训练第一个MMClassification模型
一、 MMClassification项目结构
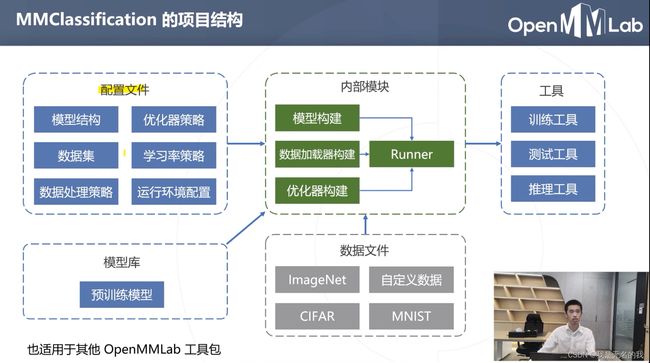
MMClassification的项目结如图如图所示,截图来自openmmlab的B站官方。不仅是MMClassification,openmmlab的其他工具包也是同样的项目结构。
二、MMClassification安装、验证
(一)安装
参考官方安装教程,安装MMClassification
在安装前,我们需要先安装通过sudo apt install git安装git,然后执行以下:
conda create --name openmmlab python=3.8 -y
conda activate openmmlab
pip install -U openmim -i http://pypi.douban.com/simple/ # 代表从豆瓣源安装,加快安装速度
mim install mmcv-full
git clone https://github.com/open-mmlab/mmclassification.git
cd mmclassification
pip install -e . -i http://pypi.douban.com/simple/
(二)验证
在MMClassification目录下打开终端
1.下载配置文件以及模型
mim download mmcls --config resnet50_8xb32_in1k --dest .
2.用模型进行验证测试
python demo/image_demo.py demo/demo.JPEG resnet50_8xb32_in1k.py resnet50_8xb32_in1k_20210831-ea4938fc.pth --device cpu
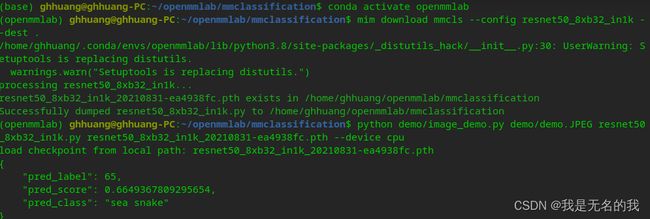
我们的demo.JPEG 确实是个蟒蛇
(三)训练第一个分类网络
在这里,我们训练第一个分类神经网络—猫狗分类,数据集在这里(提取码: f8m4,自解压文件)。
1.更改配置文件
在./mmclassification/configs/mobilenet_v2路径下,我们复制mobilenet-v2_8xb32_in1k.py文件为mobilenet-v2_8xb32_cat_dog.py(我电脑太垃圾,只能使用mobilenet_v2进行测试),然后对配置文件进行修改。
_base_ = [
'../_base_/models/mobilenet_v2_1x.py',
'../_base_/datasets/imagenet_bs32_pil_resize.py',
'../_base_/schedules/imagenet_bs256.py',
'../_base_/default_runtime.py'
]
(1)修改models
打开
./mmclassification/configs/__base__/models/mobilenet_v2_1x.py
复制以下代码至mobilenet-v2_8xb32_cat_dog.py
# model settings
model = dict(
type='ImageClassifier',
backbone=dict(type='MobileNetV2', widen_factor=1.0),
neck=dict(type='GlobalAveragePooling'),
head=dict(
type='LinearClsHead',
num_classes=1000,
in_channels=1280,
loss=dict(type='CrossEntropyLoss', loss_weight=1.0),
topk=(1, 5),
))
修改为
# model settings
model = dict(
type='ImageClassifier',
backbone=dict(type='MobileNetV2', widen_factor=1.0),
neck=dict(type='GlobalAveragePooling'),
head=dict(
type='LinearClsHead',
num_classes=2, #这里
in_channels=1280,
loss=dict(type='CrossEntropyLoss', loss_weight=1.0),
topk=(1, ), # 这里
))
(2)修改datasets
打开
./mmclassification/configs/__base__/datasets/imagenet_bs32_pil_resize.py
复制以下代码至mobilenet-v2_8xb32_cat_dog.py
data = dict(
samples_per_gpu=32,
workers_per_gpu=2,
train=dict(
type=dataset_type,
data_prefix='data/imagenet/train',
pipeline=train_pipeline),
val=dict(
type=dataset_type,
data_prefix='data/imagenet/val',
ann_file='data/imagenet/meta/val.txt',
pipeline=test_pipeline),
