深度高斯过程综述
0摘要
高斯过程是贝叶斯学习的主要方法之一。 尽管该方法已经成功地应用于许多问题,但它有一些基本的局限性。 文献中的多种方法已经解决了这些限制。 但是,到目前为止,还没有对这些主题进行全面的调查。 大多数现有调查只关注高斯过程的一种特定变体及其衍生物。 本调查详细介绍了使用高斯过程的核心动机、其数学公式、局限性和多年来为解决上述局限性而出现的研究主题。 此外,一个特定的研究领域是深度高斯过程 (DGP),它在过去十年中得到了显着改进。 他们的调查概述了推动这一研究领域前沿的重要出版物。 最后,对未解决的问题和未来工作的研究方向进行了简要讨论。
1介绍
近年来,机器学习领域取得了许多进展。大多数这些进步可以归因于反向传播、大型数据集和计算资源的改进。然而,目前大多数流行的机器学习方法,主要是深度学习方法,都是基于频率论方法,这需要通过研究数据集中特征和预测之间的相关性来做出任何预测决策。这种方法的问题在于,它很容易对数据集过拟合,并有学习数据集中不理想偏差的风险。
此外,当前的方法使得将任何先验领域知识引入预测模型变得困难且不直观。一些现实世界的问题有领域专家;结合他们的知识可以产生更好的模型。然而,大多数深度学习方法不适应这种结合,需要开发特定于应用程序的方法来解决这样的问题。
预测不确定性是一个重要的指标,需要通过可靠的模型进行估计。 大多数数据源都包含不可忽略的噪声,这些噪声可能会阻碍预测模型的性能。 测试数据样本与训练数据集分布不太相似的情况也很常见。 在这种情况下,必须了解模型的预测不确定性。 如果该模型用于关键任务任务而不考虑其预测不确定性,则可能导致灾难性结果。
传统深度学习方法的另一个主要缺点是模型比较。深度学习方法是参数化的,需要模型架构的明确定义。此外,模型架构是特定于应用程序的。通常需要将多个模型架构相互比较,以确定哪个是任务的最佳模型。但是,在参数计数和比较准确性方面考虑模型大小是非常重要的。
贝叶斯方法以不同程度的易用性和效率解决了上述限制。我们可以将领域知识与先验分布相结合,预测不确定性可以用预测方差来估计,模型可以用贝叶斯因子适当地相互比较。
除了上述优点之外,贝叶斯方法的另一个有趣特征是它们有助于对任何系统或过程进行因果建模。事实上,大多数分类或回归问题都需要一系列子决策,每个子决策都会导致最终预测。然而,传统的深度学习方法并不是特别适合指定这种因果模型。贝叶斯框架以及 do-calculus [Pearl, 2000, Pearl and Mackenzie, 2018] 可用于在模型中指定此类结构。
贝叶斯方法的优点提出了为什么它们还没有广泛适应的问题。贝叶斯方法通常会产生大量的计算费用或完全难以解决的问题,这使得它们无法解决几个问题。尽管如此,这些方法具有悠久的历史,并已被用于解决许多具有实质性分支的问题 [McGrayne, 2011]。贝叶斯框架一次又一次地证明自己值得进一步研究。
本文考虑了一种特殊类型的贝叶斯方法,即高斯过程 [Rasmussen and Williams, 2006]。该方法源于随机过程,一个致力于用概率理论建模随机过程的研究领域 [Klebaner, 2012, Rosenthal, 2006]。大多数感兴趣的问题通常不是确定性过程,或者即使是,也可能无法访问对其建模所需的所有信息。随机过程在数学上适应了这种不确定性,而高斯过程是随机过程的一种特殊变体。我从详细介绍高斯过程、它们的优点和缺点开始我的阐述。然而,本次调查的主要焦点是深度高斯过程 (DGP)。我将描述一些对构建 DGP 至关重要的高斯过程的突出变体,并解释关键的 DGP 方法。
3 高斯过程
我详细介绍了贝叶斯方法的关键优势以及为什么研究人员特别对高斯过程感兴趣。 本节进一步阐述了 GP。 我给出了全科医生的直觉; 他们的数学公式 [Rasmussen and Williams, 2006, Murphy, 2012],以及对其公式中术语的直观解释。 此外,我将解释内核函数并列出 GP 的一些限制。

