GPT系列:Codex【使用GPT-3完成代码自动生成任务】
OpenAI Codex
Evaluating Large Language Models Trained on Code
- 根据函数名和注释自动补全代码
- 根据你写的代码,猜出你接下来可能要写的代码
- 自动补充测试样例
- 支持多种语言
- ....
总之,就是可以帮你写代码
简介
- 提出了一个新问题:代码补全
- 采用的解决方案是:将GitHub上采集到的Python代码作为数据集重新训练一下GPT-3,他就把这一套权重叫做Codex
- 一个值得注意的点:
- 代码补全这个任务的特殊性:具体来说,传统的NLP任务,生成的结果越接正确答案,那么模型得分越高,但是代码不是这样的,代码但凡有一点点小Bug,都可能造成毁灭性的结果。所以对于代码补全任务,判断生成代码的正确与否就是使用的单元测试(unit test)。---所以对于代码补全任务需要新的评估指标和数据集。
评估
评估指标---pass@k
NLP中最常见的评估方法是BLUE score(bilingual evaluation understudy)即:双语互译质量评估辅助工具。BLEU的设计思想:机器翻译结果越接近专业人工翻译的结果,则越好。BLEU算法实际上就是在判断两个句子的相似程度。想知道一个句子翻译前后的表示是否意思一致,直接的办法是拿这个句子的标准人工翻译与机器翻译的结果作比较,如果它们是很相似的,说明我的翻译很成功。
可以看出,BLUE score是一个模糊匹配的过程,意思大差不差就行。但是编程是一个比较特殊的问题,一个小的差别可能就会带来灾难性的影响(永无止尽的Bug Fix)。
针对代码补全这样一个特殊问题,作者提出了一个pass@k的一个指标,生成k个结果,只要有一个通过就算通过(k如果比较大,就会对模型的能力过度乐观,当k比较大的时候,虽然模型分数比较高,但是在使用时,会给用户返回一大堆代码,让用户去选,这个也是很难的,所以说需要排算法,但这个分数并没有反映排序)。
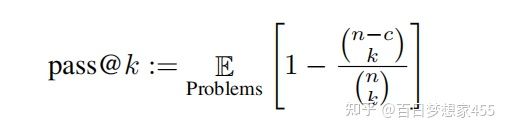
pass@k
n生成的候补答案总数,k每次选的答案,c代表能通过单元测试的答案(n=200,k<=100,c<=n)
评估数据集---HumanEval
HumanEval(Hand-Written Evaluation Set)包含164个人工设计的编程问题,每个问题包含函数名、注释、函数体、多个单元测试
手动实现是非常重要的:因为如果直接从网上找,比如说从leetcode上去扒,很有可能你的这个问题就在你在训练集里面(数据泄露)
模型
训练数据
从GitHub上收集到了179GB的Python代码。对文件进行简单的过滤(自动生成、平均长度大于100行、最大长度大于1000行、包含很少的字母/数字),最后得到159GB的Python代码文件
使用GPT-3训练得到Codex
用上面数据集在GPT-3的预训练模型上再训练一下得到了Codex