test=dict(
# replace `data/val` with `data/test` for standard test
type=dataset_type,
data_prefix='data/imagenet/val',
ann_file='data/imagenet/meta/val.txt',
pipeline=test_pipeline))
evaluation = dict(interval=1, metric='accuracy')
修改为
data = dict(
samples_per_gpu=32, #根据自己显卡性能修改
workers_per_gpu=2,
train=dict(
type=dataset_type,
data_prefix='data/imagenet/train', #自己文件的路径
pipeline=train_pipeline,
classes = 'data/imagenet/meta/classes.txt'), #原来imagenet的分类数有1000类,我们需要修改为2类,其中0:cat、1:dog
val=dict(
type=dataset_type,
data_prefix='data/imagenet/val',#自己文件的路径
ann_file='data/imagenet/meta/val.txt',#自己文件的路径
pipeline=test_pipeline),
test=dict(
# replace `data/val` with `data/test` for standard test
type=dataset_type,
data_prefix='data/imagenet/val', #自己文件的路径
ann_file='data/imagenet/meta/val.txt', #自己文件的路径
pipeline=test_pipeline))
evaluation = dict(metric_options={'topk': (1, )}) #验证流程,我们只有2个分类,不需要前五个分类情况
(3)修改schedules
打开
./mmclassification/configs/__base__/schedules/imagenet_bs256.py
复制
# optimizer
optimizer = dict(type='SGD', lr=0.1, momentum=0.9, weight_decay=0.0001)
optimizer_config = dict(grad_clip=None)
# learning policy
lr_config = dict(policy='step', step=[30, 60, 90])
runner = dict(type='EpochBasedRunner', max_epochs=100)
修改为
# optimizer
optimizer = dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0001) #修改lr(学习率)=0.01,对模型的fine tune(微调),不需要太大的学习率
optimizer_config = dict(grad_clip=None)
# learning policy 学习率下降策略
lr_config = dict(policy='step', step=[3, 6]) # 在第3、6轮更改学习率
runner = dict(type='EpochBasedRunner', ,max_epochs=10) #训练10轮
(4)修改default_runtime
# yapf:enable
load_from = '/mmclassification/mobilenet_v2_batch256_imagenet_20200708-3b2dc3af.pth' #修改为你使用的初始化模型路径
(5)组合配置文件与解析
_base_ = [
'../_base_/models/mobilenet_v2_1x.py', # 模型
'../_base_/datasets/imagenet_bs32_pil_resize.py', # 数据来源
'../_base_/schedules/imagenet_bs256.py', #训练策略
'../_base_/default_runtime.py' #默认运行环境
]
# model settings
model = dict(
type='ImageClassifier', # 分类器类型
backbone=dict(type='MobileNetV2', widen_factor=1.0),
neck=dict(type='GlobalAveragePooling'),# 颈网络类型
head=dict(
type='LinearClsHead',# 线性分类头
num_classes=2, #输出类别数,我们只有猫狗两类,修改为2
in_channels=1280, #输入通道数,这与 neck 的输出通道一致
loss=dict(type='CrossEntropyLoss', loss_weight=1.0),
topk=(1, ), # 评估指标,Top-k 准确率, 这里为 top1 与 top5 准确率
))
# dataset settings
data = dict(
samples_per_gpu=32, #单个 GPU 的 Batch size 根据机器性能修改
