卷积神经网络基本原理
目录
什么是全连接神经网络?
神经元的基本结构
神经元的激活函数
sigmoid函数
Relu函数
全连接神经网络的缺点
卷积神经网络
卷积神经网络的由来
卷积层
汇聚层
实例
什么是全连接神经网络?
 这张图片在视网膜形成图像后被转换成神经冲动,然后经过视觉神经的传导信号到达大脑,经过大脑皮层对信号的处理我们可以得出判断,这是一只猫,当然有些人可能再根据它的颜色和花纹继而判断出这是一只美短。
这张图片在视网膜形成图像后被转换成神经冲动,然后经过视觉神经的传导信号到达大脑,经过大脑皮层对信号的处理我们可以得出判断,这是一只猫,当然有些人可能再根据它的颜色和花纹继而判断出这是一只美短。
再抽象一下刚才的传递路径,信息由视网膜接收,信号传递到视觉神经,最后再传到大脑皮层,当然这其中的每一层都是由很多神经元组成,前一层的神经元连接着下一层的神经元,这就组成了一个简单的神经网络模型,在前面的这一列是输入层神经元,中间的一列是隐藏层,最后的一层是输出层。这幅图中的隐藏层我只画出来了一层,实际上是可以有很多层的,层和层之间是全连接的结构,同一层的神经元之间没有连接。这种神经网络也叫做全连接神经网络。
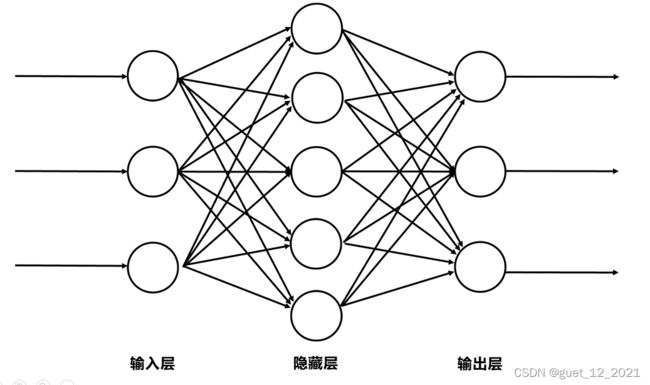
输入层(Input layer):众多神经元(Neuron)接受大量非线形输入讯息。输入的讯息称为输入向量。
输出层(Output layer)讯息在神经元链接中传输、分析、权衡,形成输出结果。输出的讯息称为输出向量。
隐藏层(Hidden layer):简称“隐层”,是输入层和输出层之间众多神经元和链接组成的各个层面。如果有多个隐藏层,则意味着多个激活函数
神经元的基本结构

·X1、X2表示输入向量
·W1、W2为权重,几个输入则意味着有几个权重,即每个输 入都被赋予一个权重
·b为偏置bias
·g(z)为激活函数
·a为输出值
举个例子,我们决定晚上去不去食堂吃饭,假如有两个决定因素,首先是食堂有没有你喜欢的饭菜,其次是有没有人陪你一起去,这二个因素可以对应二个输入,分别用x1、x2表示。此外,这二个因素对做决策的影响程度不一样,各自的影响程度用权重w1、w2表示。
X1:代表有没有你喜欢的饭菜,x1=1代表有,X1=0代表没有,假设它的权重是7.
X2:代表是否有人陪你去,x2=1代表有,X2=0代表没有,是否有人陪同的权重 = 3。
这样,咱们的决策模型便建立起来了:g(z) = g( x1*w1 +x2 *w2 + b ),g表示激活函数,这里的b可以理解成为更好达到目标而做调整的偏置项。
神经元的激活函数
常用的非线性激活函数有sigmoid、tanh、relu等等,前两者sigmoid/tanh比较常见于全连接层,后者relu常见于卷积层。这里先简要介绍下最基础的sigmoid函数
sigmoid函数
函数表达式: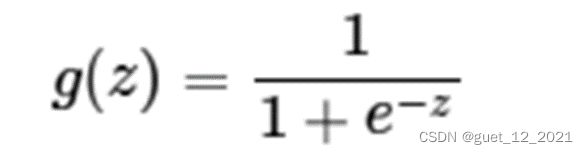 z是一个线性组合,比如z= x1*w1 +x2 *w2 + b
z是一个线性组合,比如z= x1*w1 +x2 *w2 + b
函数图像:
sigmoid函数的缺点:
(1)激活函数的计算量大,反向传播求误差梯度时,求导涉及到除法。
(2)反向传播的时候,很容易出现梯度消失的情况,从而无法完成深度神经网络的训练,所以现在很少有用这个函数
Relu函数
函数表达式:g(z)=max(0,z)
函数图像: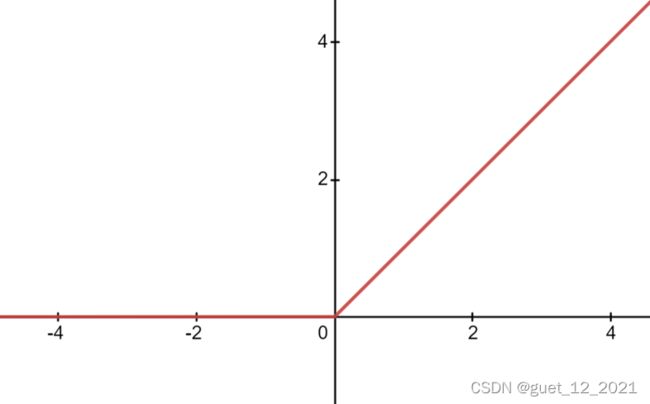
Relu函数的优点:
(1)在随机梯度下降算法中收敛速度够快。
(2)不会出现像Sigmoid那样梯度消失问题。
(3)提供了网络稀疏表达能力。
(4)在无监督训练中也有良好的表现。
全连接神经网络的缺点

