YOLO系列学习笔记
一,YOLO
1,主要过程
1):将图片分成 S * S (论文中取7)个网格,若某个对象中心坐落于一个网格内,则该网格负责检测该对象。
2):每个网格预测B个bounding boxes和其相应confidence,confidence可以理解为该框包含对象的概率乘以IoU。
3):每个bounding box预测5个值,x、y、w、h、confidence,x、y是对象中心相对于网格边界的偏移量,w、h是相对于整张 图片的长度。
4):每个网格还会预测一个类别(注意,不是每个bounding box),即Pr(Class_i | Object)。故,在测试时需要把Pr和 confidence相称以表示类别概率。
综上,一张图片预测 S * S * (B * 5 + C) 个值。
2,结构
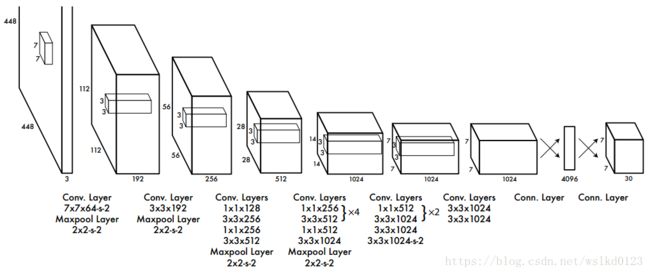
24个卷积层和2个全连接层,输出为7 * 7 * 30(S=7, B=2, C=20)。另,Fast YOLO中仅用了9个卷积层,用到的filter个数 也更少,其他完全相同。
3,训练
1):利用前20个卷积层+平均池化+全连接在ImageNet 1000-class上预训练。
2):用上面训练好的前20层接上4个卷积层再加两个全连接层,进行fine-tune(输入尺寸增加到448*448)。
3):最后一层线性激活,其他用层 leaky relu (0.1)激活。
4):loss function使用简单的平方和函数(为了快)。
5):预测width和height的平方根,而非直接预测。
损失函数详细公式如下:
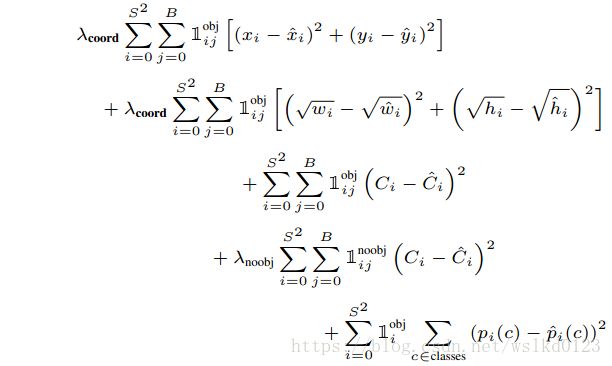
二,YOLOv2 / YOLO9000
在yolo基础上改进,yolo缺点:定位错误多;召回率低。
Better(YOLO基础上):
1:在所有卷积层中加入Batch Nomalization;去掉了dropout。mAP提高了2%。
2:YOLOv2中,训练好分类网络后,先使用ImageNet进行fine-tune 10个epoches训练分类网络(此时把分辨率改成448*448),作为过渡,然后再fine-tune检测网络。mAP提高了4%。
3:加入anchor boxes,先去掉最后一个pooling层和全连接层,用416*416作为图片输入(为了得到奇数大小特征图),得到13*13大小的特征图。为每个anchor box预测类别。mAP降低0.3%,召回率提高7% 。
4:维度聚类,在训练集的bounding boxes上使用k-means聚类,使用如下公式计算距离:
d(box, centroid) = 1 - IoU(box, centroid)
5:直接预测位置,因为如果像FRCN那样预测相对于anchor的偏移量,很容易预测结果跑出这个网格了,造成不稳定。
于是作者采用直接预测位置 ,论文中每个cell预测5个bounding boxes,每个bounding box预测5个值,分别为:
tx,ty,tw,th,to;to相当于YOLO中的confidence,如下预测:
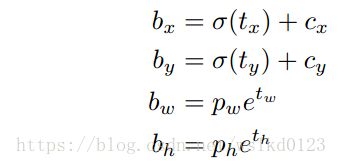