workers_per_gpu=2, # 单个 GPU 的 线程数
train=dict(
type=dataset_type,# 数据集名称
data_prefix='data/imagenet/train', #自己文件的路径
pipeline=train_pipeline,
classes = 'data/imagenet/meta/classes.txt'), #原来imagenet的分类数有1000类,我们需要修改为2类,其中0:cat、1:dog
val=dict(
type=dataset_type,
data_prefix='data/imagenet/val',#自己文件的路径
ann_file='data/imagenet/meta/val.txt',#自己文件的路径
pipeline=test_pipeline),
test=dict(
# replace `data/val` with `data/test` for standard test
type=dataset_type,
data_prefix='data/imagenet/test', #自己文件的路径
ann_file='data/imagenet/meta/test.txt', #自己文件的路径
pipeline=test_pipeline))
evaluation = dict(metric_options={'topk': (1, )}) #验证流程,我们只有2个分类,不需要前五个分类情况
# optimizer
optimizer = dict(type='SGD', # 优化器类型
lr=0.1, # 优化器的学习率,修改lr(学习率)=0.01,对模型的fine tune(微调),不需要太大的学习率
momentum=0.9, # 动量(Momentum)
weight_decay=0.0001) # 权重衰减系数(weight decay)
optimizer_config = dict(grad_clip=None)
# learning policy 学习率下降策略
lr_config = dict(policy='step', step=[3, 6]) # 在第3、6轮时, lr 进行衰减
runner = dict(type='EpochBasedRunner', ,max_epochs=10) #训练10轮
# yapf:enable
load_from = '/mmclassification/mobilenet_v2_batch256_imagenet_20200708-3b2dc3af.pth' #修改为你使用的初始化模型路径
2.训练第一个模型
在./mmclassification打开终端,输入
python tools/train.py configs/mobilenet_v2/mobilenet-v2_8xb32_cat_dog.py --work-dir work_dir/new
其中tools/train.py用到的训练文件;configs/mobilenet_v2/mobilenet-v2_8xb32_cat_dog.py 刚刚的配置文件;--work-dir work_dir/new训练产生的配置文件、日志文件、模型文件保存路径
然后,终端输出以下:
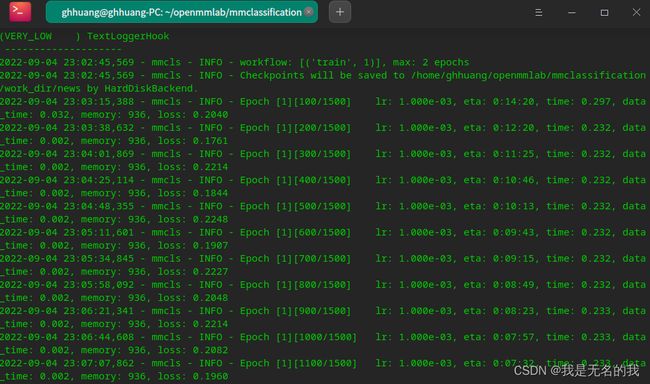
可以看到第一轮lr: 1.000e-03,第二轮lr: 1.000e-04,学习率变小了。
3.测试
以上是为了快速出结果,所以才训练2轮,在以下的测试中,我使用一个训练了10轮的模型进行测试。
在终端输入
python tools/test.py ./work_dir/new//mobilenet-v2_8xb32_cat_dog.py ./work_dir/new/latest.pth --metrics=accuracy --metric-options=topk=1
得出测试结果为准确度accuracy : 94.5
[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 4000/4000, 206.7 task/s, elapsed: 19s, ETA: 0s
accuracy : 94.5
from mmcls.apis import init_model, inference_model, show_result_pyplot
config_file = '/home/ghhuang/openmmlab/mmclassification/work_dir/new/mobilenet-v2_8xb32_cat_dog.py' #配置文件
checkpoint_file = '/home/ghhuang/openmmlab/mmclassification/work_dir/new/latest.pth' #模型路径
model = init_model(config_file, checkpoint_file, device='cuda:0') #初始化模型
img = '/home/ghhuang/openmmlab/mmclassification/demo/dog.webp' #图片路径
result = inference_model(model, img) #推理
show_result_pyplot(model, img, result) #推理结果可视化

可以看出照片成功识别为dog