3.2 限制
尽管 GP 有几个优点,但它们也有一些关键限制,阻碍了它们在大多数机器学习问题中的使用。 具体来说,主要存在三个问题:
- 计算成本
- 存储成本
- 分层特征提取
GP 的计算成本可能相当可观, 需要对核矩阵求逆以获得 GP 的预测分布。 内核矩阵的大小为 n × n n ×n n×n 其中 n n n 是训练数据集中的数据点数。 对这样的矩阵求逆需要 O ( n 3 ) O(n^3) O(n3) 的计算时间。 此外,一旦内核矩阵逆可用,就需要 O ( n ) O(n) O(n) 和 O ( n 2 ) O(n^2) O(n2)时间来确定新数据点的预测分布的均值和方差。
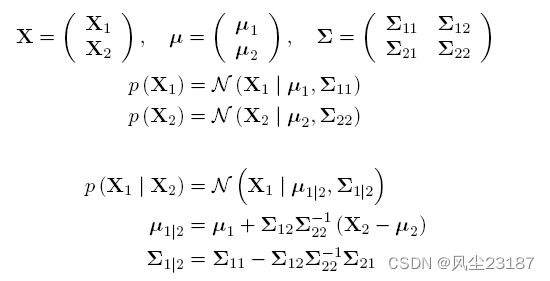
此外,由于 GP 需要整个训练数据集的存储,因此存储成本为 O ( n 2 ) O(n^2) O(n2)。根据数据集的大小,存储成本大大限制了该方法的可扩展性。此外,如果在训练数据集大小不断增加的环境中使用 GP,则计算和存储成本可能会压倒整个过程,从而使 GP 的好处变得过于昂贵。因此,GPs 通常只适用于大约 1000 - 3000 个数据点的数据集。
GP 的另一个主要缺点是缺乏能够处理结构化数据的内核函数,其中需要考虑分层特征提取来正确确定一对数据点的相似性。这样的问题经常出现在图像等数据中,但在更简单的矢量数据集中也很普遍。传统的核函数无法处理这种相关性,因此需要像深度学习模型中使用的那样进行深度特征提取。然而,这种特征提取仍然需要限制在贝叶斯框架中,以保留 GP 的优势。
稀疏高斯过程解决了计算和存储成本。深度高斯过程解决了特征提取问题。
我将在以下部分解释过去二十年来开发的稀疏和深度 GP 的一些突出方法。图:2 显示了将限制与解决这些限制的 GP 变体相关联的流程图。

4 稀疏高斯过程
鉴于阻碍 GP 广泛使用的计算和存储要求,大量论文试图解决该问题,并统称为稀疏高斯过程 (SGP),图 3 描述了本节中介绍的主要方法。

该术语源于大多数这些方法解决该问题的方式。因为主要问题是协方差矩阵的求逆,所以大多数方法都试图引入稀疏性并减小需要求逆的矩阵大小,同时保留原始矩阵的性能。
本节重点介绍一些众所周知的方法,这些方法对于开发某些深度高斯过程方法至关重要,这些方法将在下一节中详细介绍。所有 SGP 的完整概述超出了本次调查的范围;读者可参考 [Liu et al., 2020] 进行全面总结。 [Williams and Seeger, 2001] 的 Nystr om 近似是一种众所周知的降低 GP 中协方差矩阵求逆成本的方法。
Nystr om 近似允许生成任何核矩阵的低秩近似。该方法通过从训练集中选择 m < < n m << n m<<n 的 m m m 个数据点应用于 GP。然后计算内核矩阵的低秩近似 K ^ \hat K K^,如下所示
K ^ = K n , m K m , m − 1 K m , n (1) \hat K=K_{n,m}K_{m,m}^{-1}K_{m,n}\tag1 K^=Kn,mKm,m−1Km,n(1)
这里, K n , m K_{n,m} Kn,m表示分别从训练数据集和所选子集中的 n n n 和 m m m 个数据点计算的核矩阵。相同的符号用于其他内核矩阵。该近似只需要对一个 m × m m×m m×m 矩阵求逆,从而将计算成本从 O ( n 3 ) O(n^3) O(n3) 降低到 O ( m 3 ) O(m^3) O(m3)。
然而,该近似假设数据来自低秩流形,如果数据维度 d < n 就是这种情况。在这种情况下,低秩近似将是精确的并且不会导致信息丢失。但是,选择的 m 个数据点也会影响近似值。即使数据来自低维流形,也可能存在导致近似差的数据点。
