PointNet++
[NIPS 2017]PointNet++: Deep Hierarchical Feature Learning onPoint Sets in a Metric Space
语雀(原文内容多一点,CSDN导不进来)
[论文地址][项目页面][GitHub]
在之前的文章中分析了PointNet网络是如何进行3D点云数据分类与分割的。但是PointNet存在的一个缺点是无法获得局部特征,这使得它很难对复杂场景进行分析。在PointNet++中,作者通过两个主要的方法进行了改进,使得网络能更好的提取局部特征。第一,利用空间距离(metric space distances),使用PointNet对点集局部区域进行特征迭代提取,使其能够学到局部尺度越来越大的特征。第二,由于点集分布很多时候是不均匀的,如果默认是均匀的,会使得网络性能变差,所以作者提出了一种自适应密度的特征提取方法。通过以上两种方法,能够更高效的学习特征,也更有鲁棒性。
导览
【PointNet作者亲述】90分钟带你了解3D物体检测算法和未来方向!
PPT:
斯坦福大学在读博士生祁芮中台:点云上的深度学习及其在三维场景理
PPT:
pointnet++翻译
一、背景
pointnet缺陷:没有平移不变性、没有局部特征提取能力、没有考虑点之间的关系
这些缺陷急需解决。
二、解决的问题
1.解决pointnet的缺陷,获得特征提取能力更好的网络。
2.多层次结构特征学习。
3.点的稀疏与稠密对特征提取的影响
三、方法
论文中说了很多官话,有兴趣的可以去看下,我稍微简洁点。
1.思路:在局部区域中用pointnet做递归
1.先根据空间距离的度量将点云划分到一些局部的区域中,这些区域可以是重叠的,再对每个小区域采用pointnet聚合特征,将每个区域聚合成一个带有特征向量的点,到此为止,庞大的点云转化为了:少量的点+包含区域特征的特征向量。处理和抽象一组点产生具有较少元素的新集合。
2.获得的新点云重复上面的工作,以扩大特征深度和广度。
举例,现在有一个点云 ( x , y ) (x,y) (x,y),它的一个局部区域中有个点 ( u , v ) (u,v) (u,v),用pointnet聚合区域
