B站刘二大人-Softmx分类器及MNIST实现-Lecture 9
系列文章:
《PyTorch深度学习实践》完结合集-B站刘二大人
Pytorch代码注意的细节,容易敲错的地方
B站刘二大人-线性回归及梯度下降 Lecture3
B站刘二大人-反向传播Lecture4
B站刘二大人-线性回归 Pytorch实现 Lecture 5
B站刘二大人-多元逻辑回归 Lecture 7
B站刘二大人-数据集及数据加载 Lecture 8
B站刘二大人-Softmx分类器及MNIST实现-Lecture 9
文章目录
- softmax分类器
- MNIST实现
-
- 导包
- 1-准备数据
- 2-设计网络模型
- 3-构造模型、损失函数、优化器
- 4-训练、测试
- 完整代码
softmax分类器


损失函数:交叉熵

Numpty中实现交叉熵损失函数
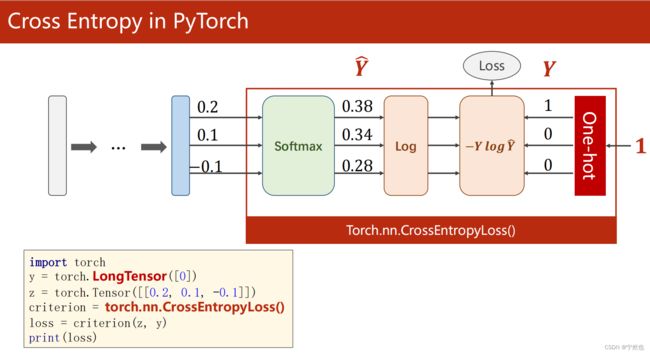
Pytorch实现的交叉熵损失


MNIST实现

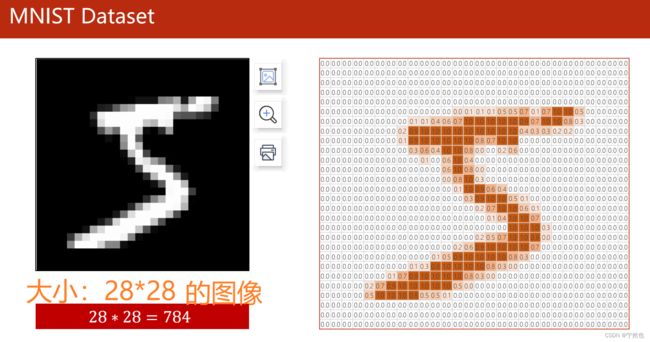


导包
import torch
from torch.utils.data import DataLoader
from torchvision import datasets,transforms
# 使用relu()
import torch.nn.functional as F
# 构造优化器
import torch.optim as optim
1-准备数据
# 1-准备数据
batch_size = 64
# 将PIL图像抓换为Tensor
transforms = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.1307,),(0.3081,))])
train_dataset = datasets.MNIST(root='./datasets/mnist', train=True,
transform=transforms,
download=False)
test_dataset = datasets.MNIST(root='./datasets/mnist', train=False,
transform=transforms,
download=False)
train_loader = DataLoader(dataset=train_dataset, batch_size=batch_size,
shuffle=True)
test_loader = DataLoader(dataset=test_dataset, batch_size=batch_size,
shuffle=False)
2-设计网络模型
# 2-设计网络模型
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.lay1 = torch.nn.Linear(784,512)
self.lay2 = torch.nn.Linear(512,256)
self.lay3 = torch.nn.Linear(256,128)
self.lay4 = torch.nn.Linear(128,64)
self.lay5 = torch.nn.Linear(64,10)
def forward(self,x):
x = x.view(-1,784)
x = F.relu(self.lay1(x))
x = F.relu(self.lay2(x))
x = F.relu(self.lay3(x))
x = F.relu(self.lay4(x))
x = F.relu(self.lay5(x))
return x
3-构造模型、损失函数、优化器
# 3-构造损失函数与优化器
model = Net()
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.005,momentum=0.5)
4-训练、测试
# 4-训练测试
def train(epoch):
running_loss = 0.0
# enumerate(train_loader, 0): batch_idx从0计数
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
optimizer.zero_grad()
# forward + backward + update
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if(batch_idx % 300 == 299):
print('[%d, %5d] loss: %.3f'%(epoch + 1, batch_idx + 1, running_loss/300))
running_loss = 0.0
def test():
correct = 0
total = 0
# 测试不需要生成计算图,不需要梯度更新、反向传播
with torch.no_grad():
# data是len =2的list
# input是data[0], target 是data[1]
for data in test_loader:
images, label = data
outputs = model(images)
# _ 是返回的最大值, predicted是最大值对应的下标
_, predicted = torch.max(outputs.data, dim=1)