在实践中,大多数数据集的数据点多于特征数量;因此,该方法适用于大多数情况。然而,选择数据点对于近似的性能至关重要。 Williams 和 Seeger 在他们的方法中使用了 m m m 个数据点的随机子集 [Williams and Seeger, 2001]。尽管该方法有效,但简单的数据选择过程限制了该方法的性能。
Snelson 和 Ghahramani [Snelson 和 Ghahramani, 2006] 通过将子集视为模型参数并将其称为伪数据,解决了 Nystr om 近似的子集选择问题。假设伪数据是合成的,不一定对应于训练数据集中可用的任何数据点。实际上,它们可以采用训练数据集的某种组合的值。
使用最大似然计算伪点。 然而,要使用最大似然,需要用伪点适当地参数化 GP。 Snelson 和 Ghahramani [Snelson 和 Ghahramani, 2006] 引入了伪点分布,并考虑了来自训练、测试和由 f , f ∗ , m f,f_*,m f,f∗,m 给出的伪数据点的数据的潜在表示的联合分布;。 然后作者将伪点边缘化以获得后验分布,如下所示

尽管在实践中使用最大似然来确定伪点的分布是可行的,但使用最大似然会存在过度拟合的风险。 使用贝叶斯方法来计算以训练集为条件的伪点分布是理想的。 不幸的是,这种方法是不可行的,因为它变得难以处理伪点的解析解。 此外,该方法的工作原理是假设联合分布 p ( f ∗ , f ) p (f_*, f ) p(f∗,f) 可以按如下方式划分
该假设将 GP 从训练集中获得的信息限制为仅通过伪诱导集。因此,伪点也称为诱导输入。分解假设限制了模型的容量并影响模型的准确性。值得注意的是,为伪集假设的先验分布会显着影响结果。
Snelson 和 Ghahramani [Snelson 和 Ghahramani, 2006] 将伪点视为超参数并在它们之上引入先验,导致与普通 GP 相比不准确的后验。不准确是核近似公式的结果。 Titsias [Titsias, 2009] 通过考虑变分方法解决了拟合和不精确的后验问题。该方法引入了一个可以优化以确定诱导输入和内核超参数的下限。下面显示的边界可用于求解诱导点和核超参数。然后我们可以使用诱导点来计算预测分布。
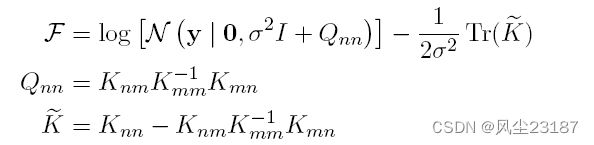
然而,[Titsias, 2009] 中的边缘没有应用随机梯度下降所需的分解。 亨斯曼等人 [Hensman et al., 2013] 通过开发可以通过随机梯度下降优化的新边界,改进了 Titsias [Titsias, 2009] 的工作。 与 Titsias 的方法不同,[Hensman et al., 2013] 中的方法不需要一次性计算整个数据集来计算变分参数。 它使用了以下可以通过随机梯度下降优化的界限。

这里, u u u 是诱导点的特征空间表示集, k i k_i ki 是 K m n K_{mn} Kmn 的第 i i i 列。 亨斯曼等人。 展示了在保持 O ( m 3 ) O(m^3) O(m3) 降低的模型复杂度的同时很好地扩展到大型数据集的方法。
5. 高斯过程潜在变量模型
到目前为止讨论的方法主要解决了计算和存储成本问题。本节介绍一种可以以无监督方式训练的 GP 变体。高斯过程潜在变量模型 (GPLVM) [Lawrence, 2004, Lawrence, 2005] 假设特征空间是具有未知数据分布的潜在空间。然后在训练阶段学习潜在空间分布。尽管该方法似乎无关紧要,但它在我将在下一节中介绍的一些深度高斯过程中发挥着重要作用。
Lawrence [Lawrence, 2004, Lawrence, 2005] 表明,如果 GP 的函数空间被约束为线性函数空间,则 GP 可以解释为主成分分析 (PCA) 的概率变体。此外,如果将函数空间放松为由核函数定义的非线性空间,则可以将其解释为概率非线性 PCA。该方法假设输入空间上的标准高斯先验,并最大化数据集 相对于输入数据似然 X 的对数概率 p ( y ∣ X , β ) p(y | X,β ) p(y∣X,β) 。