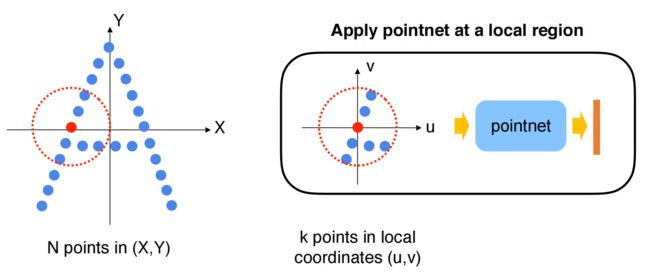
得到 ( X , Y , F ) (X,Y,F) (X,Y,F), F F F是该区域特征向量,用 ( X , Y , F ) (X,Y,F) (X,Y,F)代表区域所有点。

所以就将原始点云 ( X , Y ) (X,Y) (X,Y)转化成特征点云 ( Y , Y , F ) (Y,Y,F) (Y,Y,F),特征点云点数更少,具有更高维度的信息 F F F
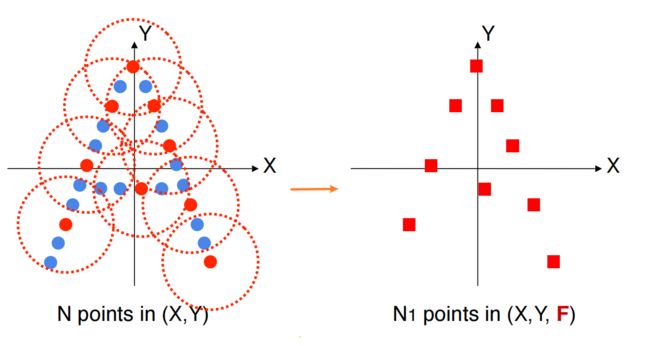
这就是作者文中提到的操作Set Abstraction:
farthest point sampling + grouping + pointnet
2.网络结构
2.1 set abstraction
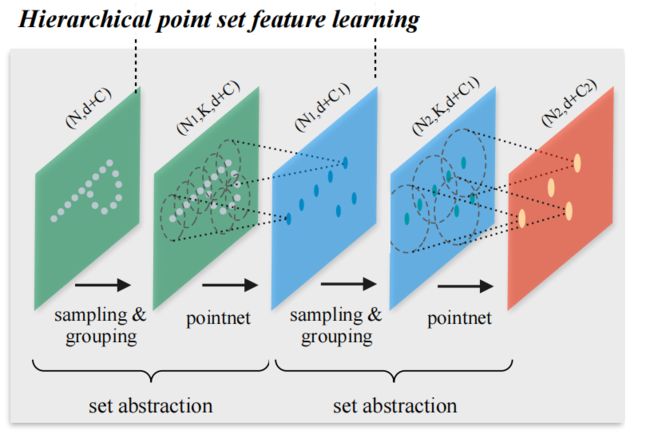
用两个SA(set abstraction)组成多层点集特征学习网络,SA由三个关键层组成:采样层,分组层和PointNet层。
采样层从输入点中选择一组点,这些点定义了局部区域的质心。 然后,分组层通过查找质心的相邻点来构建局部区域集。PointNet层使用mini-PointNet将局部区域编码为特征向量。
2.1.1 输入:
SA采用 N × ( d + c ) N\times(d+c) N×(d+c)矩阵作为输入
其中:
d代表d维坐标,比如xyz坐标中d=3;
c代表c维特征;
2.1.2 输出:
它输出具有d-dim坐标的 N’个子采样点的N’×(d + C’)矩阵和总结局部上下文的新 C’-dim特征向量。
( N , ( d + c ) ) (N,(d+c)) (N,(d+c)) ————> ( N ′ , ( d + c ) ) (N',(d+c)) (N′,(d+c)) ————> ( N ′ , ( d + c ′ ) ) (N',(d+c')) (N′,(d+c′))
图中k是区域中的k个点
2.1.3 Sampling layer
最远点采样,网上介绍太多,不讲。
其实最远点采样会丢失点云的强度信息,看看后面有什么发现吧。
2.1.4 Grouping layer
