Few-shot learning
1. 前言
Few-shot Learning顾名思义就是用很少的样本去做分类或者回归。举个简单的例子:假如现在有一个Support Set只有四张图片,前两张是犰狳(读音:qiú yú),又称“铠鼠”。后面两张是穿山甲,不用在乎太在意是否认识这两种动物,只需要区分这两种动物就行了,从现在开始观察10s,下面有一张测试图。

那么接下来进入测试环节:下面这张图是犰狳还是穿山甲呢?如果不能正常分类,那你基本就告别手表了!看过上面四张图片正常人都能做出正常判断,那么计算机是否能正确分类呢?如果每个训练集只有一两个样本,那么计算机是否能像人一样做出正确分类呢?这与主流的深度学习不同,仅仅依靠这四张样本不可能训练出一个深度神经网络,对于这种小样本问题,不能用传统的深度学习方法进行分类。这就是接下来要学习的内容few-shot learning。

few-shot learning与传统的监督学习算法不同,它的目标不是让机器识别训练集中图片并且泛化到测试集,而是让机器自己学会学习。可以理解为用一个数据集训练神经网络,学习的目的不是让神经网络知道每个类别是什么?甚至是数据集中从未出现过的图片,学习的目的是让模型理解事物的异同,学会区分不同的事物。比如下面给出两张图片,模型只需要判断这两张图片中动物是否属于同一种,就可以了。

假如训练数据中并没有下面这两种动物,穿山甲和斗牛犬。模型只需要给出一个基本的判断这两种动物不属于同一类就够了。

2. Few-Shot Learning
Few-Shot Learning是meta learning中的一种。而meta learning可以理解为learn to learn。听起来很玄乎,还是举个例子吧!

一个小朋友去海洋馆发现一只特别喜欢的动物,然而并不知道它是什么?此时假如给他一套卡片,他只需要将每张图片认真过一遍就能认出水里的动物了。 就算他之前既没有见过眼前的动物,也没见过卡片上的动物,他依旧能分辨出水里的动物,这是因为他已经具备了自主学习的能力。其实meta learning就是希望模型也能够具备这种能力,可以依靠少量的样本完成自主推理的过程。

在few-shot learning中有两个常用的术语:
- k-way:the support set has k classes.
- n-shot:every class has n examples.
那么few shot learning的主要思想就是:如何去学习一个相似度的函数。比如下面这张图,理想情况下输入x1和x2时相似度应为1,否则为0。

流程:
- 首先,在一个很大规模的数据集上学习一个相似度函数。比如Imagenet
- 然后,使用相似度函数做预测。可以对Query图片与Support Set中每一张图片进行对比,计算相似度,然后选择相似度最高的作为预测结果。
如果做meta learning的研究,想要使用标准数据集评价模型的表现,介绍两个常用的数据集:
1、Omniglot,这个数据集不大,只有几兆,很适合做研究用。一共1623个类(数据集中包含了50多张字母表,每个字母表有很多字符),而每个类只有20个样本。每个图片大小105*105。训练集:30个字母表,一共964个类别,共19280个样本。测试集:一共有20个字母表,659个类别,13180个样本。
官方下载地址:https://github.com/brendenlake/omniglot
或者使用tensorflow进行导入,有点类似于mnist数据集。
Tesorflow:https://www.tensorflow.org/datasets/catlog/omniglot
2、Mini-Imagenet,一共有100个类别,每个类别有600个样本。
3. siamese network孪生网络
3.1 learning pair-wise Similarity score
3.1.1 构建数据集
第一种方法是每次取两个样本去比较它们的相似度,训练这样的神经网络使用一个比较的大的训练数据集,数据有标注,每个类别下都有很多样本。需要使用训练集去构造正样本(positive samples)和负样本(negtive samples)。

正样本可以使得神经网络了解什么东西是同一类,负样本可以使神经网络了解事物的区别。那么如何获取正、负样本呢?首先,正样本的获取:每次从数据集中随机抽取一张图片,然后从这个类别中随机抽取另一张图片,这就是正样本,标签为1。用同样的方法可以得到每个类别的正样本。同样的方式,负样本的获取:也是随机从数据集中抽取一张图片,然后从除了这个类别的数据中抽取另外一张图片,标签为0,这就是负样本。

3.1.2 构建CNN for Feature Extraction
输入一张图片x,通过CNN提取特征输出一个特征向量f(x)。

3.1.3 训练Siamese network
在这个训练过程中两个f是一样的,通过对两张图片的特征提取得到两个特征向量,然后使用全连接层对特征向量进行处理得到一个标量,使用非线性激活函数对标量进行激活,得到的输出在0-1之间,作为两张图片的相似度度量。

模型训练完成之后,进行one-shot prediction(当然也可使是n-shot这里只是举例)6-way 1-shot prediction,训练siamese network的训练数据集中并不包括这6个类别,这就是few shot learning的难点所在。

