卷积神经网络 CNN 简述
文章目录
- 所解决的问题
-
- 需要处理的数据量太大
- 很难保留图像特征
- 基本原理
-
- 卷积层 —— 提取图像特征
- 池化层 —— 数据降维(避免过拟合)
- 全连接层 —— 输出结果
- 实际应用
-
- 图像分类、检索
- 目标检测
- 图像分割
- 自然语言处理
- 参考资料
所解决的问题
在卷积神经网络(CNN)出现之前,图像对于人工智能来说是一个难题,有 2 个原因:
- 图像需要处理的数据量太大,导致成本很高,效率很低
- 图像在数字化的过程中很难保留原有的特征,导致图像处理的准确率不高
需要处理的数据量太大
图像是由像素构成的,每个像素又是由颜色构成的:例如一张 1,000×1,000 像素的图片,每个像素点都有 RGB 参数来表示颜色,则一张图片就对应着 3×1,000×1,000 = 3,000,000 个参数,那么处理图片需要的计算资源与存储资源都会极大。
而卷积神经网络解决的第一个问题就是「将复杂问题简单化」:在降低参数量的同时,尽可能保持原数据的数据特征(直观理解:图片变模糊的同时,不影响我们人类分辨出图片中的内容)。
这一步的核心其实就是对数据进行降维/嵌入
很难保留图像特征
举个例子,两张拥有对称内容的图片,他们的内容(本质)没有任何不同,唯一的不同只有进行了“左右翻转”,而在线性的向量表示(即对一个 1,000×1,000 像素的图片,生成 [1, 1000000, 3] 的向量)中,其有相当大的变化。
而卷积神经网络解决的第二个问题就是「以视觉的方式看待图像数据」:即在图像作反转、旋转、移动、缩放等操作时,机器都能像人类一样,认识到这些图片都是同一内容。
这一步的核心其实就是使用视觉原理捕获图像数据中的数据特征
基本原理
典型的 CNN 由「卷积层」「池化层」「全连接层」3 个部分构成:
- 卷积层:负责提取图像中的局部特征
- 池化层:大幅降低参数量级(降维)
- 全连接层:类似传统神经网络的部分,用来输出想要的结果
卷积层 —— 提取图像特征
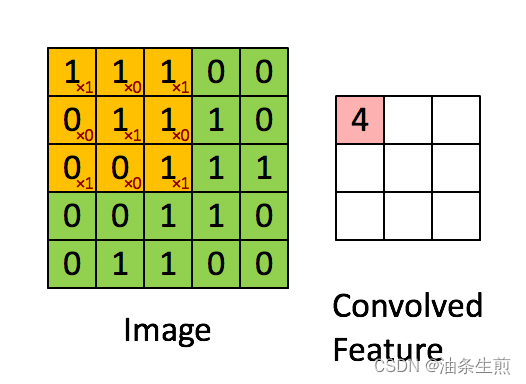
卷积可以理解为使用一个过滤器(卷积核)来过滤图像的各个小区域,从而得到这些小区域的特征值。
在具体应用中,往往有多个卷积核,可以认为「每个卷积核代表了一种图像模式」,如果某个图像块与此卷积核卷积出的值大,则认为此图像块十分接近于此卷积核。
如果我们设计了 6 个卷积核,可以理解:我们认为这个图像上有 6 种底层纹理模式,也就是我们用 6 种基础模式就能描绘出一副图像。
卷积层通过卷积核的过滤提取出图片中局部的特征,与人类视觉的特征提取类似。
池化层 —— 数据降维(避免过拟合)
池化层简单说就是下采样,他可以大大降低数据的维度。
