【深度学习框架】|TensorFlow|完成一个手写体识别任务
作者简介:大家好,我是车神哥,府学路18号的车神
⚡About—>车神:从寝室到实验室最快3分钟,最慢3分半(那半分钟其实是等红绿灯)
个人主页:车手只需要车和手,压力来自论文_府学路18号车神_CSDN博客
官方认证:人工智能领域优质创作者
点赞➕评论➕收藏 == 养成习惯(一键三连)⚡希望大家多多支持~一起加油
专栏
TensorFlow
从深度学习的简单任务开始,我们将从不同的深度学习框架来实现一个手写体识别任务,这个任务在深度学习领域可以说是和学习编程语言的第一步“Hello World”差不多。
主要的目的是为了可以直观的对比出不同深度学习框架下实现代码的差异性。我们均通过构建一个多层感知机模型来完成这个任务。
手写体识别任务
- TensorFlow
-
- ⚡TF安装
- 手写体识别任务
- 多层感知机
- TF代码
-
- ⚡*main函数
- 1. ⚡设置参数并加载数据集
- 2. ⚡定义神经网络
- 3. ⚡定义训练函数
- 4. ⚡定义预测函数
- 代码汇总
TensorFlow
首先我们先从应用的最多的框架——TensorFlow开始,简单介绍一下TensoFlow吧~
TensorFlow是一个开源软件库,用于各种感知和语言理解任务的机器学习。——Wiki百科
TensorFlow 是一个开源的机器学习的框架,我们可以使用 TensorFlow 来快速地构建神经网络,同时快捷地进行网络的训练、评估与保存。
具体就不在细说了,什么优点,缺点,网上有太多了的内容,自查即可。
⚡TF安装
安装的话借鉴了这个傻瓜式安装。
- 打开
cmd运行,首先创造tensorflow 1.15需要的环境
conda create -n tensorflow pip python=3.6
如果已经有了
Python,或者PyCharm,直接在网上搜下对应支持的版本即可,算了下面给一下吧。

- 激活
TensorFlow环境
activate tensorflow
- 用
conda安装tensorflow
CPU版输入 conda install tensorflow=1.12.0
GPU版输入 conda install tensorflow-gpu=1.12.0
(重点!)选择
conda安装而不用pip安装,是因为在安装tensorFlow-gpu版的过程中,它会自动配置对应版本号的cuda和cudnn,而不需要再单独安装
不能装gpu版的就老老实实装cpu版!!!
手写体识别任务
这里我们用到的一个开放的手写体识别数据集:MNIST数据集。
目前应用相当的广泛,在许多论文和基础教程中都应用到了。
MNIST数据集来自美国国家标准与技术研究所。
数据集由250个不同的人手写的数字构成,其中50%来自高中生,50%来自人口普查局的工作人员。具体由如下4个部分组成:
- 训练图片集(training set images):train-images-idx3-ubyte.gz (包含60,000个样本)
- 训练图片标签(training set labels):train-labels-idxl-ubyte.gz (包含60,000个标签)
- 测试图片集(test set images):t10k-images-idx3-ubyte.gz (包含10,000 个样本)
- 测试图片标签(test set labels):t10k-labels-idxl-ubyte.gz (包含10,000个标签)
样例如下图所示:

多层感知机
对于上面这样的数据集,我们构建一个三层神经网络模型,分别为输入层、隐含层、输出层。这是一个非常普通简单的神经网络模型,俗称为多层感知机(Mult-Layer Perceptron, MLP)。
整个模型如下图所示:

该神经网络包含三层,第一层(输入层)有784个神经元(每张手写体识别图像素均为28像素*28像素的图像),第二层(隐藏层)有200个神经元,最终层(输出层)有10个神经元(有数字0~9共有10个类别)。我们使用Sigmoid函数作为激活函数,将均方误差作为损失函数,使用Adam优化器,Learning Rate=0.01.
TF代码
所有框架下的步骤均一致:
- 设置参数并加载数据集(大多数框架都有架子标准数据集的方法,如MNIST)
- 创建多层感知机(MLP)神经网络
- 定义训练函数,包括模型训练和模型存储
- 定义预测函数,包括模型导入和测试数据预测
- 创建main函数,让用户使用训练数据集进行训练,然后使用测试数据集进行测试
本案例用到的是:TensorFlow==1.12.0
在下列代码中,将其整理为相同的格式以便比较,每份代码包含五部分:
- 设置参数并加载数据集
- 定义神经网络
- 定义训练函数
- 定义预测函数和
main函数
⚡*main函数
其中的main函数不变:
import argparse
if __name__=="__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--action", type=str, default="predict")
FLAGS, unparsed = parser.parse_known_args()
if FLAGS.action == "train":
train()
if FLAGS.action == "predict":
predict()
运行代码的方法:
1. 训练:python MNIST.py --action train
2. 预测:python MNIST.py -- action predict
1. ⚡设置参数并加载数据集
import tensorflow as tf
import argparse
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data
# 基本参数
inputs, hiddens, outputs = 784, 200, 10
learning_rate = 0.01
epochs = 50
batch_size = 64
# 导入数据集
mnist = input_data.read_data_sets("./mnist/", one_hot=True)
x = tf.placeholder(tf.float32, [None, inputs]) # tf.placeholder: 此函数可以理解为形参,用于定义过程,在执行的时候再赋具体的值.默认是None,就是一维值,也可以是多维,比如[2,3], [None, 3]表示列是3.
y = tf.placeholder(tf.float32, [None, outputs])
这里需要多次运行才能下载mnist数据集,好像由于版本过于久远,哎。TensorFlow啊~