输入数据或潜在空间分布无法解析计算核函数引入的非线性。然而,Lawrence [Lawrence, 2004, Lawrence, 2005] 表明可以使用期望最大化算法来估计分布。但是,该方法只返回数据分布的模式。
此外,GPLVM 被证明可利用部分观察到的特征重建输入。这种情况经常发生在图像重建或去噪任务中。
尽管 GPLVMs 对于无监督任务非常有用,但原始方法假定访问完整的内核矩阵,这需要存储整个训练数据集并求逆 n × n n ×n n×n 内核矩阵。 Lawrence [Lawrence, 2007] 通过展示大多数稀疏高斯过程方法可以转化为 GPLVMs 来解决这个问题。然而,该方法仍然给出了潜在空间的 MAP 估计,并冒着过拟合训练数据集的风险。
Titsias and Lawrence [Titsias and Lawrence, 2010] 通过提出贝叶斯方法解决了过拟合问题。 他们没有为潜在空间寻找 MAP (最大后验概率)解决方案,而是提出了一种变分方法。 然而,使用变分方法来寻找数据分布会带来难以处理的问题。 Titsias 和 Lawrence 通过将 Titsias 的变分方法结合到 SGP 中解决了这个问题 [Titsias, 2009]。 伪点的引入 [Titsias, 2009] 消除了 GPLVM 变分界中难以处理的项,并产生了如下所示的可行优化界
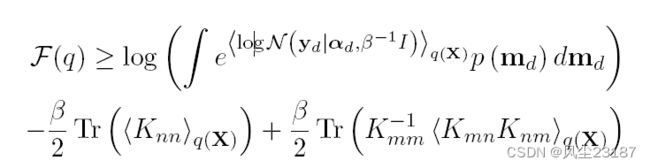
这里, q q q 是伪点 m m m 上的变分分布,并且 α = K n m K m m − 1 m α = K_{nm}K^{-1}_{mm}m α=KnmKmm−1m。 下标 d d d 用于表示特征的每个维度。
GPLVM 已应用于众多应用程序及其变体,我们未在此处介绍。 读者可参考 [Li and Chen, 2016] 对 GPLVM 进行深入调查。
6.深度高斯过程
尽管 SGP 解决了计算成本问题,但 GP 仍然不适用于许多应用程序。原因就是核函数。最常用的核函数具有相对简单的相似性度量。然而,在特定的数据集中,可能必须在输入空间的不同区域中使用不同的相似度度量。可以提取此类特征的相似性度量必须利用分层结构进行特征提取。
解决该问题的一种策略是堆叠 GP,类似于在 MLP 中堆叠感知器的方式。但是,堆叠 GP 使得一层的输出成为下一层的输入,这使得它们高度非线性并且难以得到解析解。此外,堆叠的 GP 甚至不再对应于 GP,因为后验分布可以采用任意分布。然而,这种方法通常被称为深度高斯过程(DGP)。有几位作者试图对这样的模型进行建模。本节解释了这些方法的发展。
最早的 DGP 方法之一是 Lawrence 和 Moore [Lawrence and Moore, 2007]。他们考虑了 GPLVM 模型,但假设 GP 用于输入空间的先验分布,使其成为两层 DGP。 DGP 产生了以下似然函数,不能通过分析将其边缘化。
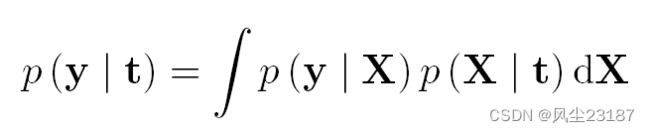
这里, t t t 是输入层的输入 G P GP GP, X X X 是传递给第二层 GP 的中间表示。 Lawrence 和 Moore 考虑了上述问题的 MAP 解决方案。 这是通过最大化以下内容来实现的。
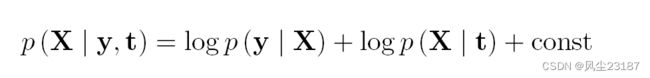
