3 北京超算云计算平台深度学习环境配置笔记
点击链接https://cloud.blsc.cn/进入网页版或下载客户端,使用北京超级云计算中心账号登陆
1.SSH到服务器
点击页面上的SSH进行远程连接,点击连接后进行命令行界面
进入run目录下,run目录下有300G的内存,可以把数据和代码等各种资料存到里面
cd run
2. 创建环境
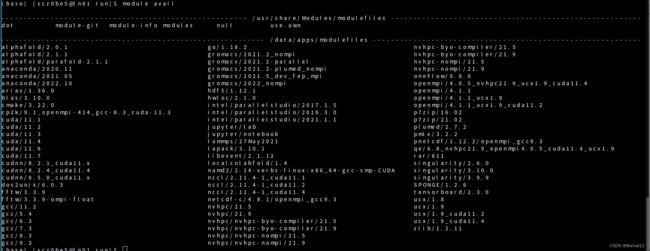
首先在命令行输入,查看预先安装的工具
module avail
安装anaconda 2021.05版本
module load anaconda/2021.05
创建一个python环境
conda create --name mmclassification python=3.8
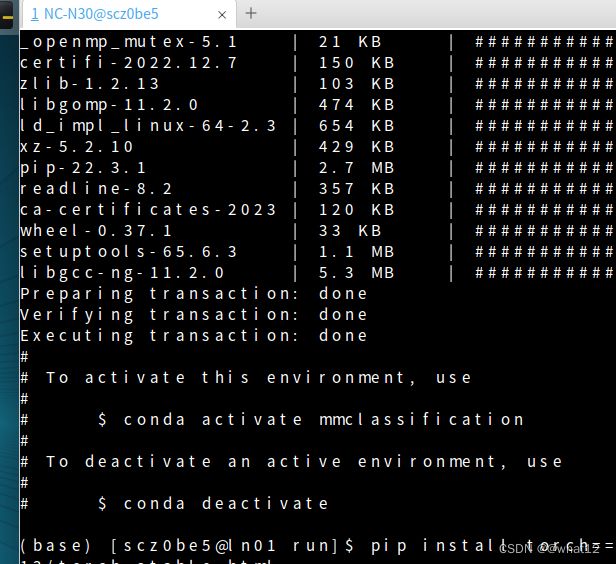
激活环境
source activate mmclassification
安装pytorch工具,超算3090显卡支持的最低版本为cuda11.1,要安装cuda11.1以上版本
pip install torch==1.10.0+cu111 torchvision==0.11.0+cu111 torchaudio==0.10.0 -f https://download.pytorch.org/whl/torch_stable.html

查看预先安装的工具
module avail
加载cuda/11.1
module load cuda/11.1

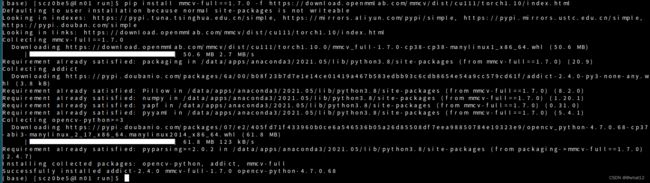
安装MMCV
pip install mmcv-full==1.7.0 -f https://download.openmmlab.com/mmcv/dist/cu111/torch1.10/index.html
安装mmclassification
新建文件夹openmmlab和mmclassification
mkdir openmmlab
mkdir mmclassification
进入openmmlab文件夹下载mmclassification
cd openmmlab
git clone https://github.com/open-mmlab/mmclassification.git
进入~/run/mmclassification/文件夹下
cd ..
cd mmclassification/
复制~/run/openmmlab/下文件夹mmclassification到当前文件夹下
cp -r ~/run/openmmlab/mmclassification/ ./

 然后进入目录里面来,即 ~/run/mmclassification/ mmclassification/目录下
然后进入目录里面来,即 ~/run/mmclassification/ mmclassification/目录下
cd mmclassification/

查看gcc版本gcc --version
加载gcc/7.3
module load gcc/7.3
进行编译安装,需要的依赖包也会自动安装
pip install -e .
查看软件包
pip list