( N , ( d + c ) ) (N,(d+c)) (N,(d+c)) ————> ( N ′ , k , ( d + c ) ) (N',k,(d+c)) (N′,k,(d+c))
K最近邻(kNN)/Ball query,太多,不讲
2.1.5 PointNet layer
( N , k , ( d + c ) ) (N,k,(d+c)) (N,k,(d+c)) ————> ( N , ( d + c 1 ) ) (N,(d+c1)) (N,(d+c1))
作者还把k个点坐标替换成质心的相对坐标,意义何在,不知道。
2.2 Classification

分类任务:直接最大池化再经过全连接层 ( f c ) (fc) (fc)进行全局分类。
2.3 Segmentation
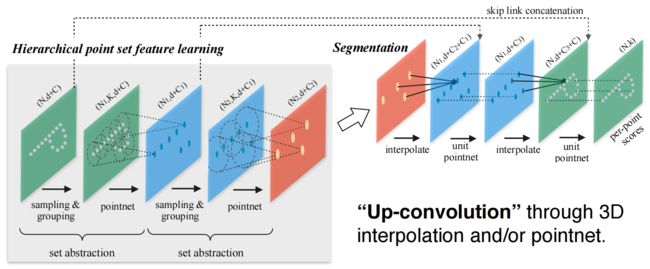
分割任务:往回插值和向上卷积得到每个点的分类,好好思考网络的过程就可以理解。
2.4 总结构
 最终得到整个网络。
最终得到整个网络。
四、难点
分组过程中,点的稠密与稀疏会影响特征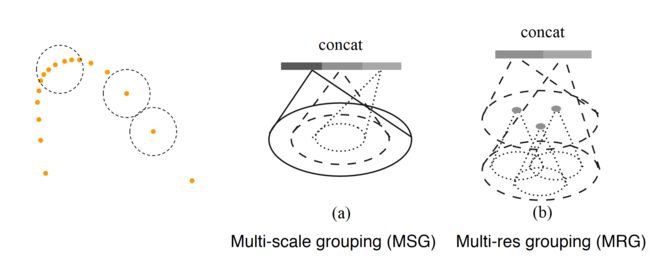
MSG:广度
MRG:深度
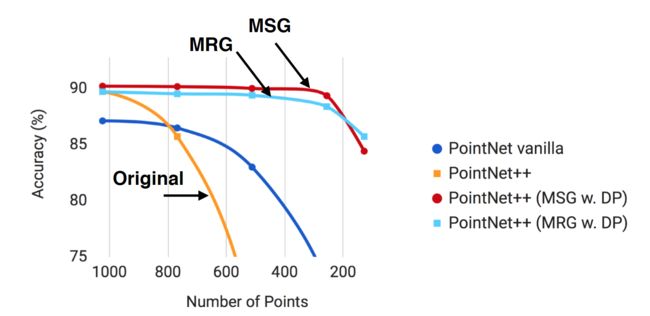
性能测试,随机丢失点:
五、结果
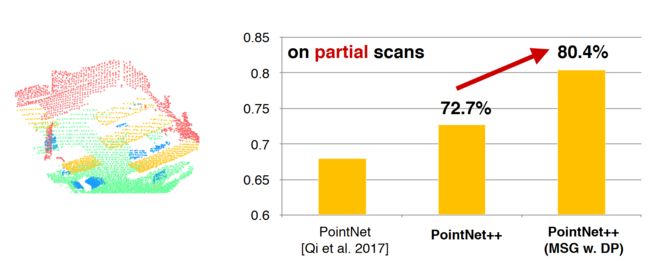
Scene Parsing
Better accuracy with hierarchical learning

Robust layers for non-uniform densities (MSG) helps a lot
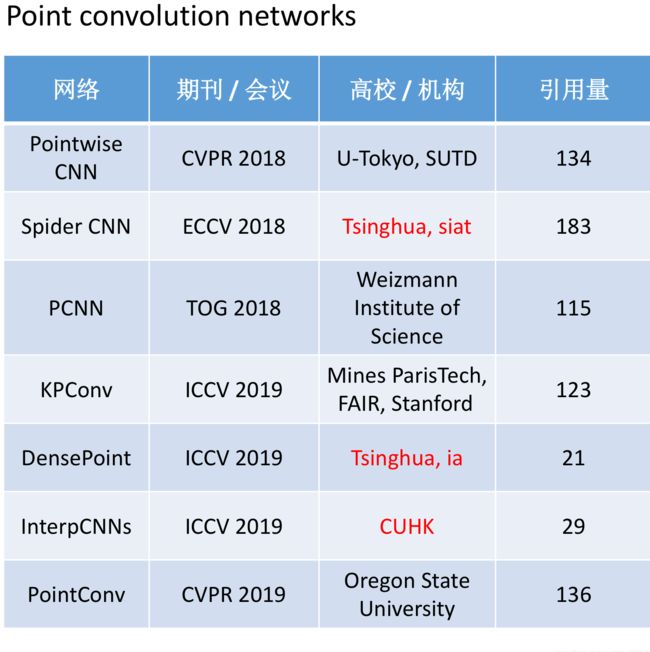
六、总结
一句话总结:分组操作使得点与点之间有了联系,使得局部特征提取有了可能。点的体素化是为了使用cnn,分组操作让pointnet也可以使用cnn思想,而且是直接处理点,因为之前说过pointnet就是为了直接处理点获得特征。所以pointnet的精髓在于分组思想。
最远点采样采集的点大部分都是稀疏点,越密集的地方采集越少,会使得分组得到的点非常少