Win10+YOLOv4/v3用yolo_mark标记数据集 训练自己的模型
Win10+Yolov4用yolo_mark标记数据集 训练自己的模型
文章目录
- 1. 前言
- 2. darknet
- 3. yolo_mark
-
- 3.1 yolo_mark和opencv的下载
- 3.2 yolo_mark 的编译
-
- 3.2.1 项目重定向
- 3.2.2 修改为release
- 3.2.3 配置opencv路径
- 3.2.4 重新生成项目
- 3.2.5 打开图片标记软件
- 3.3 用yolo_mark标记自己的图片
- 4. 模型训练
-
- 4.1 darknet的配置
- 4.2 开始训练
- 5. 其他
-
- 5.1 暂停训练和恢复训练
- 5.2 训练时打印的日志部分含义
- 5.3 测试训练
- 6. 结语
1. 前言
本文是YOLO教程的第二个模块:在Win10下标记并训练自己的数据集。
第一个模块为:用VS2019 + CUDA搭建YOLOv4/v3环境。点击这里可以直接跳转至第一篇文章。
关于训练自己的数据集的博客,这段时间我也看了很多很多。但是绝大部分博客是在Ubuntu系统进行的训练,很少部分是在Win10上进行的。
此外,关于图片的标记,绝大部分博客是采用的先生成xml文件,再通过python代码转换为txt文件,稍微有点麻烦。但是在我们可以使用yolo_mark来标记,直接生成txt文件,相对更简单。
2. darknet
darknet的下载、编译等,我已经在上一篇文章写得很清楚了,就不再赘述了。
3. yolo_mark
3.1 yolo_mark和opencv的下载
-
首先先进入yolo_mark的GitHub下载地址,下载yolo_mark。下载之后解压的熟悉的位置。在其README.md文档中也有其他详细的说明
-
opencv的下载和配置可以借鉴我这篇博客中的opencv下载部分。建议下载
opencv3.4版本(Yolo_mark支持OpenCV 2.x 和 OpenCV 3.x)
3.2 yolo_mark 的编译
在编译之前,需要一些基本的配置,配置流程如下
3.2.1 项目重定向
进入到 …\Yolo_mark-master 文件夹,用VS2019打开 yolo_mark.sln。
进入后有一个重定向项目属性,改成如图所示的配置。

3.2.2 修改为release
修改项目为Release

3.2.3 配置opencv路径
-
(右键单击项目) ⇒ \Rightarrow ⇒ 属性 ⇒ \Rightarrow ⇒ C/C++ ⇒ \Rightarrow ⇒ 常规 ⇒ \Rightarrow ⇒ 附加包含目录: 将
C:\opencv_3.0\opencv\build\include修改为自己的的opencv路径 -
(右键单击项目) ⇒ \Rightarrow ⇒ 属性 ⇒ \Rightarrow ⇒ 链接器 ⇒ \Rightarrow ⇒ 常规 ⇒ \Rightarrow ⇒ 附加库目录:
C:\opencv_3.0\opencv\build\x64\vc14\lib修改为自己的的opencv路径
(上方操作如下图所示)



记得点确定!!!!
上图为C/C++的修改,下方的链接器修改同理。修改结束后记得点确定
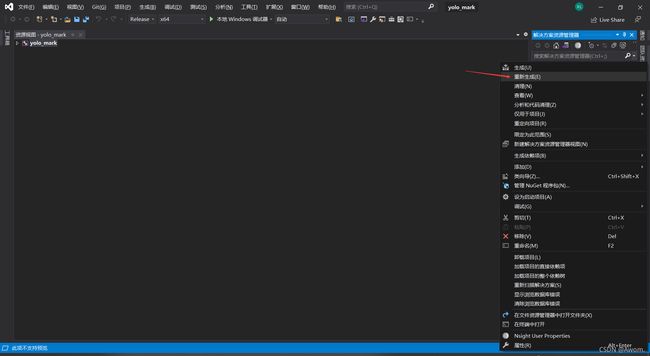
3.2.4 重新生成项目
右键项目,点击如图所示的重新生成,即可编译得到yolo_mark.cmd,yolo_mark.exe等。
此时我们进入opencv安装的目录..\opencv\build\x64\vc14\bin,选择opencv_world340.dll和opencv_ffmpeg340_64.dll两个文件,复制到yolo_mark的..\Yolo_mark-master\x64\Release路径下。
3.2.5 打开图片标记软件
完成上述操作之后,进入 …\Yolo_mark-master\x64\Release ,双击 yolo_mark.cmd (而不是exe文件) ,即可打开标记软件。