全连接神经网络的参数是非常多的,假如输入层处理100*100的图像即10000个神经元,中间层有1000个神经元,那么就有10的7次方个参数,这个数量是非常大的,在训练的时候要训练到这么多的参数需要用海量样本,样本太少的话就会陷入过拟合。同时全连接神经网络对输入图像的干扰是非常敏感的,我们把修改后的图像输入到全连接神经网络中会对其输出产生影响,同时全连接神经网络很难提取图像的局部特征。
卷积神经网络
卷积神经网络的由来
卷积神经网络(Convolutional Neural Networks, CNN)是受生物学上感受野(ReceptiveField)的机制而提出的,在视觉神经系统中,一个神经元的感受野是指视网膜上的特定区域,只有这个区域内的刺激才能够激活该神经元。
卷积神经网络是一种具有局部连接、权重共享等特性的深层前馈神经网络
卷积神经网络的整体结构如下:
卷积层
什么是卷积?
对图像(不同的数据窗口数据)和滤波矩阵(一组固定的权重:因为每个神经元的多个权重固定,所以又可以看做一个恒定的滤波器filter)做内积(逐个元素相乘再求和)的操作就是所谓的『卷积』操作,也是卷积神经网络的名字来源。
非严格意义上来讲,下图中红框框起来的部分便可以理解为一个滤波器,即带着一组固定权重的神经元。多个滤波器叠加便成了卷积层。

举个具体的例子。比如下图中,图中左边部分是原始输入数据,图中中间部分是滤波器filter,图中右边是输出的新的二维数据。
在下图对应的计算过程中,输入是一定区域大小(width*height)的数据,和滤波器filter(带着一组固定权重的神经元)做内积后等到新的二维数据,也就是特征映射。
具体来说,左边是图像输入,中间部分就是滤波器filter(带着一组固定权重的神经元),不同的滤波器filter会得到不同的输出数据,比如颜色深浅、轮廓。相当于如果想提取图像的不同特征,则用不同的滤波器filter,提取想要的关于图像的特定信息:颜色深浅或轮廓。