作者还表明,可以用这种方法对更深层次的层次结构进行建模。 但是,该模型仅限于 MAP 解决方案,该解决方案极易受到过拟合的影响。 达米亚努等人 [Damianou et al., 2011, Damianou, 2015] 提出了一种变分方法来解决过拟合问题。 他们还考虑了一个 2 层堆叠的 GP,但这种模型的变分界引入了类似于 GPLVM 的难处理性。 然而,作者表明,[Titsias and Lawrence, 2010] 中用于贝叶斯 GPLMV 的变分方法也可用于制定 2 层 GP 的变分界限。 最终边界如下所示, q ( X ) q(X) q(X) 为变分分布
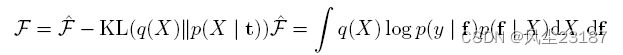
此外,Damianou 和 Lawrence [Damianou and Lawrence, 2013] 通过将变分界推广到具有任意层数的 DGP 来改进上述边界。 下面显示的边界可用于具有两层或多层的 DGP。
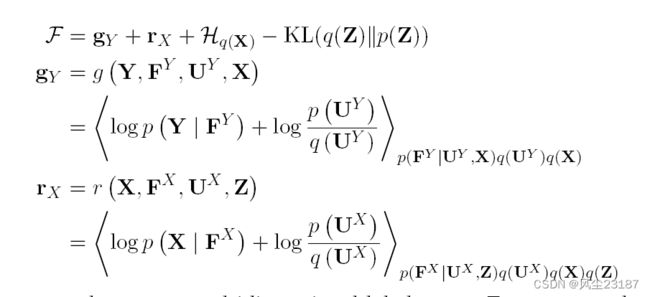
这里, Y Y Y 表示输出多维标签空间, Z Z Z 表示输入层中的潜在变量, X X X 表示中间层中的潜在输入。 U U U 和 F F F 分别是对应于诱导点和潜在输入的潜在函数的值; 它们的上标表示它们所属的层。 此外, H H H 表示其下标所示分布的熵,KL 是标准的 KL 散度。 图 4 显示了 [Damianou and Lawrence, 2013] 的 DGP 模型架构。

同样,该方法的关键依赖于引入诱导点的变分技巧,如 [Titsias and Lawrence, 2010] 中所述。 Damianou 和 Lawrence 在 MNIST 数据集上进行了实验,他们展示了 5 层 DGP 可用于图像分类任务。
[Damianou and Lawrence, 2013] 中的方法的一个限制是,需要学习的变分参数的数量随着训练集中数据点的数量线性增加。并且它涉及求逆矩阵,这是一种计算成本很高的操作,从而限制了它的可扩展性。戴等人。 [Dai et al., 2015] 通过引入反向约束来解决这个问题。约束允许他们通过 MLP 将潜在变量的均值项定义为潜在变量本身的确定性函数。该方法减少了变分参数的数量。此外,戴等人 [Dai et al., 2015] 还表明,他们的方法可以以分布式方式进行训练,从而允许将模型扩展到大型数据集。
Salimbeni 和 Deisenroth [Salimbeni 和 Deisenroth,2017 年] 最近提出了一种解决先前 DGP 方法的层独立性问题的方法。 [Damianou and Lawrence, 2013] 中的 DGP 假设 GP 跨层独立,并且只考虑层内的相关性。然而,Salimbeni 和 Deisenroth 认为,这种方法等同于单个 GP,每个 GP 的输入都来自 GP 本身。作者还表示,他们发现在 [Damianou and Lawrence, 2013] 中使用 DGP 时,某些层会被关闭。
Salimbeni 和 Deisenroth [Salimbeni and Deisenroth, 2017] 提出了一个新的变分界,它保留了类似于 [Damianou and Lawrence, 2013] 的精确模型后验,同时保持了相邻层内和相邻层之间的相关性。然而,Salimbeni 和 Deisenroth 表明这种方法对于分析计算是不可行的,但仍然可以使用 MCMC 采样技术优化边界。这种方法在计算上是昂贵的。但是,它可以通过利用跨输出维度的 DGP 分解来并行化。此外,该方法在推理过程中也需要采样方法,但其性能明显优于以前的工作。

在上面显示的 [Salimbeni and Deisenroth, 2017] 的优化界限中,下标用于表示数据集中的每个数据样本,上标用于表示 DGP 中的层。其余术语遵循与 Damianou 等人使用的相同约定[达米安努和劳伦斯,2013 年]。