至此安装完成
3. 整理 flower 数据集
新建一个data文件夹,即 ~/run/mmclassification/ mmclassification/data
mkdir data
下载数据集使用快传拖拽放到 ~/run/mmclassification/ mmclassification/data目录下
进入data并解压
cd data
unzip flower_dataset.zip
a.将数据集按 8:2 的比例划分成训练和验证子数据集,并将数据集整理成 ImageNet 的格式,通过 Python 或其他脚本程序完成
复制脚本代码到当前目录下,即data目录
cp ~/run/openmmlab/data_split.py ./
划分数据集时,使用绝对路径,输入pwd查看
python data_split.py /HOME/scz0be5/run/mmclassification/mmclassification/data/flower_dataset /HOME/scz0be5/run/mmclassification/mmclassification/data/flower
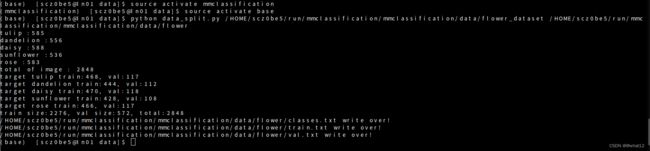
查看flower目录下的文件
ls flower

回上一级目录,新建configs/resnet18文件夹,复制配置文件~/run/openmmlab/resnet18_b32_flower.py到当前文件夹下
cd ..
mkdir configs/resnet18
cp ~/run/openmmlab/resnet18_b32_flower.py ./
b.将训练子集和验证子集放到 train 和 val 文件夹下
文件结构如下:
flower_dataset
|---类.txt
|---火车.txt
|---瓦尔.txt
| |---火车
| | |---雏菊
| | | |---名称1.jpg
| | | |---名称2.jpg
| | | |--- ...
| | |---蒲公英
| | | |---名称1.jpg
| | | |---名称2.jpg
| | | |--- ...
| | |---玫瑰
| | | |---名称1.jpg
| | | |---名称2.jpg
| | | |--- ...
| | |---向日葵
| | | |---名称1.jpg
| | | |---名称2.jpg
| | | |--- ...
| | |---郁金香
| | | |---名称1.jpg
| | | |---名称2.jpg
| | | |--- ...
| |---
| | |---雏菊
| | | |---名称1.jpg
| | | |---名称2.jpg
| | | |--- ...
| | |---蒲公英
| | | |---名称1.jpg
| | | |---名称2.jpg
| | | |--- ...
| | |---玫瑰
| | | |---名称1.jpg
| | | |---名称2.jpg
| | | |--- ...
| | |---向日葵
| | | |---名称1.jpg
| | | |---名称2.jpg
| | | |--- ...
| | |---郁金香
| | | |---名称1.jpg
| | | |---名称2.jpg
| | | |--- ...
c. 创建并编辑标注文件将所有类别的名称写到 ‘classes.txt’ 中,每行代表一个类别。
d. 生成训练(可选)和验证子集标注列表 ‘train.txt’ 和 ‘val.txt’ ,每行应包含一个文件名和其对应的标签。样例:
...
雏菊/姓名**.jpg 0
雏菊/姓名**.jpg 0
...
蒲公英/名称**.jpg 1
蒲公英/名称**.jpg 1
...
玫瑰/姓名**.jpg 2
玫瑰/姓名**.jpg 2
...
向日葵/名称**.jpg 3
向日葵/名称**.jpg 3
...
郁金香/名称**.jpg 4
郁金香/名称**.jpg 4
为了节约线上时间,这个过程可以在本地完成。
整理完成后,将处理好的数据集迁移到 'mmclassification/data ’ 文件夹下。
4.构建模型微调的配置文件
使用 ‘base’ 继承机制构建用于微调的配置文件,可以继承任何 MMClassification 提供的基于 ImageNet 的配置文件并进行修改。
5.修改模型配置
修改分类头,将模型适应为 flowers 中的数据类别数。
6.修改数据配置
修改训练和验证集的数据路径,数据集标注列表,以及类别名文件路径。
将评估方法修改为仅使用 top-1 分类错误率。
7.学习率策略
微调一般会使用更小的学习率和更少的训练周期。因此请在配置文件中修改学习率和训练周期。
8.配置预训练模型
从 Model Zoo 中找到原配置文件对应的模型文件,并下载到平台或本地环境中,通常放置在 ‘checkpoints’ 文件夹中。
在配置文件中配置预训练模型的路径,完成 finetune 训练。
9.使用工具进行模型微调
使用 ‘tools/train.py’ 进行模型微调,并通过 ‘work_dir’ 参数指定工作路径,该路径中会保存训练的模型。调整参数,或使用不同的预训练模型,尝试获得更高的分类精度。