(KFold(len(y_train), n_folds=5, random_state=0))
print (len(folds))
S_train = np.zeros((X_train.shape[0], len(models)))
S_test = np.zeros((X_test.shape[0], len(models)))
for i, bm in enumerate(models):
clf = bm[1]
#S_test_i = np.zeros((y_test.shape[0], len(folds)))
for j, (train_idx, test_idx) in enumerate(folds):
X_train_cv = X_train[train_idx]
y_train_cv = y_train[train_idx]
X_val = X_train[test_idx]
clf.fit(X_train_cv, y_train_cv)
y_val = clf.predict(X_val)[:]
S_train[test_idx, i] = y_val
S_test[:,i] = clf.predict(X_test)
final_clf = RandomForestClassifier(n_estimators=100)
final_clf.fit(S_train,y_train)
print (final_clf.score(S_test,y_test))
5
0.796106557377
结果不是很好,可以继续调参