运行完就下载下来了

在此,我们定义了基本参数,有输入层维度(inputs)、隐含层维度(hiddens)、输出层维度(outputs)、学习率(learning_rate)、迭代次数(epochs)、数据块大小(batch_size)。同时,将数据输出设置为one_hot编码。
2. ⚡定义神经网络
# 神经网络结构——(Multi-layer Perception,MLP)多层感知机
def mlp(x, hidden_weights, output_weights):
hidden_outputs = tf.nn.sigmoid(tf.matmul(x, hidden_weights))
final_outputs = tf.nn.sigmoid(tf.matmul(hidden_outputs, output_weights))
return final_outputs
- tf.nn.sigmoid:应用sigmoid函数可以将输出压缩至0~1的范围
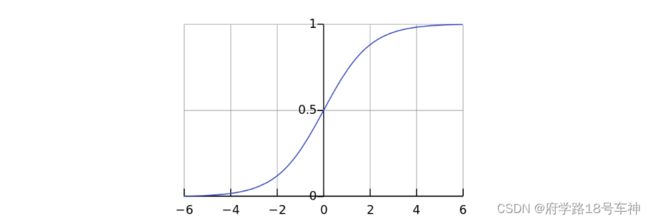
tf.matmul:将矩阵a乘以矩阵b,生成a * b
输入必须是矩阵(或者是张量秩 >2的张量,表示成批的矩阵),并且其在转置之后有相匹配的矩阵尺寸
定义了一个简单的多层感知机,激活函数设置为sigmoid。
3. ⚡定义训练函数
# 训练
def train():
# 初始化权重,定义损失函数和优化器
hidden_weights = tf.Variable(tf.random_normal([inputs, hiddens]), name="hidden_weights")
output_weights = tf.Variable(tf.random_normal([hiddens, outputs]), name="output_weights")
final_outputs = mlp(x, hidden_weights, output_weights)
errors = tf.reduce_mean(tf.squared_difference(final_outputs, y))
# 定义优化器
optimiser = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(errors)
# 定义会话(session),开始训练
init_op = tf.global_variables_initializer() # 初始化全局所有变量
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(init_op)
total_batch = int(len(mnist.train.labels) / batch_size)
for epoch in range(epochs):
avg_error = 0
for i in range(total_batch):
batch_x, batch_y = mnist.train.next_batch(batch_size=batch_size)
_, c = sess.run([optimiser, errors], feed_dict={x: batch_x, y: batch_y})
avg_error += c / total_batch
print("Epoch [%d/%d], error: %.4f" % (epoch+1, epochs, avg_error))
print("\nTraining complete!")
saver.save(sess, "./model")
tf.Variable
tf.Variable.init(initial_value, trainable=True, collections=None, validate_shape=True, name=None)

tf.random_normal
tf.random_normal(shape, mean=0.0, stddev=1.0, dtype=tf.float32, seed=None, name=None)
用于从“服从指定正态分布的序列”中随机取出指定个数的值。

tf.reduce_mean
reduce_mean(input_tensor,
axis=None,
keep_dims=False,
name=None,
reduction_indices=None)
- 第一个参数
input_tensor: 输入的待降维的tensor; - 第二个参数
axis: 指定的轴,如果不指定,则计算所有元素的均值; - 第三个参数
keep_dims:是否降维度,设置为True,输出的结果保持输入tensor的形状,设置为False,输出结果会降低维度; - 第四个参数
name: 操作的名称; - 第五个参数
reduction_indices:在以前版本中用来指定轴,已弃用;
函数用于计算张量tensor沿着指定的数轴(tensor的某一维度)上的的平均值,主要用作降维或者计算tensor(图像)的平均值。
tf.squared_difference
squared_difference(
x,
y,
name=None
)
返回一个 Tensor,它与 x 具有相同的类型。计算张量 x、y 对应元素差的平方——标准差
tf.train.AdamOptimizer
AdamOptimizer是TensorFlow中实现Adam算法的优化器。Adam即Adaptive Moment Estimation(自适应矩估计),是一个寻找全局最优点的优化算法,引入了二次梯度校正。Adam 算法相对于其它种类算法有一定的优越性,是比较常用的算法之一。