在CNN中,滤波器filter(带着一组固定权重的神经元)对局部输入数据进行卷积计算。每计算完一个数据窗口内的局部数据后,数据窗口不断平移滑动,直到计算完所有数据。这个过程中,有这么几个参数:
b. 步长stride:决定滑动多少步可以到边缘。
c. 填充值zero-padding:在外围边缘补充若干圈0,方便从初始位置以步长为单位可以刚好滑倒末尾位置,通俗地讲就是为了总长能被步长整除 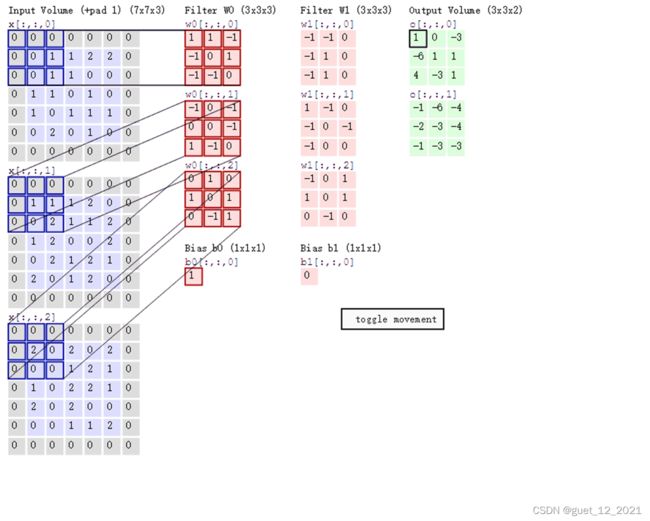
可以看到:
然后分别以两个滤波器filter为轴滑动数组进行卷积计算,得到两组不同的结果。
卷积层的两个重要特征:
局部连接:在卷积层中每一个神经元都只与前一层中某个局部窗口内的神经元相连,构成一个局部连接网络,卷积层和前一层之间的连接数大大减少,由原来的i∗M_i∗ i−1个M_(i-1) 个连接变成了iM_i*K个连接,K为卷积核大小。
权重共享:从之前的例子可以看出,作为参数的卷积核w对于第i层的所有神经元都是相同的,权重共享可以理解为一个卷积核只捕捉输入数据中的一个特定的局部特征,因此如果要提取多种特征就要使用多种不同的卷积核
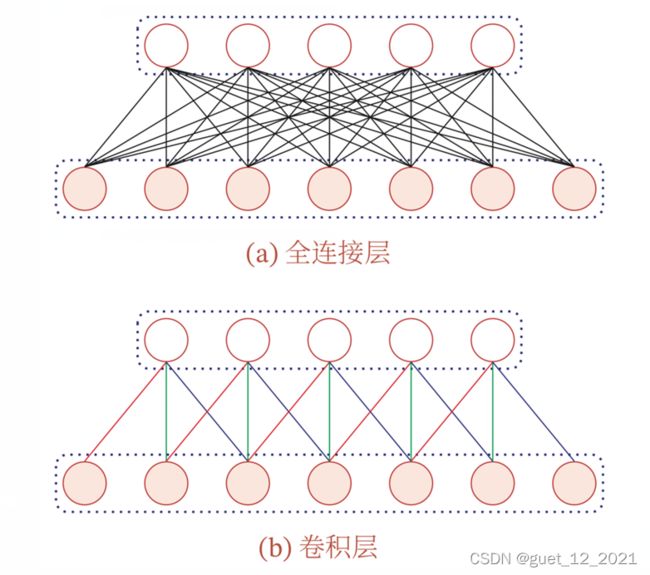
由于局部连接和权重共享,卷积层的参数只有一个K维的权重和1维的偏置b,共K+1个参数,参数的个数和神经元的数量无关。
汇聚层
汇聚层(Pooling Layer)也叫做池化层、子采样层,其作用是进行特征选择,降低特征数量,从而减少参数数量。
卷积层虽然可以显著减少网络中连接的数量,但特征映射组中的神经元个数没有显著减少,如果后面接一个分类器,分类器的输入维数依然很高,很容易出现过拟合,可以在卷积层之后加上一个汇聚层,从而降低维数,避免过拟合。
常用的汇聚函数有两种:
(1)最大汇聚:对于一个区域 ,选择这个区域内所有神经元的最大活性值作为这个区域的表示,即:

(2)平均汇聚:一般是取区域内所有神经元活性值的平均值,即:
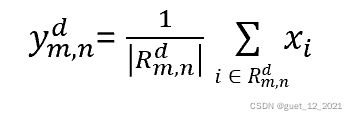
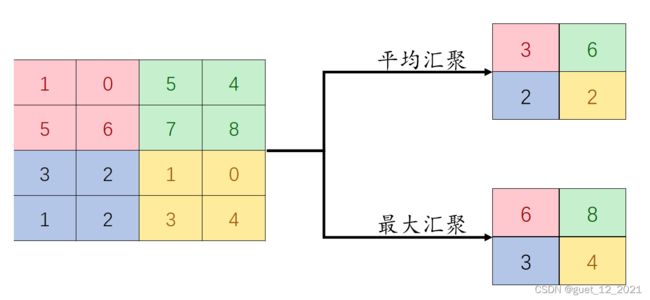
可以看出,汇聚层不但可以有效地减少神经元的数量,还可以使得网络对一些小的局部形态改变保持不变性,并用有更大感受野