后面作者又收集了一个跟HumanEval更相近的训练集,在上面训练得到的模型叫Codex-S
作者有提到不管是在GPT-3的预训练模型训练,还是从头开始训练得到的模型,在精度上基本上没有差别。
但是在GPT-3的预训练模型训练收敛会更快一点
注意:
- 训练时,会对代码里的空格,换行进行处理
- 生成代码时,什么时候停止:遇到了 ‘\nclass’, ‘\ndef’, ‘\n#’, ‘\nif’, ‘\nprint’ 等就停掉代码
评估采样时,使用p=0.95的核采样(nucleus sampling):就是说将所有候补答案,按概率从高到低排序,依次拿出来,指导所有选出来的候补的概率和大于0.95,就停止采样。
结果
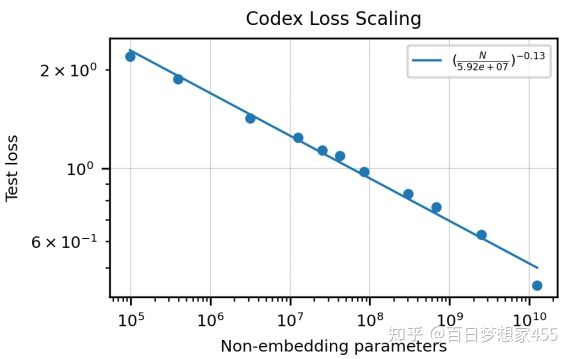
模型大小和损失之间的关系
模型大小和损失之间的关系:模型参数指数级上升时,损失线性下降
作者在算softmax前,会除以某一个T。T较大时,各个候选的概率比较相近,T较小时,各个候选的概率分的比较开。如果用一个较小的T,最好的几个候选,概率较大,采样的时候总能把最好的几个取出来,如果用一个较大的T,不是最好的几个候选也能被采样出来
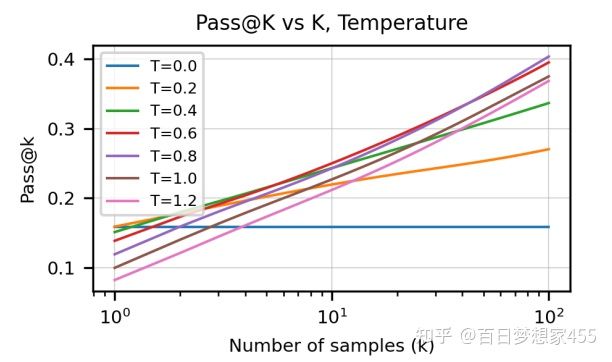
采样次数和T之间的关系:不同的T,随着采样次数的增加,pass@k的变化

反映不同采样次数下最好的T:随着允许采样的数目增加,最好的T越大(假如说我只允许你选一个,那么你最应该选择出最好的候选答案,那就对应比较小的T)
下图反映不同排序算法(从生成的k的答案里面选出最好的):Oracle代表使用了先验(就是把取出来的k的候选,放到单元测试上测一下,选择能通过的候选出来),那么明显随着k增大,通过率越高。

不同排序算法
关于BLUE score:作者在HumanEval的4个随机任务上测了BLUE score,可以看出,BLUE分数的高低与答案正确并没有直接关系,也印证了作者前面说的不能使用BLUE score的原因
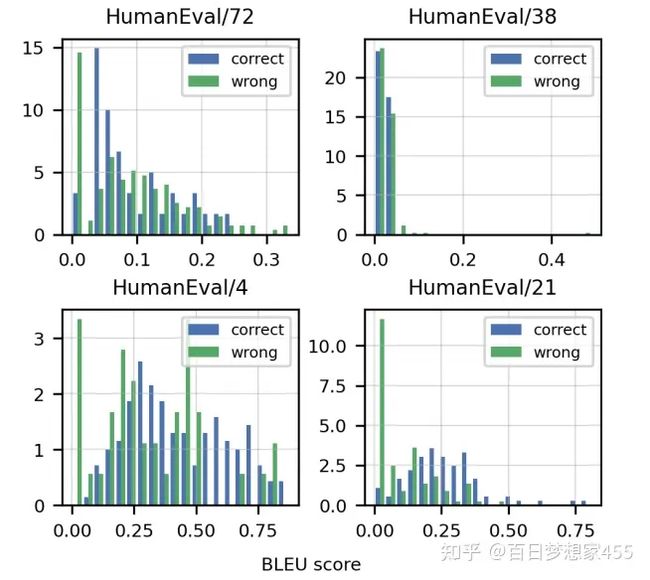
验证BLUE score是否有效
Codex和GPT-NEO、GPT-J、TABNINE的性能对比
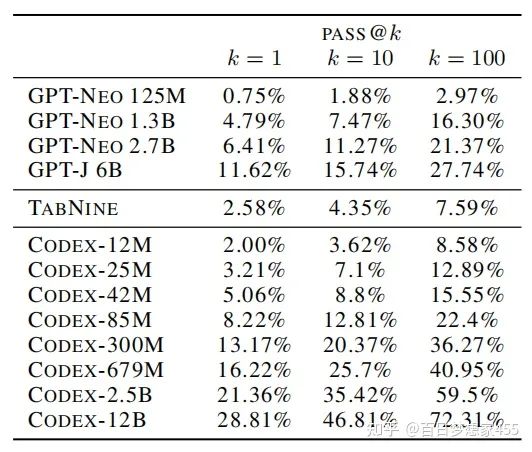
与不同方法的对比
Codex-S
使用跟HumanEval更相近数据集作为的训练集,在上面训练得到的模型叫Codex-S
HumanEval(Hand-Written Evaluation Set)包含164个 人工设计的编程问题,每个问题包含函数名、注释、函数体、多个单元测试
得到训练集的方法:
- 程序竞赛的题目
- CI里面拿
- 过滤:使用Codex-12B生成100个候选答案,如果其中至少有一个能通过单元测试,就把问题留下来,否则,作者觉得可能是这个问题的单元测试不正确,或者问题太复杂(作者认为太难的问题对模型训练没有太大帮助),就过滤掉