tf.Session()
- Session 是 Tensorflow 为了控制,和输出文件的执行的语句. 运行 session.run() 可以获得你要得知的运算结果, 或者是你所要运算的部分.(很实用!!!)
- 有点类似于
js里面的console.log()。
tf.train.Saver()保存和加载模型
saver = tf.train.Saver()
saver.save(sess, '路径 + 模型文件名')
在创建这个 Saver 对象的时候, max_to_keep 参数表示要保留的最近检查点文件的最大数量,创建新文件时,将删除旧文件,默认为 5(即保留最近的 5 个检查点文件),max_to_keep=5。
4. ⚡定义预测函数
# 预测
def predict():
saver = tf.train.import_meta_graph('.model.meta')
with tf.Session() as sess:
saver.restore(sess, tf.train.latest_checkpoint('./'))
graph = tf.get_default_graph()
hidden_weights = graph.get_tensor_by_name('hidden_weights:0')
output_weights = graph.get_tensor_by_name('output_weights:0')
final_outputs = mlp(x, hidden_weights, output_weights)
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(final_outputs, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
tf.summary.scalar('accuracy', accuracy)
print(sess.run(accuracy, feed_dict={x: mnist.test.images, y: mnist.test.labels}))
现在已经在TensorFlow框架下搭建完了整个网络结构,下面我们调用一下预测的程序,上面给出了允许代码的方法,直接在终端运行即可。
再来一遍吧:
1. 训练:python MNIST.py --action train
2. 预测:python MNIST.py -- action predict
我是在PyCharm里面运行的,这就直接在下面终端训练和预测了。注意需要在当前文件夹下面✅运行哦~
训练迭代的误差结果:
Epoch [1/50], error: 0.0734
Epoch [2/50], error: 0.0429
Epoch [3/50], error: 0.0347
Epoch [4/50], error: 0.0337
Epoch [5/50], error: 0.0331
Epoch [6/50], error: 0.0327
Epoch [7/50], error: 0.0325
Epoch [8/50], error: 0.0323
Epoch [9/50], error: 0.0321
Epoch [10/50], error: 0.0319
Epoch [11/50], error: 0.0310
Epoch [12/50], error: 0.0235
Epoch [13/50], error: 0.0227
Epoch [14/50], error: 0.0223
Epoch [15/50], error: 0.0221
Epoch [16/50], error: 0.0219
Epoch [17/50], error: 0.0218
Epoch [18/50], error: 0.0217
Epoch [19/50], error: 0.0216
Epoch [20/50], error: 0.0215
Epoch [21/50], error: 0.0213
Epoch [22/50], error: 0.0140
Epoch [23/50], error: 0.0132
Epoch [24/50], error: 0.0129
Epoch [25/50], error: 0.0127
Epoch [26/50], error: 0.0127
Epoch [27/50], error: 0.0126
Epoch [28/50], error: 0.0125
Epoch [29/50], error: 0.0124
Epoch [30/50], error: 0.0123
Epoch [31/50], error: 0.0121
Epoch [32/50], error: 0.0121
Epoch [33/50], error: 0.0121
Epoch [34/50], error: 0.0121
Epoch [35/50], error: 0.0121
Epoch [36/50], error: 0.0119
Epoch [37/50], error: 0.0119
Epoch [38/50], error: 0.0119
Epoch [39/50], error: 0.0120
Epoch [40/50], error: 0.0117
Epoch [41/50], error: 0.0118
Epoch [42/50], error: 0.0118
Epoch [43/50], error: 0.0118
Epoch [44/50], error: 0.0119
Epoch [45/50], error: 0.0117
Epoch [46/50], error: 0.0117
Epoch [47/50], error: 0.0115
Epoch [48/50], error: 0.0116
Epoch [49/50], error: 0.0114
Epoch [50/50], error: 0.0116
Training complete!
在来看看预测准确率结果如何:
0.8772
在训练的时候,TF代码在训练集的误差随着迭代次数的增加(Epochs)的变化而变化,从结果可以看出,训练误差从第一轮迭代结束维7.34%下降到了3.10%,误差处于一种稳定,最终到1.16%则稳定了。
预测的准确率维87.72%,虽然不是很高,但是就单层网络而言还是足以。
在上述的代码中我们可以直观感受到
TensorFlow的符号式编程,其变量先定义成符号,如由tf.placeholder定义的x,y为输入符号;mlp函数定义的hidden_outputs、final_outputs为运算符号等.我们知道,在
TensorFlow的所有计算过程都必须在会话(Session)里启动,因此我们能看到在训练和测试开始之前,都包含with tf.Session() as sess:这个语句。
