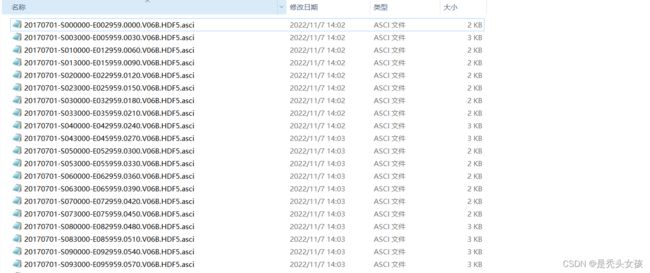
python+IDM实现快速批量化下载 (解决IDM批量化下载文件类型出现Error问题)
曲线救国:解决IDM批量化下载时文件类型出现Error问题。
前言:本人在利用IDM进行“NASA全球”中相关数据下载时出现无法批量化进行,特此记录解决方案。
“1.利用IDM进行“NASA全球”下载数据步骤原帖”
一、问题
当利用IDM进行 大批量下载出现 文件类型显示Error错误,如下图所示:
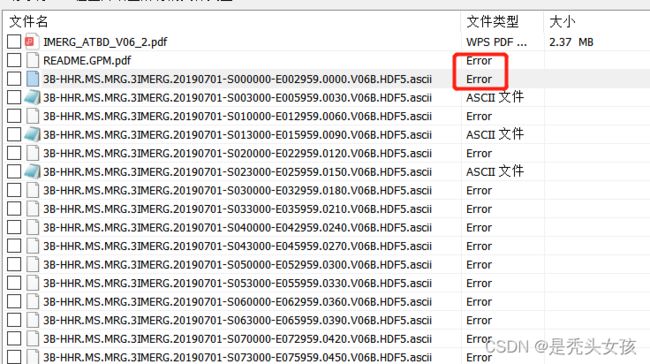 于是尝试小批量下载,发现最多只能同时下载5个链接的数据,如下图所示:
于是尝试小批量下载,发现最多只能同时下载5个链接的数据,如下图所示:
 呜呜呜~~~总不能每次只复制5个进行下载呐,得下载到什么时候,闹心。
呜呜呜~~~总不能每次只复制5个进行下载呐,得下载到什么时候,闹心。
于是通过查询资料进行试验,最终找到解决办法。
二、解决方案
总述:利用python + IDM 实现快速批量化自动下载。
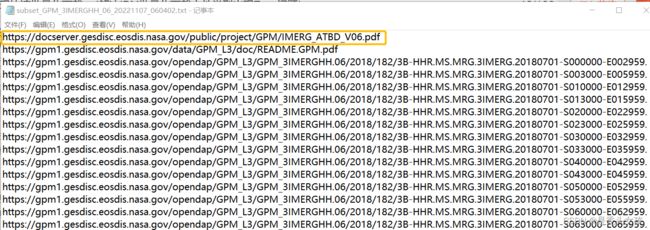
前提:已经获得需要下载的链接列表(此处我存放在了txt文件中),如下图所示(其中每一行代表一个下载链接):
 原理:利用python读取到每一个链接str,然后调用IDM进行下载,具体代码如下:
原理:利用python读取到每一个链接str,然后调用IDM进行下载,具体代码如下:
备注:此处下载的时候,为了命名文件方便,故批量链接里均长相相似(即删除了上图链接中的前俩条),具体如下图所示:

from subprocess import call
import os
from os.path import join
from os import listdir
def idmDownloader(task_url, folder_path, file_name):
"""
IDM下载器
:param task_url: 下载任务地址
:param folder_path: 存放文件夹
:param file_name: 文件名
:return:
"""
# IDM安装目录
idm_engine = "H:\\IDM\\IDMan.exe"
# 将任务添加至队列
call([idm_engine, '/d', task_url, '/p', folder_path, '/f', file_name, '/a'])
# 开始任务队列
call([idm_engine, '/s'])
if __name__ == '__main__':
result = []
with open('H:\\data\\subset_GPM_3IMERGHH_06_20221107_060058.txt', encoding='utf-8') as f:
for line in f:
result.append(line.strip('\n').split(',')[0])
for i in range(len(result)):
url = result[i] # 取出每次要下载的链接
path = 'H:\\data\\' # 存放下载后数据的文件夹
filename = result[i][98:142] # 文件名,此处我截取的下载链接的部分字符串,具体如下黑色图所示
idmDownloader(url, path, filename) # 添加进IDM中下载
print(filename + "----save")
代码运行结果:打印保存好的文件名。
 下载好的文件如下图所示:(最终实现了解放双手, 很奈斯)
下载好的文件如下图所示:(最终实现了解放双手, 很奈斯)