如何搭建KBQA系统 —— 初识KBQA(一)
如何搭建KBQA系统 —— 初识KBQA(一)
前言
最近做了KBQA的项目,个人完整的负责并参与了设计和技术实施,所谓“完整”包含图谱建设和问答系统的建设,也对KBQA也有更高一层的认识,故希望把过程中能分享的技术和经验进行总结。图谱建设阶段是一个极其耗费人工和强依赖业务定义的过程,图谱质量直接影响了后续问答返回结果的质量。当然问答系统也是强依赖业务,还需要高精度的pipeline,一环扣一环,有时必须在召回和精度之间取平衡。
完完整整落地一个知识图谱的问答系统不是易事,开始搭建KBQA之前得确定几个问题:
- 是否需要QA,或者是否需要KB;
- 项目是否有足够的时间和资源去折腾;
- 是否有足够丰富的数据,丰富是指数据类型多样、数据量大;
- 是否对业务足够了解;
- 是否是一次性成果,后期有无迭代机会;
产品满足用户需求有多种方式,问答只是解决问题的其中一种,无论什么方式,其目的都是一致的,都是为了满足用户需求。在现实互联网产品中,问答系统随处可见,例如智能驾驶、智能催收、智能营销、电商智能客服等,但是它们在用户心中认可度有多少,也就是说它能解决多少用户的问题,可能很多少人像我一样,点击客服按钮,直接输入“人工”。所以在产品设计之前就要明确是真实需要QA,而不是为了有而有去“秀肌肉”。
往往很多人都觉得市面上QA遍地开花,图谱技术也有吹到了天际,就想当然的认为这些不存在技术壁垒。首先不得不承认,现在问答(例如Rasa)和图谱技术都相对成熟了,但是完完整整的复制到自己的垂直领域下,很多时候不得不从头再来,好在于很多技术点是已经在业界取得良好的效果,可开箱即用,有了技术还不够,还要在垂直领域下依据业务设计问答系统,主要是限定问答边界,哪些可以回答,哪些我不能回答,最后你得需要花大量的精力和大量的数据去折腾出一张知识图谱。
“如何搭建KBQA系统” 系列文章,我会遵循技术理论和真实项目实践去撰写,尽量做到每一个技术点有理论支撑,以项目实践去论证可行性,该系列文章将会分为以下几个篇章:
- 如何搭建KBQA系统 —— 初识KBQA(一)
- ( 内容随时更新,敬请期待 ~ )
问答系统
问答系统(Question Answering System,QA)是理解人类自然语言、管理对话状态并做出回复决策的系统,它在现实生活中并不陌生,也在某些场景方便了人类的生活方式,例如你现在就可以唤醒身边的“siri”、“小爱同学”等和它们对话。现在也有很多AI机器人公司,他们既有成熟的技术,更有成熟的商业模式和产品,自能问答领域可谓是一篇红海。