3.3 用yolo_mark标记自己的图片
图片是yolo_mark自带的默认的图片,而且是已经被标记过了。所以我们要把图片换成自己的图片。
-
进入到 …\Yolo_mark-master\x64\Release\data 中,可以看见1个文件夹img。该文件夹是用来存放需要被标记的图片和标记后生成的txt文件的地方。所以我们要把里面的文件全部删掉,并把自己的图片数据集放入进去。为了方便,我们将它们命名为 1.jpg, 2.jpg, 3.jpg … (如果太麻烦了可以在CSDN上找到python写的一键重命名的代码)
-
打开obj.data。第一行的classes就是你的类数量。比如我只想训练1个类person,我就把它改成 classes = 1。
-
打开obj.names。里面是你的类的名称。我因为只有一个person,所以就只写入个person就够了。如果你需要写入多个类,一行写入一个。
-
回到 …\Yolo_mark-master\x64\Release,运行yolo_mark.cmd 运行标记软件。之后就可以开始标记了。标记时,拖动 object id 可以更换标记类型。
如图所示标记 -
标记快捷键如图

其实只要进去按一下h就可以知道所有快捷键了(记得切换输入法,不然无法识别快捷键)
4. 模型训练
4.1 darknet的配置
-
移动文件
因为用yolo_mark标记后得到的数据 (txt文件) 是存在yolo_mark的data文件中的,所以我们就需要将data文件夹的东西拷贝到darknet的data文件夹下。
进入yolo_mark的 …\Yolo_mark-master\x64\Release\data 路径和 darknet的 …\darknet-master\build\darknet\x64\data 路径,并将 yolo_mark的data 文件夹下的所有文件拷贝至 darknet的data 文件下。
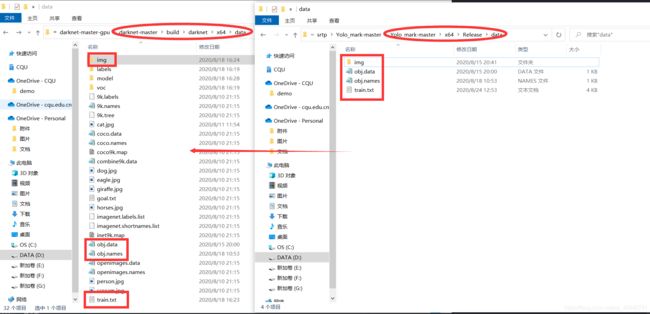
移动文件
剩余的部分我们可以直接参考作者AlexeyAB的YOLOv4 readme文档即可,我简单的翻译了文档中关于训练自己模型的部分,也加入了部分我自己的补充,点击博客地址可跳转;此外点击此处即可跳转README的How to train英文原版。
4.2 开始训练
一切配置好之后,就可以正式开始训练了。在 darknet-master\build\darknet\x64 下,空白处 ,shift + 右键,选择 在此处打开Powershell窗口
输入:
./darknet.exe detector train data\obj.data yolo-obj.cfg data\darknet53.conv.74
就可以开始训练了

训练会生成weights权重文件,生成在 \darknet-master\build\darknet\x64\backup 处。
生成的weights文件的文件名是yolo-obj_last.weights,即最后一次生成的weights文件。该文件每迭代100次会更新一次。
此外,每迭代1000次会额外再次生成一个weights文件,如yolo-obj_2000.weight。其他每迭代1000次,迭代10000次命名依次类推。

5. 其他
5.1 暂停训练和恢复训练
暂停训练:单击一次powershell框;恢复训练:键盘任意键
5.2 训练时打印的日志部分含义

4 :总迭代了的次数
1095.689575 :总体的Loss(损失)
1096.312134 avg loss : 平均的Loss
0.000000 rate :代表当前的学习率,是在.cfg文件中定义的
22.428000 seconds : 训练当前批次所花费的时间
256 images :到目前位置,参与学习了的图片的数量
3068.354482 hours left :到训练结束(默认训练迭代500200次),还需要的时间
没有比较训练这么多次,当Loss为零点几的时候,已经可以推出训练了。其他英文的具体含义也很容易找到,我这里就不多赘述了。
5.3 测试训练
测试训练的时候需要注意!需要使用正确的命令。因为不同教程,把文件放在不一样的目录,所以使用的命令是有区别的。
- 如果是要识别视频文件,则命令格式为
.\darknet.exe detector demo <.data文件位置> <.cfg文件位置> <权重文件位置> <识别文件位置>
- 如果是识别图片,则命令格式为
.\darknet.exe detector test <.data文件位置> <.cfg文件位置> <权重文件位置> <识别文件位置>
- 此命令需要在x64位置打开Powershell,如果是cmd则把
.\darknet.exe切换成darknet.exe;- 如果为指定识别文件位置,则命令1会调用摄像头,命令2会让你多次输入图片路径,进行多次识别;
- <>需要替换成相应的相对路径路径
6. 结语
写这篇博客很重要的一个原因是,CSDN上,训练的教程多是Ubuntu下的,而且也不是使用的yolo_mark,大都是xml转txt,而且一些操作也很繁琐。对于像我这样的低年级学生,才刚刚想尝试入门的,不太友好。
所以我希望我写的这篇博客,能够帮助到各位,少踩点坑,少一点麻烦吧~
如果能帮到你,不如点个赞吧~