在执行的过程中,会话中的x,y会用实际的数据代入;会话会将计算图的执行分发到诸如CPU或GPU之类的设备上,同时提供执行计算图操作的方法。当这些方法被执行之后,将产生的张量(Tensor)返回。TensorFLow队计算图进行优化时也都对Debug有一些困扰。
如:在使用
tf.Print()对一个TensorFlow项目进行Debug时,一直无法输出,最好才发现是因为该数据节点不在最后输出值的执行路径上,被TensorFlow的计算图优化了,并未执行。
代码汇总
# -- coding: utf-8 --
# @Time : 2022/5/14 15:33
# @Author : 府学路18号车神
# @File : MNIST.py
# @Software: PyCharm
import tensorflow as tf
import argparse
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data
# 基本参数
inputs, hiddens, outputs = 784, 200, 10
learning_rate = 0.01
epochs = 50
batch_size = 64
# 导入数据集
mnist = input_data.read_data_sets("./mnist/", one_hot=True)
x = tf.placeholder(tf.float32, [None, inputs]) # tf.placeholder: 此函数可以理解为形参,用于定义过程,在执行的时候再赋具体的值.默认是None,就是一维值,也可以是多维,比如[2,3], [None, 3]表示列是3.
y = tf.placeholder(tf.float32, [None, outputs])
# 神经网络结构——(Multi-layer Perception,MLP)多层感知机
def mlp(x, hidden_weights, output_weights):
hidden_outputs = tf.nn.sigmoid(tf.matmul(x, hidden_weights))
final_outputs = tf.nn.sigmoid(tf.matmul(hidden_outputs, output_weights))
return final_outputs
# 训练
def train():
# 初始化权重,定义损失函数和优化器
hidden_weights = tf.Variable(tf.random_normal([inputs, hiddens]), name="hidden_weights")
output_weights = tf.Variable(tf.random_normal([hiddens, outputs]), name="output_weights")
final_outputs = mlp(x, hidden_weights, output_weights)
errors = tf.reduce_mean(tf.squared_difference(final_outputs, y))
# 定义优化器
optimiser = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(errors)
# 定义会话(session),开始训练
init_op = tf.global_variables_initializer() # 初始化全局所有变量
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(init_op)
total_batch = int(len(mnist.train.labels) / batch_size)
for epoch in range(epochs):
avg_error = 0
for i in range(total_batch):
batch_x, batch_y = mnist.train.next_batch(batch_size=batch_size)
_, c = sess.run([optimiser, errors], feed_dict={x: batch_x, y: batch_y})
avg_error += c / total_batch
print("Epoch [%d/%d], error: %.4f" % (epoch + 1, epochs, avg_error))
print("\nTraining complete!")
saver.save(sess, "./model")
# 预测
def predict():
# yuce
saver = tf.train.import_meta_graph('./model.meta')
with tf.Session() as sess:
saver.restore(sess, tf.train.latest_checkpoint('./'))
graph = tf.get_default_graph()
hidden_weights = graph.get_tensor_by_name('hidden_weights:0')
output_weights = graph.get_tensor_by_name('output_weights:0')
final_outputs = mlp(x, hidden_weights, output_weights)
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(final_outputs, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
tf.summary.scalar('accuracy', accuracy)
print(sess.run(accuracy, feed_dict={x: mnist.test.images, y: mnist.test.labels}))
# main
if __name__=="__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--action", type=str, default="predict")
FLAGS, unparsed = parser.parse_known_args()
if FLAGS.action == "train":
train()
if FLAGS.action == "predict":
predict()
好了,第一个框架下实现手写体识别的任务就到这了,下次在换Keras框架来实现一下,下期再见哦~
❤坚持读Paper,坚持做笔记,坚持学习,坚持刷力扣LeetCode❤!!!
坚持刷题!!!
⚡To Be No.1⚡⚡哈哈哈哈
⚡创作不易⚡,过路能❤关注、收藏、点个赞❤三连就最好不过了
ღ( ´・ᴗ・` )
❤