我简要提到了 DGP 不一定对应于高斯过程。尽管如此,到目前为止讨论的方法确实将后验分布建模为高斯分布,每个都有其假设。哈瓦西等人[Havasi et al., 2018] 提出了一种与传统 GP 更加不同的技术。作者表明,由于高斯是单模态的,使用它来模拟后验将导致较差的结果。相反,他们建议使用可以更好地捕捉真实后验分布的多模态分布。
然而,不可能为多模态后验制定解析解。我们可以使用变分推理来学习多模态后验。尽管如此,我们仍然需要确定变分分布的确切形式,这很困难,因为我们通常事先不知道后验分布。哈瓦西等人。 [Havasi et al., 2018] 通过使用随机梯度哈密顿蒙特卡洛 (SGMCMC) [Chen et al., 2014] 方法来估计后验来规避这个问题。该方法可以通过从真实后验中采样而不是使用变分分布来确定诱导点。
尽管该方法远远超过了先前 DGP 的性能并且是当前最先进的,但它仍然有其局限性。值得注意的是,SGMCMC 方法很难调整,因为除了已经为 DGP 估计的参数之外,它还引入了自己的参数。几种 MCMC 方法变体试图改进 SGMCMC,但这些方法都没有应用于 DGP。
到目前为止,我们讨论的 DGP 试图开发可以对数据中的层次特征进行建模的 GP 变体,这是通过假设一个前馈网络来完成的,其中网络的每个节点都被建模为一个 GP。它是解决该问题的最流行的方法,并且已经产生了可以得到相当有希望的结果的方法。然而,还有其他方法不考虑这种显式前馈网络。
威尔逊等人[Wilson et al., 2016] 提出了一种使用深度神经网络作为核函数的方法,称为深度核。与高斯核不同,深核产生一个向量输出,并为每个向量元素分配一个 GP。威尔逊等人进一步将 GP 与加法结构相结合,以促进其训练与分析界。威尔逊等人。 [Wilson et al., 2016] 表明他们的方法擅长多项任务。然而,深度神经网络架构需要针对特定任务,并且鉴于其大量参数,其参数容易过度拟合。
Lee 等人提出了另一个关于 DGP 的有趣观点[李等人,2018]。到目前为止,所有讨论过的具有线性潜在函数的 GP 都以不同的方式组合在一起,以实现聚合的非线性潜在函数空间。李等人开发了一种考虑由非线性函数组成的整个函数空间的方法。与以前的方法不同,由于使用了特定的核函数,函数空间并不局限于特定的子空间。该方法可以被视为 Neil [Neal, 1996] 的推广,他展示了无限宽的单层神经网络与 GP 的等价性。李等人。显示了 GP 与无限宽的深度神经网络的等价性。
李等人 [Lee et al., 2018] 表明该方法与一些经过梯度下降训练的神经网络相当,同时保留了其不确定性估计。此外,不确定性估计与模型精度成正比。但是,该方法具有多项式递增核矩阵,因此对于某些问题不可行。此外,该方法只考虑了具有完全连接层和 Relu 激活函数的深度神经网络。加内洛等人。 [Garnelo et al., 2018] 提出了一种具有类似精神的方法并引入了神经过程 (NPs)。然而,不是考虑深度和宽度渐进增加的神经网络,而是使用深度神经网络代替由核函数参数化的高斯分布来定义 p ( f ∣ X ) p(f | X) p(f∣X)。
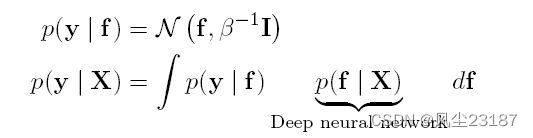
使用摊销变分推理训练深度神经网络。这种方法的结果是,由深度神经网络定义的函数空间允许我们提取层次特征并保留概率解释。然而,该模型需要使用元学习进行训练,这是一种使用多个不同数据集或任务来训练同一模型的方法。使用元学习是因为函数空间中的每个函数都对应于输入序列或任务。考虑多个任务允许 DNN 近似函数空间的可变性。在训练时,上下文向量 r c r_c rc 被传递给 DNN 以指示当前正在考虑的任务,如图 5 所示。
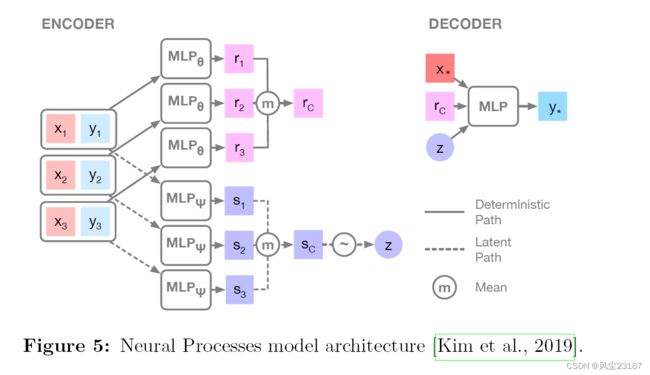
此外,为了保留概率解释,引入了一个潜在变量 z z z,它捕获了上下文数据中的不确定性。这意味着,与不确定性来自核函数及其函数空间的普通 GPs 不同, N P s NPs NPs 使用数据执行此操作。因此,所提供的上下文可能会显着影响模型的性能,并且可以被认为类似于 SGP 中的诱导点。