一个卷积块为连续M个卷积层和b个汇聚层(M通常设置为2~5,b为0或1)。一个卷积网络中可以堆叠N个连续的卷积块,然后在后面接着K个全连接层(N的取值比较大,比如1~100或者更大,K一般为0~2)
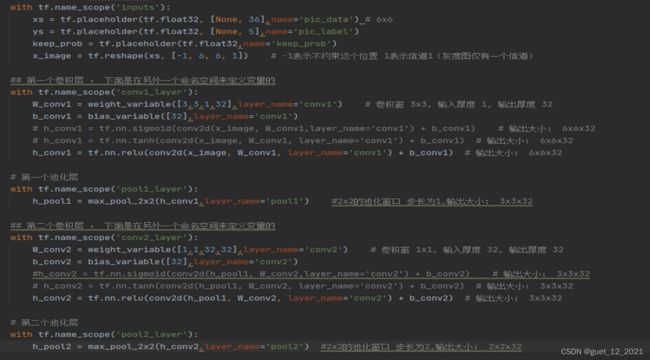
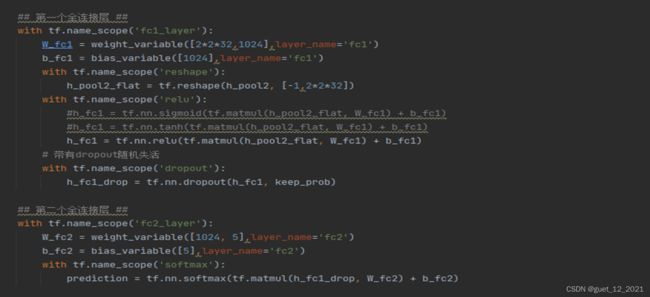
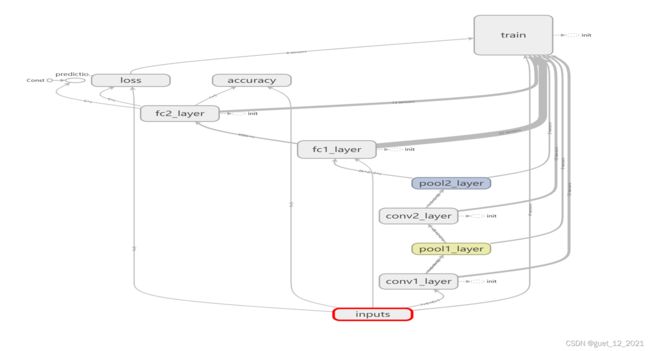
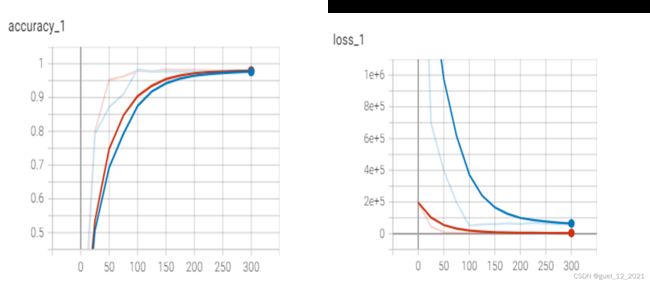
实例
KDD-CPU99数据集是最早的网络数据集,7周的数据经处理约有5百万条“连接”记录; 测2周的tcpdump数据是,约2百万条“连接”记录;数据集中添加了很多模拟的攻击。KDD-CPU99数据集分为训练集和测试集,将数据集中的数据用来识别网络中的攻击。每条数据包括41个属性,包括持续连接时间、访问系统敏感文件的次数和过去时间内与当前连接的目标主机数等。在数据集中,每条数据都有一位标签,标注了每条数据的正常或者攻击属性。
攻击类型被分为四大类:

(1)将数据集中的字符型属性特征转化为数值型特征:在使用数据集之前,需要先对数据进行处理,将数据集中的字符型属性转换为相应的数字表示,如将数据集文件的网络协议类型的TCP、UDP和ICMP分别转化为1,2,3相应的数字表示;将数据集文件的网络服务类型的aol、auth、bgp等70种转换成相应的数字标识,将数据集文件中网络连接状态的OTH、REJ、RSTO等11种转换成相应的数字标识。
(2)采用独热编码对标签进行处理:主要是针对离散的特征进行编码,将特征值映射到具体数值上,将每一个特征值表示为二进制向量,除了具体的数值索引之外,其他位置都用零表示。如将 用[1,0,0,0,0]表示normal(正常)数据,用[0,1,0,0,0]表示DOS(拒绝服务攻击)数据,用[0,0,1,0,0]表示R2L数据(来自远程主机的未授权访问),用[0,0,0,1,0] 表示U2R(未授权的本地超级用户特权访问数据),用[0,0,0,0,1]表示PROBING(端口监视或扫描)数据。
注:独热编码(One-Hot编码)又称为一位有效编码,独热编码的原理是在任意时刻只存在一位有效位来表示相应的状态属性,有多少种状态属性就采用多少位进行编码,采用独热编码的方法可以很好的避免数值大小对结果的影响。