问答系统分类
问答系统按照领域可以分为公共领域和垂直领域,公共领域例如百度百科上的问答,而垂直领域受限行业知识和行业数据,一般是需要依据业务定制化开发,但是企业内业务繁多、系统数据复杂,起初AI机器人开发商会让技术人员定制化开发,这会面临一个头痛得问题,技术人员不仅要面对技术问题,更要了解繁琐的业务流程。所以神奇开发商就思考能不能让把某些问答模块通用化,例如机器人都需要意图识别组件、实体识别组件等,然后提供一个可“拖拉拽”的界面让不会撸代码的企业员工也能手动配置一套问答系统,我了解到相关产品facebook、Microsoft Azure。
![]()
问答系统另一种划分是按照其能力划分,可分为闲聊型、限定领域型(FAQ、KBQA等)、任务型(多轮对话)。
| 类型 | 说明 | 应用 |
|---|---|---|
| 闲聊型 | 与机器进行开放的问答,目的是增加用户粘性和系统智能程度 | 微软小冰、Siri |
| 限定领域型 | 具有业务和垂直领域的知识问答,可以是常见问答或者基于知识库检索的问答 | 电商客服 |
| 任务型 | 一般以多轮问答形式,当用户表意不清或信息缺失的情况,一步步引导用户得到最终的答案 | watson |
并不是每一个机器人都应该具备三种类型功能,根据领域、行业、用户的不同,来确定机器人应该具备哪些功能,应该优化到什么样的程度,当然也需要考虑项目规模、投入成本、用户访问量等因素。
问答系统技术架构
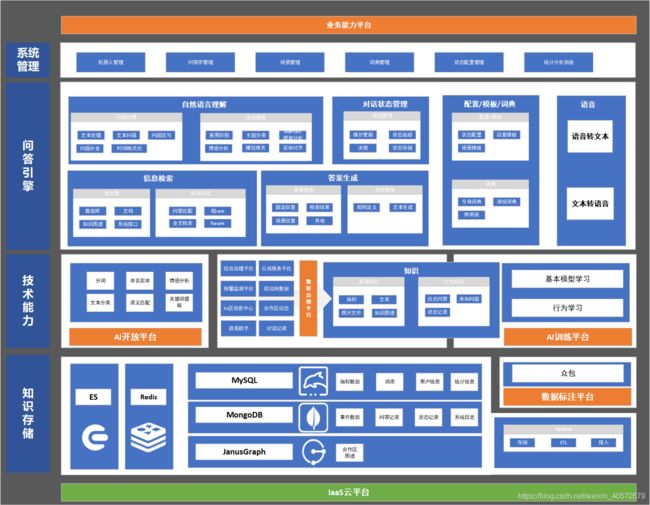
问答系统涉及广泛的技术,在知识存储过程中,需要按照问答类型设计数据存储方式,也要对数据库做好选型,业务数据一般情况下是不满足问答系统的数据格式,此时需要花费大量精力在数据治理和处理过程中,例如知识图谱需要定义本体、schame、入图格式等。
技术能力是问答系统性能和开发速度的关键,向上提供技术服务,向下提供数据治理能力。
没有统一的问答引擎架构,但是大多数都会有自然语言理解、对话管理、答案检索、答案生成等模块,内部的子模块和逻辑各有不同。但是低耦合的模块设计,让系统更容易进行扩展和维护。
KBQA
言归正,回到主题,到底什么是KBQA呢?
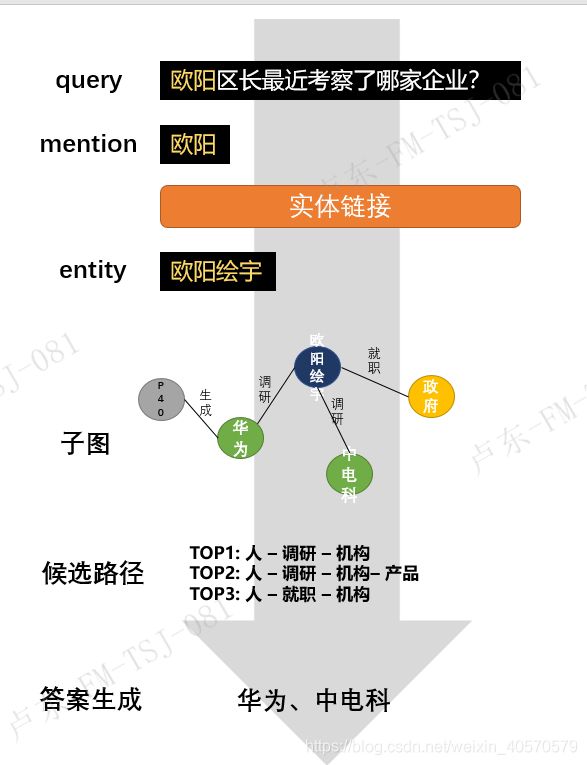
KBAQ(Knowledge-based Question Answering)称为基于知识库的问答系统,有些文章也称为KGQA(Knowledge graph Question Answering),通俗解释是用户输入问句(query),系统提取query中实体和关系到知识谱图中检索符合的答案,答案是图谱中的节点、关系、属性。
术语
一般你可能关注以下几个术语,这些术语在论文中大量出现,有写术语意思相似且容易混淆,例如“实体提及”和“实体”。
| 术语 | 说明 |
|---|---|
| 实体提及 (mention) | query中提取的短语,可能是实体或者词 |
| 实体 (entity) | 指存储在图谱中的节点,需要和mention做映射 |
| 关系(relation) | 指一般是指图谱中的边,有时候关系约等于谓语 |
| 谓语(predicate) | 指在query中出现的谓词 |
| 上下位关系(Hyponymy and hypernymy) | 上位关系(上位词):“牛” 的上位词是“动物”;下位关系(下位词):“牛”的下位词是“黄牛” |
| 跳(skip) | 图中节点固定方向出现边的次数,例如“节点 - 关系 - 节点”称为一跳,“节点 - 关系 - 节点 - 关系 - 节点”称为二跳 |
| 路径(path) | 图中从某一个节点 (起始节点)到另一个节点(结束节点)经过的节点 |