需要池化层的原因:即使做完了卷积,图像仍然很大(因为卷积核通常比较小),所以为了降低数据维度,就进行下采样。
池化层函数实际上是一个统计函数,例如最大池化、平均池化、累加池化等。
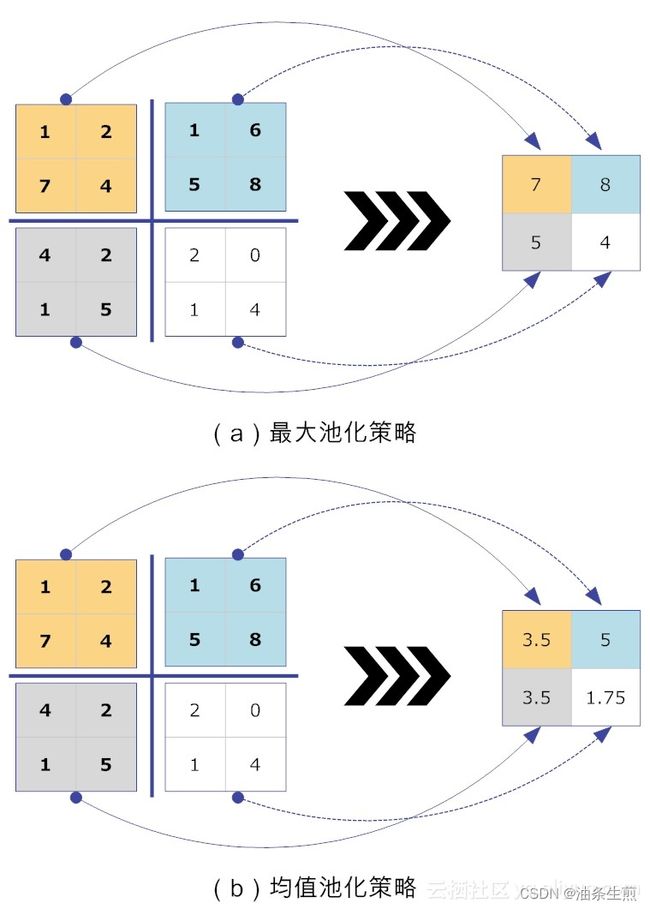
那么池化层函数会不会对图像数据产生副作用呢?
答案是:一般不会。
关于池化层,有一个局部线性变换的不变性(invariant)理论:如果输入数据的局部进行了线性变换操作(如平移或旋转等),那么经过池化操作后,输出的结果并不会发生变化。
局部平移“不变性”特别有用,尤其是我们关心某个特征是否出现,而不关心它出现的位置时(例如,在模式识别场景中,当我们检测人脸时,我们只关心图像中是否具备人脸的特征,而并不关心人脸是在图像的左上角和右下角)。
为什么池化层可以降低过拟合的概率呢?
因为池化函数使得模型更关注偏全局的特征(而非局部),所以可以尽量避免让模型专注于图像的一些特化细节(例如让模型更关注一张人脸,而不是他眼睛的大小)。
总结:池化层相比卷积层可以更有效的降低数据维度,这么做不但可以大大减少运算量,还可以有效的避免过拟合。
全连接层 —— 输出结果
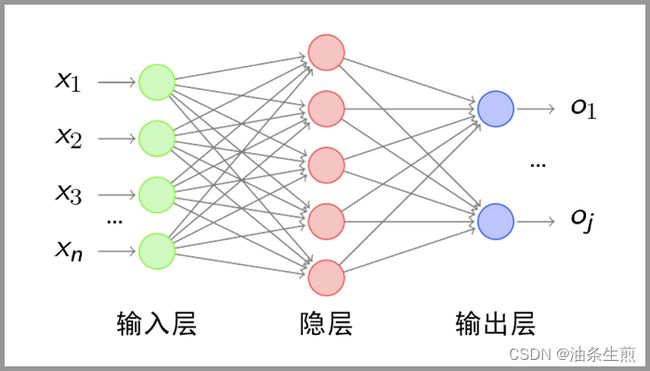
经过卷积层和池化层处理过的数据输入到全连接层,得到最终想要的结果。
经过卷积层和池化层降维过的数据,全连接层才能”跑得动”,不然数据量太大,计算成本高,效率低下。
“全连接”意味着,前层网络中的所有神经元都与下一层的所有神经元连接。
全连接层设计目的在于:它将前面各个层学习到的“分布式特征表示”映射到“样本标记空间”,然后利用损失函数来调控学习过程,最后给出对象的分类预测。
虽然池化层看似是整个网络结构中最不起眼的一步,但是由于其对所有的参数进行“连接”,其会造成大量的冗余参数,不良的设计会导致在全连接层极易出现「过拟合」的现象,对此,可以使用 Dropout 方法来缓解;同时其极高的参数量会导致性能降低,对此,颜水成博士团队曾发表论文 Network in Network(NIN)[4],提出使用全局均值池化策略(Global Average Pooling,GAP)取代全连接层。
实际应用
图像分类、检索
图像分类是比较基础的应用,他可以节省大量的人工成本,将图像进行有效的分类。对于一些特定领域的图片,分类的准确率可以达到 95%+,已经算是一个可用性很高的应用了。

在计算机视觉分类算法的发展中,MNIST 是首个具有通用学术意义的基准。这是一个手写数字的分类标准,包含 60000 个训练数据,10000 个测试数据,图像均为灰度图,通用的版本大小为 28×28。
在 20 世纪 90 年代末与 21 世纪初时,SVM 与 KNN 方法被较多地使用,以 SVM 为代表的方法可以将 MNIST 分类错误率降低到 0.56%,超过了以 LeNet 系列为代表的神经网络方法(LeNet5 的错误率为 0.7% 左右)。
