学习Numpy,看这篇文章就够啦

导读:在数据分析当中,Python用到最多的第三方库就是Numpy。本文内容是「大数据DT」内容合伙人王皓阅读学习《Python 3智能数据分析快速入门》过后的思考和补充,结合这本书一起学习,效果更佳。
作者:王皓
来源:大数据DT(ID:hzdashuju)

01 ndarray创建与索引
在学习Numpy之前我们需要了解一个概念:数组维数。
在计算机科学中,数组数据结构(array data structure),简称数组(Array),是由相同类型的元素的集合所组成的数据结构,分配一块连续的内存来存储。按数组维数分类可分为:一维数组、二维数组、多维数组(N维数组)。

Numpy是最著名的 Python库之一,常用于高性能计算。Numpy提供了两种基本对象:ndarray和ufunc。
NumPy作为一个开源的Python科学计算基础库,包含:一个强大的N维数组对象ndarray ;广播功能函数 ;整合C/C++/Fortran代码的工具 ;线性代数、傅里叶变换、随机数生成等功能。NumPy是SciPy、Pandas等数据处理或科学计算库的基础。
当然这里就有一个问题出现了,Python已有列表类型,为什么需要一个数组对象(类型)?
因为:
数组对象可以去掉元素间运算所需的循环,使一维向量更像单个数据
设置专门的数组对象,经过优化,可以提升这类应用的运算速度,在科学计算中,一个维度所有数据的类型往往相同
数组对象采用相同的数据类型,有助于节省运算和存储空间
但是Python内置的array模块既不支持多维数组功能,又没有配套对应的计算函数,所以基于Numpy的ndarray在很大程度上改善了Python内置array模块的不足,将重点介绍ndarray的创建与索引。
1. 创建ndarray对象
1)ndarray数据类型
在《Python 3智能数据分析快速入门》该节内容中,作者罗列了15种数据类型,其中实数数据类型13种。这些实数数据类型之间可以互相转换。
这时有人会问,为什么要支持这么多种数据类型?是因为对比Python语法来说仅支持整数、浮点数和复数3种类型,但是当科学计算涉及数据较多,对存储和性能都有较高要求,所以对数据类型进行精细定义,有助于NumPy合理使用存储空间并优化性能和程序员对程序规模有合理评估。
对于15种数据类型在这里笔者将不赘述,书上有详细的解释以及案例示范。
2)ndarray创建
在《Python 3智能数据分析快速入门》该节内容中,作者介绍了两种创建ndarray的方法:
使用array函数创建数ndarray
使用arange函数创建数ndarray
这里笔者再补充四种方法并整理出来:
从Python中的列表、元组等类型创建ndarray数组
使用NumPy中函数创建ndarray数组,如:arange, ones, zeros等
从字节流(raw bytes)中创建ndarray数组
从文件中读取特定格式,创建ndarray数组
对于方法②再补充5个常用函数:
np.full(shape,val):根据shape生成一个数组,每个元素值都是val
np.ones_like(a):根据数组a的形状生成一个全1数组
