对比学习介绍Contrastive Learning
1. 无监督学习分类
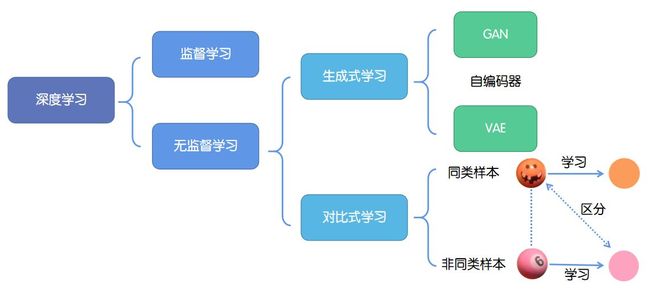
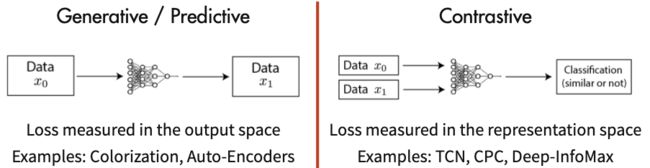
- 生成式方法:以自编码器为代表,主要关注pixel label的loss。举例来说,在自编码器中对数据样本编码成特征再解码重构,这里认为重构的效果比较好则说明模型学到了比较好的特征表达,而重构的效果通过pixel label的loss来衡量。
- 对比式学习:着重于学习同类实例之间的共同特征,区分非同类实例之间的不同之处。不需要关注实例上繁琐的细节,只需要在抽象语义级别的特征空间上学会对数据的区分即可,因此模型以及其优化变得更加简单,且泛化能力更强。
2. 对比学习Contrastive Learning
2.1 介绍
对比学习(Contrastive Learning)是一种最近非常流行的自监督学习(Self-Supervised Learning)技术,它利用无标签训练数据生成的成对的增广数据(augmentations)去定义一个分类任务作为前置任务(pretext task),目的是学到一个足够好的深度表示(deep embedding)。
对比学习的前置任务则是将每一个实例(instance)作为一个类别(class),然后去学习一个不变的实例表示(invariant instance representation)。具体实现方式为,首先为每个实例生成一对样本,然后将它们输入一个编码器(encoder),然后利用对比损失(contrastive loss)去训练这个编码器。这个对比损失会鼓励,由同一个实例产生的正样本对的表示(embeddings)互相靠近,而由不同实例产生的负样本对的表示互相远离。
对比学习的目标是学习一个编码器,此编码器对同类数据进行相似的编码,并使不同类的数据的编码结果尽可能的不同。
2.2 正负样本选择(单个正样本+多个负样本)
Contrastive Methods主要的难点在于如何构造正负样本。
Contrastive Predictive Coding (CPC)
对于语音和文本,可以充分利用了不同的 k 时间步长来采集正样本,而负样本可以从序列随机取样来得到。对于图像任务,可以使用 pixelCNN 的方式将其转化成一个序列类型

具体的:给定声音序列上下文Ct和Xt,我们推断预测Xt+1位置上的声音信号。此时,正样本Xt+1,负样本随机采样Xt*
Deep InfoMax
正样本就是图片的 global feature 和中间 feature map 上个的 local feature,而负样本就是另外一张图片
Contrastive MultiView Coding
除了像上面这样去构建正负样本,还可以通过多模态的信息去构造。比如同一张图片的 RGB图 和 深度图去选择正样本,而且通过这个方式,每个 anchor 不仅仅只有一个正样本,可以通过多模态得到多个正样本。但是如何节省内存和空间获得大量的负样本仍然没有很好地解决。
SimCLR
如果一个批包含N个图像,那么对于每个图像,我们将得到2个表示,这总共占2*N个表示。对于一个特定的表示x,有一个表示与x形成正对(与x来自同一个图像的表示,通过旋转、裁剪、剪切、噪声、模糊、Sobel滤波等数据增强方式),其余所有表示(正好是2*N–2)与x形成负对。
Supervised Contrastive Learning
有标签数据集,除了同一图像不同表示作为正样本,同类别的数据也作为正样本;不同类别的数据作为负样本
2.3 损失函数Loss
Contrastive Loss:

W 是网络权重;Y是成对标签,如果X1,X2这对样本属于同一个类,Y=0,属于不同类则 Y=1。Dw 是 X1 与 X2 在潜变量空间的欧几里德距离。
InfoNCE Loss表示为: (增加了更多的不相似样本)

Supervised Contrastive Learning Loss:

具象化表示:

1) 计算相似度
2) Cross-Entropy
2.4 代码实现Loss
import torch
import torch.nn as nn
def similarity(q,k,queue):
T=0.07
# compute logits
# Einstein sum is more intuitive;相似度计算
# positive logits: Nx1
l_pos = torch.einsum('nc,nc->n', [q, k]).unsqueeze(-1)
# negative logits: NxK
l_neg = torch.einsum('nc,ck->nk', [q, queue])
# 正负样本拼接
# logits: Nx(1+K)
logits = torch.cat([l_pos, l_neg], dim=1)
# apply temperature 超参数
logits /= T
return logits
batch=32
N=15
im_q=torch.randn(batch,12)
im_k=torch.rand(batch,12)
im_neg=torch.rand(12,N) #队列中取N个作为负样本
# define loss function (criterion) and optimizer
criterion = nn.CrossEntropyLoss()
# compute output
output = similarity(im_q, im_k,im_neg)
# labels: positive key indicators 生成标签
labels = torch.zeros(output.shape[0], dtype=torch.long)
loss = criterion(output, labels)
reference:
https://zhuanlan.zhihu.com/p/130914340
https://zhuanlan.zhihu.com/p/346686467
https://zhuanlan.zhihu.com/p/141172794