IHDR:增量式分层判别回归
前面已经介绍了翁巨扬教授两个心智发育框架(IHDR+WWN)的核心算法CCIPCA和CCILCA,下面就IHDR这个框架来做一下详细的介绍,主要参考资料为IHDR原始论文,以及实验室师兄们前期的工作成果。后面再说一下where-what-network系列(先立个flag,希望不是在作死)。
一、如何衡量一个数据集的纯度?
定义一下什么纯度?一个数据集如果包含多个类别的样本,包含类别数越多,就认为这个数据集越不纯,反之,越纯,这里的纯指的是纯粹,单一。类别数越单一,表明数据集越纯(pure)。
假设存在两个数据集![]() ,B为A的子集,其中
,B为A的子集,其中![]() 表示小明的人脸数据,
表示小明的人脸数据,![]() 表示小红的人脸数据。那么,从主观上来讲,数据集A的方差要大于数据集B的方差,因而,一般而言,类间方差大于类内方差(LDA),因此,如果一个样本集方差越小,这个样本集越纯的可能性越大。
表示小红的人脸数据。那么,从主观上来讲,数据集A的方差要大于数据集B的方差,因而,一般而言,类间方差大于类内方差(LDA),因此,如果一个样本集方差越小,这个样本集越纯的可能性越大。
二、如何将一个不纯的数据集分割成多个纯的子数据集?
一个最常见的办法就是聚类,按照某种相似性评定准则,将样本集中相似的样本归为一个类别,但是常规的聚类方式又存在以下几个问题:
1、设置聚类中心数目比较困难:数目过多,计算量过大,实时性难以满足要求,数目过少,又无法得到满意的聚类结果;
2、聚类过程过于耗时:聚类的过程中,反复不停地进行迭代求解,迭代过程十分耗时,同时,如果数据维度过大,那么聚类过程的计算量就更加爆炸;
3、聚类要求样本数据集中所有样本数据已知,也即是,聚类是对一个已知样本集进行操作。
因此,对于一个在线学习系统,常规的聚类方式是不可取的。
三、分类和回归
分类问题,即建立输入数据data到输出标签label之间的映射关系;回归问题,即建立输入数据data到输出动作向量motor之间映射关系。二者之间最大的不同点在于输出部分,classification对应于label(标签),regression对应于vector(向量),如果将label转换成一个数字(虚拟标签),那么一个分类问题就可以划分为一个回归问题。
四、IHDR
IHDR翻译过来就是增量式分层判别回归(实验室师兄们这么翻译的),其基本思想就是:我们能否通过某种方法,将一个不纯数据集划分为N个较纯的子样本集,然后,当输入一个样本数据时,先判断他属于哪一个子样本集,然后,再判断当前样本与哪一个子样本集中的样本最接近,即得到当前样本对应输出动作向量。
4.1 如何快速有效的对当前样本集进行划分?
IHDR采用的双聚类的方式,什么意思?通常,我们获取到的样本数据对应于一个标签(指示类别)或一个向量(指示动作),输入和输出之间应该满足一一对应关系,而且,相较于输入数据(X-Space)而言,输出指示(Y-Space)维度要小的多,因此,可以先在Y-Space上进行聚类,然后在X-Space上进行验证,这样就能快速有效的对已有样本数据进行划分。那么,问题又来了,到底要将当前样本划分为多少个子空间?
4.2 将当前样本空间划分为多少个子空间?
实际上,一次性划分是不现实的,因为在实际场景中,我们只能获取到当前时刻t对应数据,对于t+1,t+2,....时刻数据是不可达的,因此,考虑将划分过程视为一个动态过程,如果当前节点对应样本数大于设定阈值 ,就将当前节点对应数据集划分为q个子数据集,当继续向IHDR树里面添加样本时,样本会被自动划分到子数据集中,如果子数据集中样本数大于设定阈值,就将子数据集划分为q个子子数据集,...............,这样,就可以增量式将数据集划分为M个子样本集,过程如图1所示。
,就将当前节点对应数据集划分为q个子数据集,当继续向IHDR树里面添加样本时,样本会被自动划分到子数据集中,如果子数据集中样本数大于设定阈值,就将子数据集划分为q个子子数据集,...............,这样,就可以增量式将数据集划分为M个子样本集,过程如图1所示。
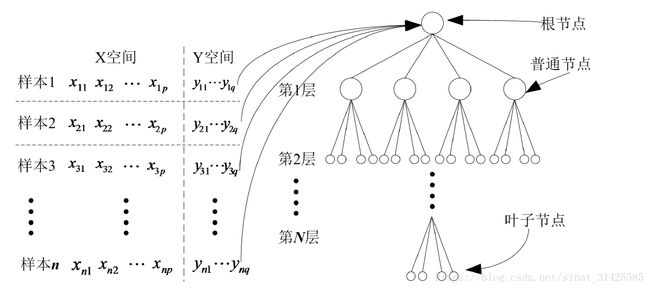
图1 IHDR树构建过程(摘自文献[2])
那么,问题来了,我们怎么样决策,当前样本属于哪一个子样本集?