np.zeros_like(a):根据数组a的形状生成一个全0数组
np.full_like(a,val):根据数组a的形状生成一个数组,每个元素值都是val
np.concatenate():将两个或多个数组合并成一个新的数组
3)随机数
Numpy提供了强大的生成随机数的功能,使用随机数也能创建ndarray。基本语法格式:numpy.random.×××() 。在《Python 3智能数据分析快速入门》该节内容中,作者罗列了13个函数及其说明,笔者再补充2个函数:
choice(a[,size,replace,p]):从一维数组a中以概率p抽取元素,形成size形状新数组 replace表示是否可以重用元素,默认为False
poisson(lam,size):产生具有泊松分布的数组,lam随机事件发生率,size形状
2. ndarray的索引和切片
索引与切片是ndarray使用频率最高的操作。相较于list,ndarray索引与切片在功能上更加丰富,在形式上更多样。ndarray的高效率在很大程度上需归功于其索引的易用性。
1)一维ndarray的索引
一维ndarray的索引方法很简单,与list的索引方法一致,相关案例在书上有展示,这里不再赘述。
2)多维ndarray的索引
多维的每一个维度都有一个索引,各个维度的索引之间用逗号隔开,例如:arr[ [维度1(行)] , [维度2(列)] ]。
代码清单如下:
import numpy as np
print(np.arange(10))
输出:[0 1 2 3 4 5 6 7 8 9]
arrnp.array([[1,2,3,4,5],[4,5,6,7,8],[7,8,9,10,11]])
print('\n',arr)输出:
[[ 1 2 3 4 5]
[ 4 5 6 7 8]
[ 7 8 9 10 11]]
#访问第0行中第3列和第4列元素
print('切片结果:',arr[0,3:5])
输出:
切片结果:[4 5]
#访问第1行和第二行中第2列、第3列和第4列的元素
print('切片结果:\n',arr[1:,2:])
输出:
切片结果:
[6 7 8]
[9 10 11]
#访问第2列的元素
print('切片结果:',arr[:2])
输出:
切片结果:[3 6 9]
ndarray在索引与切片的时候除了使用整形的数据外,还可以使用布尔型,代码清单如下:
# 索引第1、3行中第2列的元素。Define true 1, define false 0
mask=np.array([1, 0, 1], dtype=np.bool)
print(arr[mask, 1])
输出:
[2 8]
3)花式索引
花式索引是一个Numpy术语,是在基础索引方式之上衍生出的功能更强大的索引方式。它能够利用整数ndarray进行索引。
在这节的学习中,发现一个有趣的问题:在使用np.empty函数时,本想用arr = np.empty((4,7))创建一个空的多维数组,但是返回的结果是这样:
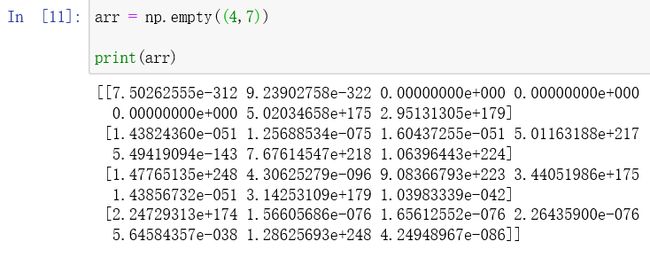
语法格式数值等都没有什么错误的情况下,初步怀疑是函数本身的原因,于是用help()函数查看它的详细介绍,竟然查到了:

