YOLO系列笔记(YOLO v1-v3)
v1:
you only look once
2016CVPR
45FPS 448*448
63.4mAP
1、将一幅图像分成SxS个网格(grid cell), 如果某个object的中心 落在这个网格 中,则这个网格就负责预测这个object。
2、每个网格要预测B个bounding box,每个bounding box 除了要预测位置之外,还要附带预测一个confidence值。 每个网格还要预测C个类别的分数。
7*7*30
4:box1(x,y,w,h)
1:confidence1
4:box2(x,y,w,h)
1:confidence2
20:class scores
confidence:预测目标与真实目标的iou*(0or1)
bounding box损失:大小不同目标的误差是由wh带来
存在问题:
1、群体型小目标检测效果很差两个bbox(针对7*7)属于同一类别
2、目标出现新的尺寸和配置时预测效果很差
3、错误原因主要来自定位不准
v2
yolo9000:better,faster,stronger
1、batch normaliazation训练收敛有帮助,对模型起正则化的作用,省去dropout操作
2、high resolution classifier更高分辨率分类器
3、convolutional with anchor boxes简化预测问题,更加容易学习
4、dimension clusters对训练集目标边界框采用k-means,更加容易学习(fasterrcnn)
5、direct location prediction,采用anchor会使模型不稳定尤其在前期,不稳定因素主要来自于预测目标边界框中心坐标xy,限制坐标信息
6、fine-grained features高层特征与底层特征进行融合
7、multi_scale training多尺度训练,每10个epoch随机更改图像尺寸
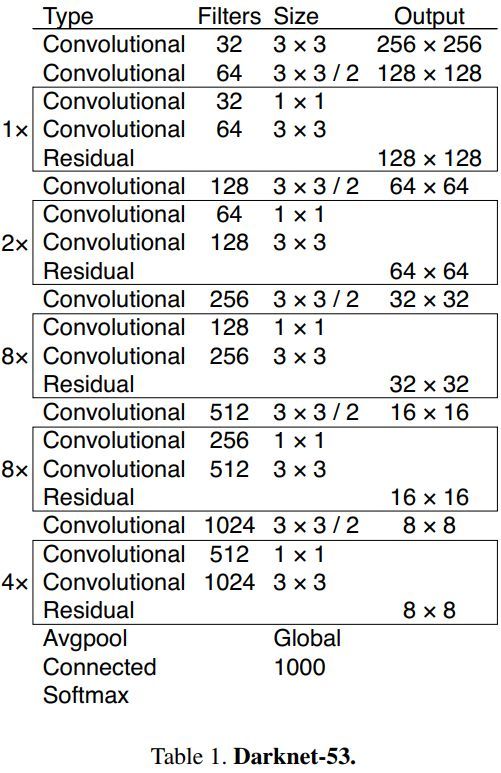
backbone:darknet-19(19个卷积层)
convolutional:conv2d+bias+reakyrelu,卷积层不包含偏执
training for detection:for voc 5 个bboxes*5个参数
v3
yolov3:an incremental improvement
2018 cvpr
backbone:darknet-53
卷积层替换maxpooling:没有池化层,卷积+bn+leakyrelu layer
残差结构:1*1卷积+3*3卷积再于输入相加
预测:三个预测特征层*三个尺度(聚类算法)
N*N*[3*(4+1+80)]:三个尺度*(4个偏移参数+1个confidence分数+coco数据集80个类别)
类别损失:二值交叉熵损失、
定位损失:sum of squared error loss\
v3 ssp
1.mosaic图像增强,多张图像拼接一起训练。增加数据多样性,增加目标个数,bn能一次性统计多张图片的参数。
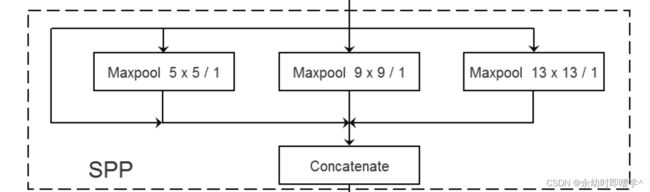
2.spp模块,借鉴了sppnet的spp结构,实现了不同尺度的融合
3.使用ciou计算损失(更快收敛,达到更高精度)(iou、giou、diou)
回归定位损失应考虑(重叠面积iou,中心点距离diou,长宽比ciou)
4.focal loss前景和背景极度不平衡的情况