| 度(degree) | 图中某个节点所包含的边,“度”包括“出度”和“入度”,因为图谱关系一般是具有方向的 |
实体(entity)和实体提及(mention)
实体提及识别和提取阶段和实体对齐阶段会大量出现“mention”专业名词,初学者会比较陌生。抛开知识图谱的范围,可以说它两的意思差不多。值得注意“mention”是来至于query,“enttiy”来自于图谱,“mention”需要和“entity”作对齐的工作。
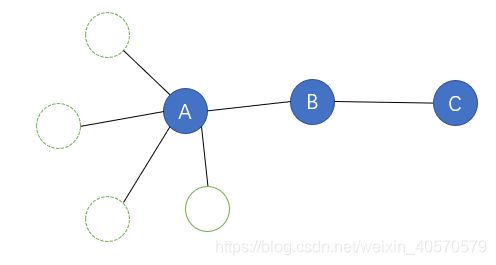
跳(skip)、度(degree)和路径(path)
刚开始接触知识图谱的人会对跳(skip)、度(degree)、路径(path)比较陌生,以下用图例可以较为生动形象的展示。对于A节点度数为5,因为有5个节点和它相连;A节点到B节点称为一跳,A节点到C节点称为二跳;A节点到C节点的路径为“A - B - C”。
技术总结
KBQA在技术上可以分成两种方案,分别是一种是语义解析方式,第二种信息检索方式方法。语义解析是把问题解析出句法成分、逻辑组合、关系、实体等,然后转为知识库上的查询语句,这种方法优点是有较高的精度,但是需要定义大量的规则,人工量成本较高,并且低召回。
而信息检索方式以实体在知识库上召回较多的候选路径,通过语义匹配的方式对候选路径进行重排序,从而选择最优的路径作为答案,所以信息检索方式具有较高泛化性。这样的方式一般需要以下几个组件:
- 问题预处理、清洗
- 实体提及(mention)识别和权重计算
- 实体对齐(或实体链接),涉及实体召回和实体排序两个过程
- 候选路劲生成,实体到知识库查询N跳子图,进行路径打分过程对候选路径排序
- 答案生成,一般是启发式定义返回结果
问题处理和清洗包括正繁体转换、全角半角转换、表情符号处理等,有些特殊处理情况依据业务而定。
mention处理方法一般包括分词、命名实体识别、正则表达式,有些系统会对mention进行打分、排序,目的是为了减少召回实体的数量。
实体链接是使用mention链接到知识库的实体,实体链接通常做法会使用链接词典,这是最实际、最稳健的做法,当然也会使用一些模型算法提高实体召回,也会对实体进行排序,目的是为了减少候选路径的召回数量。
候选路径生成指的是利用实体到知识库查到实体的子图,所有节点到节点之间的连线就是候选路径,对于属性图而言,属性也可以看成一种特殊的节点。路径排序是使用问题和路径计算相似度,相似度按高低对路径排序,一般而言,最后我们会返回top1的路径作为答案路径。
答案生成是依据问题分类定义的各种规则,不同的问题类型会采用不同的返回结果策略。
举个例子更好理解:
论文浅读
全国知识图谱与语义计算大会(CCKS: China Conference on Knowledge Graph and Semantic Computing)是国内著名的关于知识图谱和自然语言处理技术的会议,首先声明我没有打广告,以下所列的都是CCKS论文的原因是本人当时主要参考了会议评测中一些优秀选手的方案,所以一切都是偶然。当然也阅读了大量国外的优秀KBQA论文,有兴趣可以在引用中查阅。
我之所以选择展示CCKS KBQA 论文,是因为每年的评测任务稍微固定,虽然论文结构和细节简洁,但是技术框架基本保持一致,不同作者只是在不同组件加入了自己独特的想法,创新点不在于技术框架的更新,而在于组件内部策略的魔改。
综上所述,CCKS对于小白十分友好,以下论文都是使用信息检索方法。
CCKS2018
1. A Joint Model of Entity Linking and Predicate Recognition for Knowledge Base Question Answering


