基于高频词抽样+负采样的CBOW模型
深度学习入门小菜鸟,希望像做笔记记录自己学的东西,也希望能帮助到同样入门的人,更希望大佬们帮忙纠错啦~侵权立删。
✨word2vector系列展示✨
一、CBOW
1、朴素CBOW模型
word2vector之CBoW模型详解_tt丫的博客-CSDN博客
2、基于分层softmax的CBOW模型
基于分层softmax的CBoW模型详解_tt丫的博客-CSDN博客
3、基于高频词抽样+负采样的CBOW模型
本篇
二、Skip_Gram
word2vector之Skip_Gram模型详解_tt丫的博客-CSDN博客
(关于Skip_Gram的分层softmax和负采样,与CBOW类似)
目录
一、前言介绍
1、朴素CBOW模型原理与代码实现
2、基于分层softmax的CBOW模型介绍
二、使用高频词抽样+负采样的原因简述
三、具体实现
1、对高频词进行抽样
2、负采样
四、代码实现
一、前言介绍
1、朴素CBOW模型原理与代码实现
word2vector之CBoW模型详解_tt丫的博客-CSDN博客
2、基于分层softmax的CBOW模型介绍
基于分层softmax的CBoW模型详解_tt丫的博客-CSDN博客
二、使用高频词抽样+负采样的原因简述
同样的,采用这样的方法也是为了解决softmax过程的计算性能问题。
对高频次的单词进行抽样可以减少训练样本的个数;而对优化目标采用负采样的方法,可以让每个训练样本的训练只会更新一小部分的模型权重,从而减少计算负担。
三、具体实现
1、对高频词进行抽样
需要这样处理的原因:
比如说一大段文字中出现了很多的“the”,但是这个“the”并没有包含多大的信息量,文本中的“the”的数量远超过我们需要训练“the”的样本数量。所以我们需要有选择性的对文章中的一些词进行删除。
主要思想:
对于出现在训练文中的每个单词,都会有一个被删除的概率,这个概率取决于相应单词的词频。
而具体删除的概率除了与词频有关,还和我们设定的采样率有关。
公式说明:
这个删除的概率(抽样率)的公式如下:
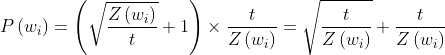
其中:![]() 是词
是词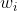 在语料中的出现概率;t是设定的阈值,即采样率(gensim word2vec中默认值是1e-3)。
在语料中的出现概率;t是设定的阈值,即采样率(gensim word2vec中默认值是1e-3)。
2、负采样
需要这样处理的原因:
在最初的时候,对于每个词w, 都要更新一次hidden->output的参数阵——大小为N ∗ V的W’,这个计算量挺恐怖的
主要思想:
从【之前的每次更新大小为N ∗ V的W’】转变为【每次只更新目标词(正例)和少数几个负例(非目标词)】,这样计算量就显著降低了
注:
在论文中作者指出对于小规模数据集,建议选择 5-20 个负例,对于大规模数据集选择 2-5个 负例
负例的选择:
根据词典中出现的概率,出现概率越高,被选作负样本的概率越高
具体的概率公式:
其中:
是词

四、代码实现
(Ps:1.txt文件是我随便输几行英文进去的,数据量太少了,训练出来的结果有些离谱,不要管它)
我们可以直接使用gensim中的Word2Vec
首先导入库
from gensim.models import Word2Vec然后对文本进行一个处理,每句每句地分好词
path = "1.txt"
f = open(path, 'r', encoding= 'utf-8', errors= 'ignore')
word_list = []
piece = ''
for line in f:
text = []
for uchar in line:
if uchar == '\n':
continue
if uchar == '.' or uchar == '?' or uchar == '!':
text.append(piece)
piece = ''
else:
piece = piece + uchar
word_list.append(text)
#print(text)
for i in range(len(word_list)):
word_list[i] = " ".join(word_list[i]).split()处理后的word_list是
[['I', 'have', 'a', 'pen'], ['I', 'love', 'this', 'pen'], ['I', 'have', 'an', 'apple'], ['I', 'love', 'eating', 'apples'], ['You', 'have', 'a', 'book']]
利用gensim中的Word2Vec,送进模型,进行训练
model = Word2Vec(sentences=word_list, alpha=0.025, window=5, min_count=1, max_vocab_size=None, sample=0.001, seed=1, workers=3, min_alpha=0.0001, sg=0, hs=0, negative=5, ns_exponent=0.75, cbow_mean=1, null_word=0, trim_rule=None, sorted_vocab=1, batch_words=10, compute_loss=False, callbacks=(), max_final_vocab=None)有关Word2Vec的用法——参数意义(只对比较重要的参数进行说明)
一般情况下我们只需要对(1),(4),(7),(8)这些进行设置
(1)sentence:输入的待训练的数据
(2)alpha: 学习速率
(3)window:当前词与预测词在一个句子中的最大距离是多少
(4)min_count: 可以对字典做截断——词频少于min_count次数的单词会被丢弃掉, 默认值为5
(这里有点类似上面说的高频词抽样)
【注:这里如果你的sentence是特别少的那种,这里的min_count就需要你调小点,要不然全无了】
(5)sample:高频词汇的随机降采样的配置阈值,默认为1e-3,范围是(0,1e-5)
(其实这里才是真正的上面所说的高频词抽样啦~对应那个采样率)
(6)seed:用于随机数发生,和初始化词向量有关
(7)worker:控制训练的并行数
(8)sg:设置训练算法:0(默认值)对应CBOW算法;1对应skip-gram算法
(9)hs:1对应分层softmax,0(默认值)对应负采样
(10)negative:用于设置负采样使用多少个负例
(11)cbow_mean:如果为0,则采用上下文词向量的和,如果为1(默认值)则采用均值
(这里对应CBOW模型的INPUT到投影层那里的操作选择)
(12)batch_words:一次训练送进多少词
训练完的结果展示
(1)模型打印
print(model)输出展示
Word2Vec(vocab=12, vector_size=100, alpha=0.025)
(2)词汇打印
words = list(model.wv.key_to_index)
print(words)输出展示
['I', 'have', 'love', 'pen', 'a', 'book', 'You', 'apples', 'eating', 'apple', 'an', 'this']
(3)输入某个单词进行相关度预测
print(model.wv.most_similar(u'pen'))# 返回和这个词语最相关的多个词语以及对应的相关度
print(model.wv.similarity(u'pen', u'apple'))#返回两个词间的相关度输出展示
[('book', 0.13149002194404602), ('eating', 0.07497558742761612), ('have', 0.06797593086957932), ('You', 0.04157734289765358), ('this', 0.04130810499191284), ('an', 0.012979976832866669), ('love', -0.013514931313693523), ('apples', -0.013679743744432926), ('a', -0.044616494327783585), ('I', -0.11166462302207947)] -0.16937022
欢迎大家在评论区批评指正,谢谢啦~