4.3 如何决定当前样本应该划分到哪一个子集?
我们先看一下样本分布示意,如图2所示。

图2 样本分布示意图(摘自文献[1])
图2中,黑点代表当前子样本集的中心,不难发现,如果一个样本属于某一个子样本集,那么,当前样本就与该子样本集的中心更加贴近,因此,我只需要判断当前样本距离那个子样本集的中心最近,就可以判断该样本属于那个子样本集了。
这里又出现了一个问题,如果每个节点都对应一个样本集,也即是每个节点都保存其对应样本集,这样就会出现大量重复保存,实际上也不需要这样子,IHDR树中,仅仅是叶子节点中保存样本,中间节点只是保存其样本对应的统计模型(样本均值,样本方差,聚类子均值)。
4.4 快速检索
实际上,不管是聚类过程(样本与聚类子中心之间的比对),还是决策过程(在叶子节点对应样本集中进行的样本比对),其性能与样本数据的维度息息相关,因此,考虑将样本投影到最判别的特征空间之中,然后在特征空间中进行比对,这里,得到特征空间的方法,即前面提到的CCIPCA算法。通过CCIPCA算法,即可增量式的评估出当前样本空间对应最判别的特征空间,将样本投影到特征空间之后,为进一步提升决策效率,对应于普通节点,每一个节点建立一个NLL(负对数似然)模型,计算当前样本属于每个聚类子中心的概率。
因此,对于一颗构建好的IHDR树而言,普通节点对应于一个统计模型,叶子节点对应于一个子样本集。
最后,展示一个结果,数据没有经过处理的数据,直接使用IHDR来对其进行分类,可以得到83.19%的识别率:
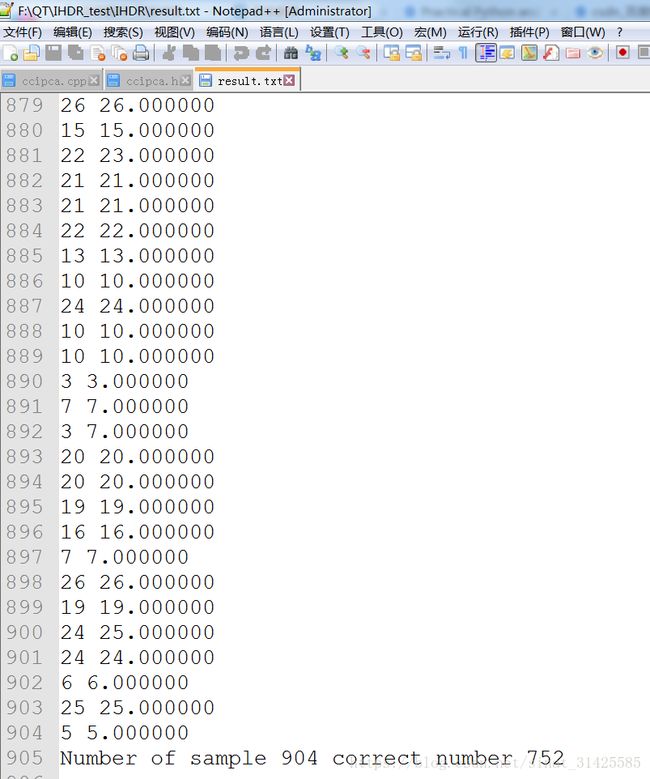
测试代码已上传到github:MirrorYuChen/Developmental-Networks: Some Research C++ Codes on DN, following the works of Juyang Weng professor (github.com)
然后,基于IHDR+QT,跟师妹一起做了一个人脸识别跟踪系统:
https://v.youku.com/v_show/id_XMzc4MTk0NTE3Ng==.html?spm=a2hzp.8244740.0.0
未完待续~~~~~~~
参考文献:
[1] Weng J, Hwang W S. Incremental Hierarchical Discriminant Regression[J]. IEEE Transactions on Neural Networks, 2007, 18(2):397-415.
[2] 李威凌. 基于脑心智发育网络模型的移动机器人场景认知研究[D]. 武汉科技大学, 2016.
[3] 吴怀宇, 李威凌, 钟锐,等. 基于IHDR自主学习框架的轮式移动机器人导航方法:, CN 104850120 A[P]. 2015.
[4] 吴怀宇,钟锐,程果,等.基于压缩跟踪与IHDR增量学习的视频人脸在线识别方法:,CN201611042357.1