3.2 Triplet Loss
第二种训练siamese network的方法。首先在训练样本集中随机选取一张图片作为anchor,然后从选中样本的类别中再选一张图片作为正样本(positive sample),然后在除此类别之外的类别中选取张图片作为负样本(negtive sample)。

由此得到三张图片,分别给入神经网络进行特征提取,由此进行计算损失时,应该比较小,而应该很大。
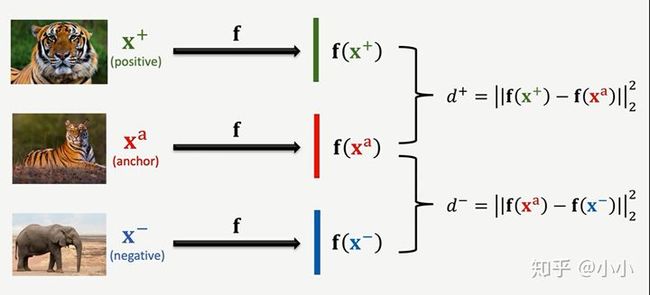
由此也可以理解为经过神经网络进行特征映射,最终映射到同一特征空间中,进行举例度量:

也即是模型鼓励损失函数中尽可能地小,尽可能地大,这样才能在特征空间中将其分开。在这个过程中定义一个阈值 ,如果
,如果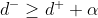 此时就没有损失,否则损失就为
此时就没有损失,否则损失就为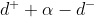 ,即是
,即是 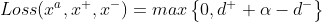 。
。
3.3 小结
总结一下训练siamese network的思路:
- 首先使用一个比较大的数据集训练siamese network。
- 然后给定一个k-way n-shot的support set,其特点在于训练集中并不包含support set中的k个类别。
- 给定一个query,去预测其类别。使用Siamese network进行计算相似度或距离。
4. Pretrain and Fine Tuning
首先介绍一些基础的数学知识:
4.1 余弦相似度Cosine Similarity
假设有两个单位向量,它们的夹角记为 ,此时余弦相似度为
,此时余弦相似度为![]() ,由此可以看出其实就是x在w方向上的投影长度,因此它的取值范围就是[-1,1]。
,由此可以看出其实就是x在w方向上的投影长度,因此它的取值范围就是[-1,1]。

那么如果两个向量不是单位向量,此时就需要对其进行归一化。此时计算余弦相似度的公式为:
![]()
4.2 softmax function
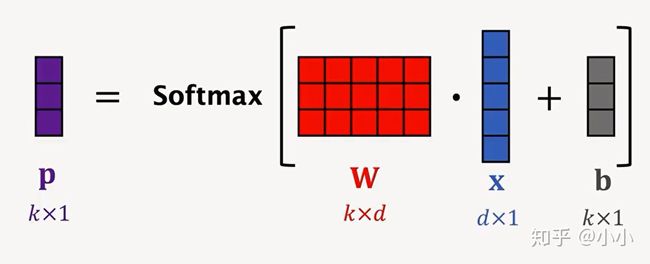
接下来重点介绍:Few-shot Prediction using pretrain CNN,使用Few-shot的分类方法。以3-way,2-shot举例:

通过神经网络输出的特征向量进行求平均和归一化得到三个类别的表征![]() ,且它们三个的范围都为单位向量。做分类的时候,使用query的特征向量q和三个表征进行计算余弦相似度。
,且它们三个的范围都为单位向量。做分类的时候,使用query的特征向量q和三个表征进行计算余弦相似度。
令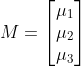 ,则有
,则有
4.3 Fine-Tuning流程:
- 将support set中每个样本记做
 其中
其中 表示图片,
表示图片,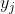 表示标签。
表示标签。 - 预训练的神经网络对support set中的样本进行特征提取,得到对应的特征向量
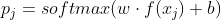 就是预测结果。通常会在support set上对w和b进行fine tuning,这样能大幅度提升准确率。
就是预测结果。通常会在support set上对w和b进行fine tuning,这样能大幅度提升准确率。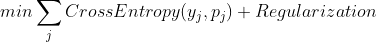
5. Tricks
5.1 A good initialization
由于Support set中数据量很小,所以选择使用随机初始化效果可能不太好。而A good initialization采用![]() ,
, ,选择这样的初始化方式最差的效果也就是不使用fine tuning。因此这种初始化方式是比较合理的。
,选择这样的初始化方式最差的效果也就是不使用fine tuning。因此这种初始化方式是比较合理的。
5.2 Entropy Regularization
由于Support set中数据量很小,因此在fine-tuning的过程中很容易过拟合,因此需要加入一些正则化的手段进行抑制。这里介绍一种Entropy Regularization:
- query sample记做x
- 使用预训练模型得到预测,记为
- 然后计算Entropy:

- Entropy Regularization就是对每个query样本求H(p),然后再求均值。
使用这种正则化方式的好处就在于:当模型预测结果较为接近时,损失函数会相对较大。

5.3 Cosine Similarity + sfotmax classifer
我是尾巴~