Cx, Cy是网格相对于整张图片的偏移,Pw,Ph是anchor box的形状。
6:更加精细的特征,
如图,把浅层的26×26的特征图和13×13特征图融合,通过把26 * 26 * 512的特征图按行和列隔行采样,得到4个新的 特征图,维度都是13 * 13 * 512,然后做concat操作,得到13 * 13 * 2048的特征图,将其拼接到后面的层。
有利于检测小目标。
7:多尺度训练。按32的倍数设置尺寸(因为pooling会降低32倍){320,352,...,608}。
Faster:
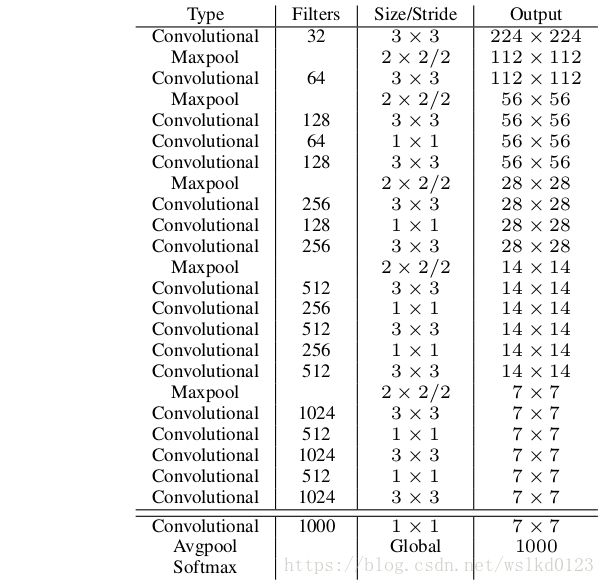
1: 使用Darknet-19作为特征提取网络,结构如下,
2:分类训练
使用Darknet-19在标准1000类的ImageNet上训练了160次(SGD),starting learning rate 为 0.1,polynomial rate decay 为4,weight decay为0.0005 ,momentum 为0.9。仍使用数据扩充方法(data augmentation),包括random crops, rotations, and hue, saturation, and exposure shifts。
初始224 * 224训练后,把分辨率上调到了448 * 448,又训练10次,学习率调整到0.001。高分辨率下训练的分类网络在top-1准确率76.5%,top-5准确率93.3%
3:检测训练
去掉了原网络最后一个卷积层,转而增加了三个3 * 3 * 1024的卷积层,并且在每一个上述卷积层后面跟一个1 * 1的卷积层,输出维度是检测所需的数量。对于VOC数据集,预测5种boxes大小,每个box包含5个坐标值和20个类别,所以总共是5 * (5+20)= 125个输出维度。同时也添加了转移层(passthrough layer ),从最后那个3 * 3 * 512的卷积层连到倒数第二层,使模型有了细粒度特征。
检测模型以0.001的初始学习率训练160次,在60次和90次的时候,学习率减为原来的十分之一。weight decay为0.0005,momentum为0.9,依然使用了类似于Faster-RCNN和SSD的数据扩充(data augmentation)策略。
Stronger(YOLO9000):
待学习
三,YOLOv3
1,贡献
(1):位置预测依然使用直接预测和平方和损失函数;目标预测(是否含有对象,并非类别预测)使用逻辑回归损失,即把和真实框IoU最高的先验框设为1,其他那些非最高的且IoU高于阈值(论文中取0.5)的不参与训练。每个真实框仅匹配一个先验框。标签为0的先验框(即不含对象)只参与objectness loss的计算,不参与坐标回归损失和分类损失计算。
(2):类别预测,放弃使用softmax,使用多个独立的逻辑回归预测。
(3):使用类FPN结构多分支预测
(4):使用更好的检测网络类ResNet网络:Darknet-53。
2,训练和YOLOv2相似。
3,优点:快速,pipline简单;背景误检率低;通用性强。
缺点:识别物体位置精准性差;召回率低