在本世纪的早期,神经网络开始有复苏的迹象,但是受限于数据集规模与硬件的发展,神经网络的训练与优化仍较为困难:MNIST 只有 60,000 张图片,只进行 10 分类任务,对于工业界的落地要求远远不够。
2009 年,在李飞飞等人的经过数年的整理下,ImageNet 数据集发布,其包含 14,000,000+ 的图片量,涵盖了 20,000+ 的类别,在论文方法的比较中常用的是 1,000 类的基准。
在 ImageNet 发布的早期,仍然以 SVM 与 Boost 等传统的机器学习方法为主,直到 2012 年 AlexNet 的出现。AlexNet 是第一个真正意义上的深度网络,与 LeNet5 的 5 层相比,其网络层数增加了 3 层,网络参数大大增加,输入从 28 变成了 224,同时 GPU 的面世,使得深度学习从此进行 GPU 为王的训练时代。
2014 年的冠亚军网络分别是 GoogLeNet 和 VGGNet。
2015 年,ResNet 获得了分类任务冠军。
2016 年依旧诞生了许多经典的模型,包括赢得分类比赛第二名的 ResNeXt,101 层的 ResNeXt 可以达到 ResNet152 的精确度。
目标检测
可以在图像中定位目标,并确定目标的位置及大小。
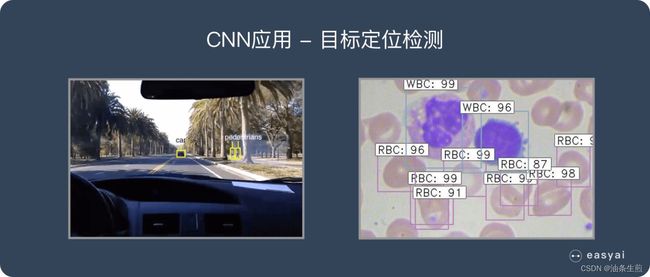
图像分割
简单理解就是一个像素级的分类。
他可以对前景和背景进行像素级的区分、再高级一点还可以识别出目标并且对目标进行分类。
典型场景:美图秀秀、视频后期加工、图像生成等

自然语言处理
除了在图像处理领域,CNN 在自然语言处理(Natural Language Processing,NLP)领域也有相当的建树。
在「以句子为粒度的文本分类」任务中,Zhang et al. [5] 在论文 A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification 中使用 CNN 对句向量进行特征提取:
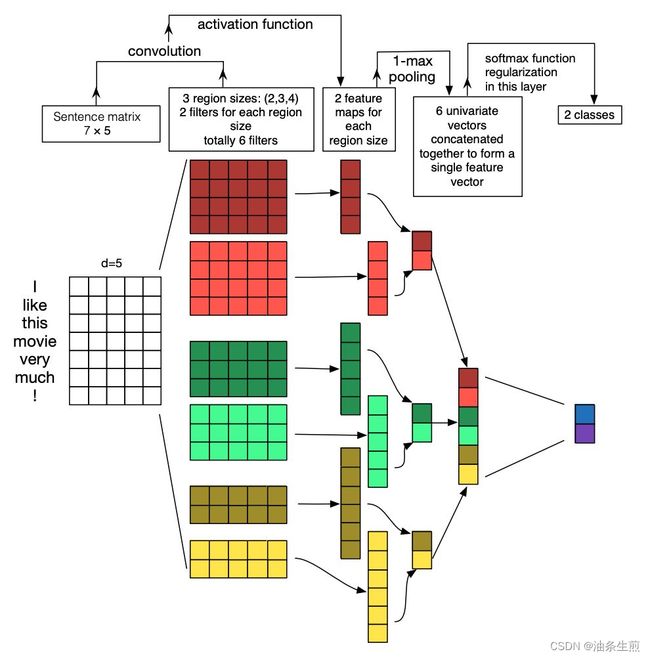
在「Emotion-Cause Pair Extraction」任务中,Chen et al. [6] 在论文 A Unified Sequence Labeling Model for Emotion Cause Pair Extraction 中使用 CNN 对由多个句向量组合而成的矩阵进行卷积,以获取段落的上下文信息(Context Information):
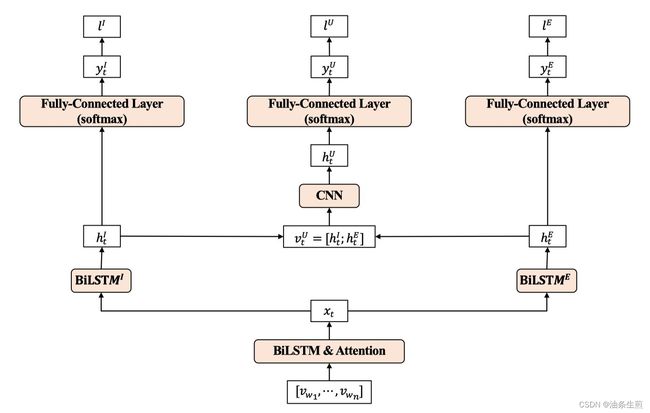