total += label.size(0)
correct += (predicted == label).sum().item()
print('Accutacy on test set : %d %%'%(100*correct/total))
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()
关于:(predicted == label).sum()
会将predicted中的每个元素与对应位置的label进行对边,相同返回True,不同返回False。 .sum求的True的个数
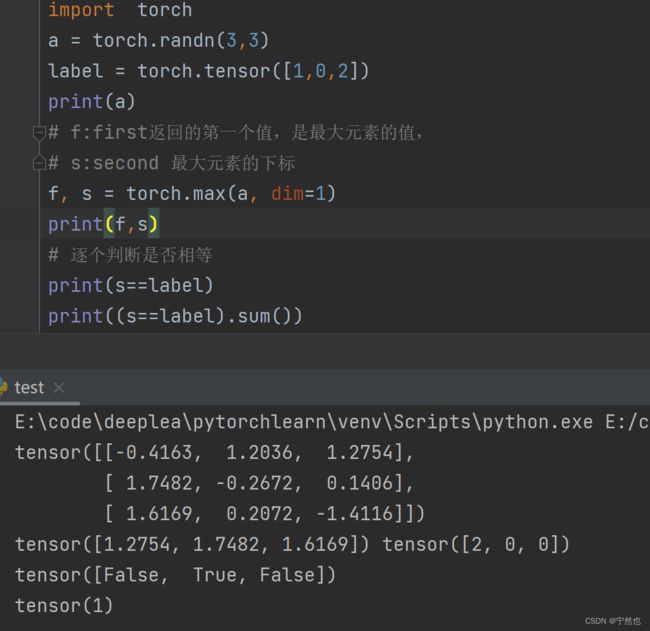
inputs, target = data 说明赋值情况

完整代码
import torch
from torch.utils.data import DataLoader
from torchvision import datasets,transforms
# 使用relu()
import torch.nn.functional as F
# 构造优化器
import torch.optim as optim
# 1-准备数据
batch_size = 64
# 将PIL图像抓换为Tensor
transforms = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.1307,),(0.3081,))])
train_dataset = datasets.MNIST(root='./datasets/mnist', train=True,
transform=transforms,
download=False)
test_dataset = datasets.MNIST(root='./datasets/mnist', train=False,
transform=transforms,
download=False)
train_loader = DataLoader(dataset=train_dataset, batch_size=batch_size,
shuffle=True)
test_loader = DataLoader(dataset=test_dataset, batch_size=batch_size,
shuffle=False)
# 2-设计网络模型
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.lay1 = torch.nn.Linear(784,512)
self.lay2 = torch.nn.Linear(512,256)
self.lay3 = torch.nn.Linear(256,128)
self.lay4 = torch.nn.Linear(128,64)
self.lay5 = torch.nn.Linear(64,10)
def forward(self,x):
x = x.view(-1,784)
x = F.relu(self.lay1(x))
x = F.relu(self.lay2(x))
x = F.relu(self.lay3(x))
x = F.relu(self.lay4(x))
x = F.relu(self.lay5(x))
return x
# 3-构造损失函数与优化器
model = Net()
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.005,momentum=0.5)
# 4-训练测试
def train(epoch):
running_loss = 0.0
# enumerate(train_loader, 0): batch_idx从0计数
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
optimizer.zero_grad()
# forward + backward + update
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if(batch_idx % 300 == 299):
print('[%d, %5d] loss: %.3f'%(epoch + 1, batch_idx + 1, running_loss/300))
running_loss = 0.0
def test():
correct = 0
total = 0
# 测试不需要生成计算图,不需要梯度更新、反向传播
with torch.no_grad():
for data in test_loader:
images, label = data
outputs = model(images)
# _ 是返回的最大值, predicted是最大值对应的下标
_, predicted = torch.max(outputs.data, dim=1)
total += label.size(0)
correct += (predicted == label).sum().item()
print('Accutacy on test set : %d %%'%(100*correct/total))
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()