数据类型是可选且默认值是numpy.float64。(好家伙,书上可没告诉我)所以只需在后面选择int就行。
arr = np.empty((4,7),int)
print(arr)
输出:
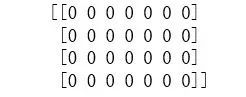
另一个问题是关于ix函数生成区域索引器的问题,代码如下:
arr = np.array([np.arange(i*4, i*4+4) for i in np.arange(6)])
print('创建的二维ndarray arr为:\n', arr)输出:

#利用np.ix函数将两个一维的整数ndarray转化为方形区域的索引器
print('使用ix成片索引arr结果为:\n', arr[np.ix_([5, 1, 4, 2], [3, 0, 1, 2])])输出:

out[15]为什么会返回这样一个结果?是因为ix函数结果的排序是基于[5,1,4,2],[3,0,1,2]两个数组产生的笛卡尔积,即(5,3),(5,0),(5,1),(5,2);(1,3),(1,0),(1,1),(1,2);(4,3),(4,0),(4,1),(4,2);(2,3),(2,0),(2,1),(2,2)。然后按照索引(5,3),(5,0),(5,1),(5,2)得到第0行元素:23 20 21 22,之后的以此类推。
02 ndarray的基础操作
ndarray的基础操作包括设置ndarray形状、展平ndarray、组合ndarray、分割ndarray、ndarray的排序与搜索,以及ndarray的字符串操作等。
设置ndarray形状
书中已经介绍了12种基本函数和它们的代码演示:
通过reshape方法改变ndarray形状
通过resize方法改变ndarray形状
通过修改shape属性改变ndarray维度
使用ravel方法展平ndarray
使用flatten方法展平ndarray
使用hstack函数实现ndarray横向组合
使用vstack函数实现ndarray纵向组合
使用concatenate函数组合ndarray
使用dstack函数组合ndarray
使用hsplit函数实现ndarray横向分割
使用vsplit函数实现ndarray纵向分割
使用split函数分割ndarray
使用dsplit函数实现ndarray深度分割
在这里做几点补充和说明:
.swapaxes(ax1,ax2):将数组n个维度中两个维度进行调换
.astype(new_type):一定会创建新的数组(原始数据的一个拷贝),即使两个类型一致
.tolist( ):将数组或者矩阵转换成列表
但请注意深度分割函数dsplit的使用条件:
import numpy as np
arr=np.arange(12)
arr.shape = (4, 3)
print('\n', arr)
输出:
[[ 0 1 2]
[ 3 4 5]
[ 6 7 8]
[ 9 10 11]]
print('形状改变后, ndarray arr的维度为:',arr.ndim)
输出:
形状改变后,ndarray arr的维度为:2
'''
dsplit分割的ndarray必须是三维ndarray,
且分割的数目必须为shape属性中下标为2的值的公约数。
比如这里的分割数就是36,下标为2的值是4,符合要求
'''
arr = np.arange(36).reshape(3,3,4)
print('创建的三维ndarrary arr为:\n',arr)
创建的三维 ndarrary arr为:
[[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
[[ 12 13 14 15]
[ 16 17 18 19]
[ 20 21 22 23]]
[[ 24 25 26 27]
[ 28 29 30 31]
[ 32 33 34 35]]]
1. 排序与搜索
书中已经介绍了6种基本函数和它们的代码演示:
使用sort函数进行排序
使用argsort函数进行排序
使用argmax和argmin函数进行搜索
使用where函数无x与y
使用where函数有x与y
使用extract函数进行搜索
在这里做几点补充和说明:
其中注意argsort函数使用的方法类似于sort,只是返回的值不同,返回的是ndarray arr的下标。
2. 字符串操作
Numpy的char模块提供的字符串操作函数可以运用向量化运算来处理整个ndarray,而完成同样的任务,Python的列表则通常借助循环语句遍历列表,并对逐个元素进行相应的处理。
Numpy的char模块提供的常用字符串操作函数具有字符串的连接、切片、删除、替换、字母大小写转换和编码调用等功能,可谓是十分方便,书上有非常详细的介绍,建议大家结合《Python 3智能数据分析快速入门》这本书美味食用。
03 ufunc
ufunc,全称通用函数(universal function),是一种能够对ndarray中所有元素进行操作的函数,而不是对ndarray对象操作。
ufunc的广播机制