此外,该模型不假设高斯先验或后验,允许拟合到任何数据分布。加内洛等人表明他们的方法产生了良好的预测分布,同时与普通高斯过程相比参数有效且快速。尽管如此,该方法假设了一个预先定义的 DNN 模型架构,该架构需要特定于任务。此外,该模型只是使用 DNN 对某些随机过程的近似。但是,无法保证 DNN 的逼近质量。此外,元学习要求对训练计算提出了很大的要求,并且所考虑的数据集必须与感兴趣的主要数据集相似。
最后,Yang et al.[Yang et al., 2020] 最近提出了一种基于能量的过程 (EBP)。 EBP 是神经过程的泛化,因为它们利用基于能量的模型 [LeCun et al., 2006] 来逼近 p ( f j ∣ X ) p(f j|X) p(fj∣X),而不是如下所示的经过 M A P MAP MAP 训练的 DNN,其中 f w f_w fw 是能量模型,Z 是分区函数:
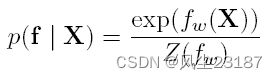
然而,通过利用基于能量的模型,作者能够证明普通 GP 和 NP 可以作为特殊情况从 EBP 中恢复。基于能量的公式还允许人们用任意分布来近似条件 p ( f ∣ X ) p(f |X) p(f∣X),这与 GP 和 NP 不同,它们分别限于高斯分布和 DNN 定义的分布。
与经过训练以在给定输入 X X X 的情况下预测标签 y y y 的前馈网络不同,基于能量的模型预测一对 ( X , y ) (X,y) (X,y) 之间的能量。一个训练有素的基于能量的将输出良好匹配的 ( X , y ) (X,y) (X,y)对的低能量和不匹配的对的高能量。因此,这些模型中的预测任务变成了一个最小化任务,其中需要找到对于给定数据 X X X 具有低能量的标签 y y y。
训练这样一个模型以在随机过程中逼近我们的条件的结果是函数空间不受任何预先定义的子空间的约束。然而,基于能量的模型难以训练,并且需要一些技巧来稳定训练过程。此外,与使用元学习训练的模型类似,训练此类模型需要更长的时间。
7.讨论
高斯过程与它们的起源相距甚远。尽管已经解决了许多限制,但仍然存在尚未彻底探索的开放问题和研究方向。
一个这样的问题是分解输出维度的假设。在本文中提到的所有方法中都做出了假设。它规定每个输出维度相互独立。该假设允许简化某些推导的分解,并且在某些情况下,该假设是该方法易于处理所必需的。但是,该假设在某些数据集中可能不成立。解决这个因式分解假设将是一个有趣的研究方向。
另一个问题是大多数 SGP 和 DGP 方法需要仔细的模型初始化和超参数调整,否则模型不会收敛。然而,对于大多数可以保证良好模型收敛的方法,没有任何正式的规则来确定模型初始化和超参数。在使用 MCMC 方法时,调优问题尤为突出,仍有待解决。
此外,MCMC 方法已被证明在训练 DGP 方面是成功的。但是,该方法不必限于DGP。事实上,即使对于 SGP,该技术也可能会产生良好的结果。使用 MCMC 方法的主要动机是解决非高斯后验问题。尽管普通 GP 可能没有非高斯后验,但在诱导方法中所做的假设通常会改变这一点。因此,可能值得探索 MCMC 训练 SGP 的可行性。
同样,SG-MCMC 方法的几种变体尚未针对 DGP 进行基准测试。哈瓦西等人。 [Havasi et al., 2018] 只考虑了原始的 SGMCMC [Chen et al., 2014] 方法。然而,已经引入了许多改进 SGMCMC 的方法变体,其中一些变体可能会导致稳定的训练动态。