CCKS2019
1. 混合语义相似度的中文知识图谱问答系统

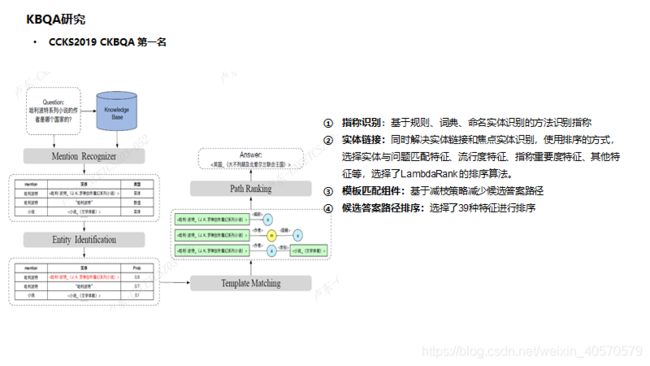
2. Multi-Module System for Open Domain Chinese Question Answering over Knowledge Base

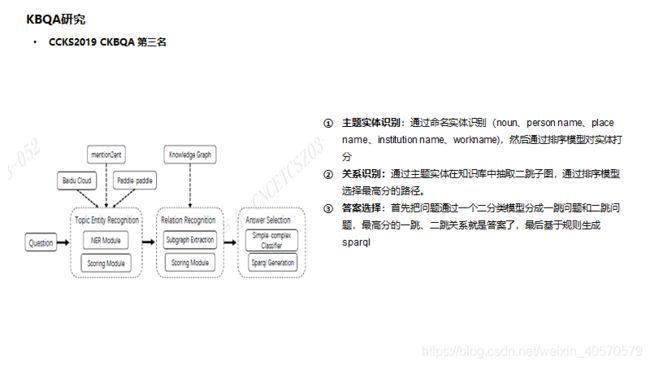
3. DUTIR 中文开放域知识库问答评测报告


CCKS2020
1. 基于特征融合的中文知识库问答方法


1. 基于预训练语言模型的检索-匹配式知识图谱问答系统

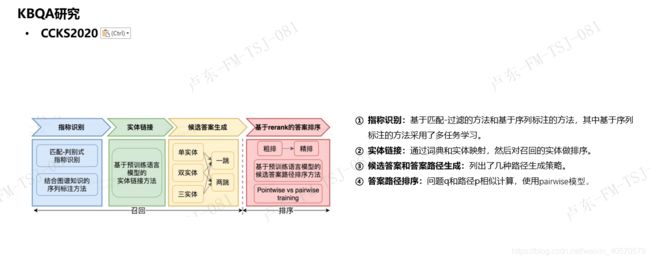
参考
- Cui, W., Xiao, Y., Wang, H., Song, Y., Hwang, S.W., Wang, W.: Kbqa: Learning
question answering over qa corpora and knowledge bases (2019) - Dai, W., Liu, H.,Liu, Y., Lv, R., Chen, S.:An Integrated Path Formulation Method for Open Domain Question Answering over Knowledge Base (2020)
- Zhang, H., Xiong, D.: One Model Structure for All Sub-Tasks KBQA System (2020)
- Lan, Y., Jiang, J.:Query Graph Generation for Answering Multi-hop Complex Questions from Knowledge Bases (2020)
- Yih, W.,Richardson, M., Meek, C., Chang, M., Suh, J.:The Value of Semantic Parse Labeling for
Knowledge Base Question Answering (2016)
下一篇,介绍如何构建一个知识图谱(属性图),来源于实战项目中的经验!