广播(Broadingcasting)是指不同形状的ndarray之间执行算术运算的方式。若两个ndarray的shape不一致,Numpy则会实行广播机制。为了更好地使用广播机制,需要遵循4个原则。原则及案例在书上第159页有详细演示,此处不再赘述。
常用ufunc
常用的ufunc运算有算数运算、三角函数、集合运算、比较运算、逻辑运算和统计计算等。书上提供了若干种常用函数,对ndarray中所有元素的运算来说,在提供了极其方便与快捷的同时,又囊括一切强大的功能。相关函数及案例在书上第161页有详细演示,此处不再赘述。
04 matrix与线性代数
Numpy的matrix是继承自Numpy的二维ndarray对象,不仅拥有二维ndarray的属性、方法与函数,还拥有诸多特有的属性与方法。同时,Numpy中的matrix与线性代数中的矩阵概念几乎完全相同,同样含有转置矩阵、共轭矩阵、逆矩阵等概念。
只要是大学期间学过《线性代数》这门课程的同学,对于《Python 3智能数据分析快速入门》的学习完全没有问题,相关专业术语及技术实现细节在本节中都有强调。详情请从第169页开始学习。
05 Numpy文件读写
读写文件是利用Numpy进行数据处理的基础,Numpy中主要有二进制的文件读写和文件列表形式的数据读写两种形式。其中二进制文件读取使用书上第175页中提到的load函数;二进制文件存储使用save和savez函数。
但是在实际的数据分析任务中,更多使用文本格式的数据,如txt或csv,因此经常使用loadtxt函数执行对文本格式的数据的读取任务和savetxt函数执行对文本格式的数据的存储任务。
但是它们只能有效存取一维和二维数据,这里我再对多维数据的存取的方法进行补充:
a.tofile(frame, sep='', format='%s')
frame:文件、字符串
sep:数据分割字符串,如果是空串,写入文件为二进制
format:写入数据的格式
np.fromfile(frame, dtype=float, count=‐1, sep='')
frame:文件、字符串
dtype:读取的数据类型
count:读入元素个数,‐1表示读入整个文件
sep:数据分割字符串,如果是空串,写入文件为二进制
需要注意的是,该方法需要读取时知道存入文件时数组的维度和元素类型,a.tofile()和np.fromfile()需要配合使用,可以通过元数据文件来存储额外信息。
06 小结
本章重点介绍了Numpy数值计算重要的基础内容,主要包含如下6部分内容。
ndarray基础知识,包括ndarray的属性与创建方法。
ndarray使用的切片和索引方法,改变ndarray形状的方式,ndarray的排序、搜索与字符串操作等。
ufunc的广播功能及常用的ufunc,包括算术运算函数、三角函数、集合运算函数、比较运算函数、逻辑运算函数和统计计算函数等。
矩阵的创建、属性及基本运算。
Numpy中二进制的文件读写和文件列表形式的数据读写。
参考文献:
1. 《Python 3智能数据分析快速入门》 李明江、张良均、周东平、张尚佳 著,机械工业出版社出版。
2.中国大学MOOC,《Python数据分析与展示》作者:嵩天 。
3.百度百科:数组维数
4.CSDN:《花式索引与np.ix_函数》TzeSing 著
5.CSDN:《关于np.empty()函数的用法》爱数据的橙子 著
关于作者:王皓,一名就读于北京石油化工学院大数据管理与应用专业的同学,热爱并致力于学习Python语言及相关应用领域。大数据DT内容合伙人。
延伸阅读《Python3智能数据分析快速入门》
点击上图了解及购买
转载请联系微信:DoctorData
推荐语:本书假设你有一定的数据分析基础,但是没有Python和AI基础,为了帮助你快速掌握智能数据分析需要的技术和方法,书中有针对性地讲解了Python和AI中必须要掌握的知识点,内容由浅入深,循序渐进。从环境配置、基本语法、基础函数到第三方库的安装与使用,对各个操作步骤、函数、工具、代码示例等的讲解非常详尽,确保所有满足条件的读者都能快速入门。

大数据DT「内容合伙人」上线啦!
最近,你都在读什么书?有哪些心得体会想要跟大家分享?
数据叔最近搞了个大事——联合优质图书出版商机械工业出版社华章公司发起鉴书活动。
简单说就是:你可以免费读新书,你可以免费读新书的同时,顺手码一篇读书笔记就行。详情请在大数据DT公众号后台对话框回复合伙人查看。
划重点????
干货直达????
世界一流大学的计算机专业,在用哪些书当教材?
从CPU到GPU,Nvidia就这样成为AI时代的大赢家
初学者指南:什么是算法?11行伪代码给你讲明白
6个案例手把手教你用Python和OpenCV进行图像处理
更多精彩????
在公众号对话框输入以下关键词
查看更多优质内容!
PPT | 读书 | 书单 | 硬核 | 干货 | 讲明白 | 神操作
大数据 | 云计算 | 数据库 | Python | 可视化
AI | 人工智能 | 机器学习 | 深度学习 | NLP
5G | 中台 | 用户画像 | 1024 | 数学 | 算法 | 数字孪生
据统计,99%的大咖都完成了这个神操作
????