发现深内核本身非常容易受到过度拟合的影响。然而,威尔逊等人。 [Wilson et al., 2016] 只考虑了普通 DNN。但是,DNN 可以用作贝叶斯逼近器,如 Gal 和 Ghahramani [Gal 和 Ghahramani,2016 年] 所示。这种方法可能会缓解一些过拟合问题。 此外,人们还可以考虑使用 Backprob [Blundell et al., 2015] 的贝叶斯等方法来训练深度内核。找出这种方法对深层内核的影响会很有趣。加内洛等人。
[Garnelo et al., 2018] 考虑了一种类似的方法,但他们认为 DNN 近似于函数空间本身的分布。它需要一个 DNN 的明确定义,它需要是特定于任务的。此外,模型性能依赖于上下文向量来估计预测不确定性,这与适当的随机过程不一致。金等人。 [Kim et al., 2019] 引入了一种神经过程的变体,它使用注意力来改进上下文向量。也许我们可以修改注意力机制以考虑测试数据并生成包含测试数据的不确定性估计。
此外,大多数方法假设函数空间相对受限,要么使用核函数的公式,要么使用 DNN。但是,情况不一定如此;也许我们可以通过利用诸如分块超网络 [von Oswald et al., 2020] 之类的模型来考虑多个功能空间来生成模型参数和模型架构。从而大大扩展了随机过程的建模能力。
基于能量的模型似乎是另一种扩展功能空间的可行方法,但该方法难以训练并产生大量计算成本。 此外,即使是模型推理也是一项昂贵的操作,需要哈密顿马尔可夫链方法进行采样。
最后,还有可扩展性的问题。 尽管一些 DGP 方法已被证明可以很好地扩展到大型数据集,但它们尚未在高度结构化的数据集(如 Imagenet [Deng et al., 2009])上进行彻底的基准测试。 问题在于在这样的数据集上实现良好性能所需的模型深度。 与 MNIST 不同,Imagenet 需要更深的 DNN。 然而,DGP 通常只在多达 10 层的模型上进行测试。 研究和理解 DGP 如何扩展到这样的数据集是必不可少的。
8.结论
其中的高斯过程本身就很吸引人。它们的非参数形式、分析特性和对不确定性建模的能力在机器学习中是令人垂涎的。然而,它们受到限制的困扰,特别是它们显著的计算和存储成本。此外,传统的内核函数限制了 GP 可以建模的函数族。
稀疏高斯过程试图解决存储和计算成本。 SGP 的一种主要方法是使用 Nystr om 近似。该方法需要使用变分方法来模拟伪点的分布以进行完全贝叶斯处理。沿着这一研究方向提出了几种方法,每种方法都有其优点和局限性。
此外,GPLVM 是迈向 DGP 的一步。但是,分层特征表示不是预期的用例。它被提议作为概率 PCA 和无监督学习的一种方法。贝叶斯 GPLVM 通过引入纯贝叶斯训练方法对原始方法进行了改进。 BGPLVM 促进了潜在空间不确定性向后验的传播,从而建立了一种通过 GP 中的非线性传播不确定性的技术。
大多数 DGP 方法都考虑了 SGP 和 GPLVM 来解决分层特征表示的问题。 DGP 的主要趋势是以前馈方式堆叠 GP,并使用用于训练 SGP 和 GPLVM 的方法来训练它们。然而,这种方法有其局限性。开发的优化界限并不总是很严格,一些方法仅限于分析解决方案,这对这些技术施加了可扩展性限制。
此外,堆叠 GP 使模型参数化,因为它需要预先定义的模型深度和层宽。李等人。 [Lee et al., 2018] 考虑了这些问题,并试图通过将潜在函数空间建模为深度神经网络的空间来解决这些问题。但是,这种方法对于现实世界的应用程序来说尚不可行,需要做更多的工作才能实现。加内洛等人。
[Garnelo et al., 2018] 考虑使用 DNN 参数化的随机过程,而不是使用核函数的高斯分布来定义潜在函数空间。尽管如此,该方法仍需要对特定任务的神经网络进行建模,并且只是对未知随机过程的近似。基于能量的过程解决了这一限制,但该方法还不够成熟。
总之,GPs 是一种很好的数据集建模方法。该领域的总体趋势似乎正在从高斯假设转变并考虑一般随机过程。该方法从起步阶段已经走过了很长一段路,但仍有一些悬而未决的问题需要解决,才能将其提升到应有的地位。