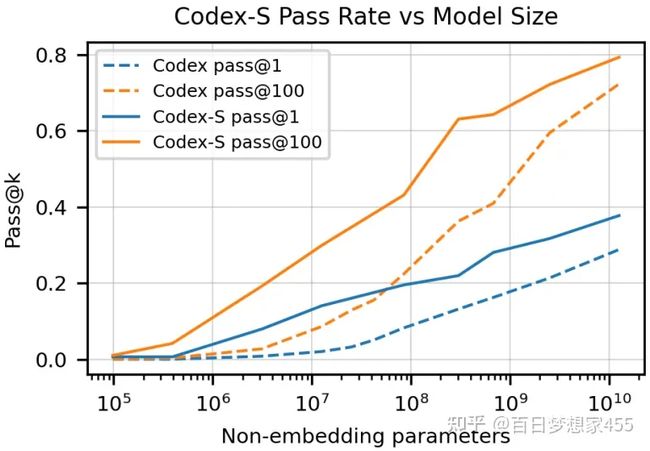
Codex-S和Codex间在模型增大时,pass@k的分数:实线Codex-S,虚线就是Codex

Codex-S和Codex不同使用排序算法间的差别
另外的应用---生成文档(Codex-D)
数据集调整:把docstring放到最后面(函数名和函数体后面)
使用这样数据集训练得到的模型叫Codex-D
判断生成的docstring是否合格:
- 眼睛去看
- 先用Codex-D生成docstring,再用docstring和函数名生成函数体,如果代码能过单元测试,则认为生成的docstring质量很高
局限性
- 样本有效性不够(使用100G的代码去训练得到的模型只能处理比较简单的代码任务)
- 受注释影响较大
- 做数学相关的代码比较差

处理简单数学问题的示例
可能影响
- 过度依赖模型生成的代码
- 模型可能能生成你想要的答案,但是他会按照训练数据集的风格去写,可能跟你想要的风格不一样
- 偏见(GitHub男性用户较多)
- 程序员失业(感觉作者有点杞人忧天)
- 模型经常使用一些特定的包,可能导致其他的包使用概率下降(比如openai自己开发一个深度学习框架,让Codex生成的代码都用这个框架,如果这个模型比较火,那么可能就没有TensorFlow PyTorch的生存空间了)
- 安全问题(使用Codex写病毒)
- 环境问题(模型训练耗电)
- 法律(爬GitHub上的代码训练模型可能会有法律问题?生成的代码可能会有抄袭问题,且这种问题用户还不知道)
总结
说白了就是,作者把GitHub上的Python代码爬爬下来,用GPT-3训练了一个模型(Codex),发现可以解决部分代码问题,为了能解决更多问题(把通过率刷上去?),又收集了一个跟测试集(HumanEval)更近似的数据集训练得到(Codex-S),然后作者觉得只生成代码没意思,又把数据集里的docstring放到函数名和函数体后面得到一个新的数据集,训练得到(Codex-D)
这篇论文在模型上并没有什么创新,主要就是提出了一个新的问题(代码生成,后续有很多相关工作,比如说AlphaCode),然后就是花精力收集数据集甚至更好的数据集。
参考资料
Codex 官网:OpenAI Codex
Codex paper:Evaluating Large Language Models Trained on Code
Copilot 官网(Codex的实际应用):GitHub Copilot · Your AI pair programmer
沐神讲解Codex:OpenAI Codex 论文精读【论文精读】哔哩哔哩bilibili
TabNine官网:Code Faster with AI Code Completions | Tabnine
AlphaCode paper:Competition-Level Code Generation with AlphaCode
Codex: 使用GPT-3完成代码自动生成任务 - 知乎