在「Knowledge Graph Embedding」任务中,Dettmers et al. 在论文 Convolutional 2D Knowledge Graph Embeddings(ConvE)[7] 中提出对知识图谱三元组(头实体 head entity、关系 relation 与尾实体 tail entity)中的头实体与关系进行 2D 的卷积操作,以通过 embedding 之间的交互来增强模型的表示能力:

参考资料
- 一文看懂卷积神经网络-CNN(基本原理+独特价值+实际应用)- 产品经理的人工智能学习库
- 【深度学习】激活引入非线性,池化预防过拟合_Wendy冬雪飘的博客-CSDN博客_池化层防止过拟合
- 神经网络基本组成 - 池化层、Dropout层、BN层、全连接层 13
- Lin M, Chen Q, Yan S. Network in network[J]. arXiv preprint arXiv:1312.4400, 2013.
- Zhang Y, Wallace B. A sensitivity analysis of (and practitioners’ guide to) convolutional neural networks for sentence classification[J]. arXiv preprint arXiv:1510.03820, 2015.
- Xinhong Chen, Qing Li, and Jianping Wang. 2020. A Unified Sequence Labeling Model for Emotion Cause Pair Extraction. In Proceedings of the 28th International Conference on Computational Linguistics, pages 208–218, Barcelona, Spain (Online). International Committee on Computational Linguistics.
- Dettmers T, Minervini P, Stenetorp P, et al. Convolutional 2d knowledge graph embeddings[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2018, 32(1).
- 龙鹏-笔名言有三:【技术综述】你真的了解图像分类吗?
- Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks[J]. Advances in neural information processing systems, 2012, 25.