从零开始的数模(十四)因子分析
目录
一、概念
1.1概念
1.2基本形式·
1.3基本流程
1.4对比
1.5 因子分析的实例:
1.6原理及性质
1.7两种检验:
编辑编辑 二、基于Matlab的因子分析
3.2 factoran()法
三、基于python的因子分析
3.1步骤分析
3.2代码
4.3 可视化中显示中文不报错
一、概念
1.1概念
因子分析通过研究变量间的相关系数矩阵,把这些变量间错综复杂的关系归结成少数几个综合因子,由于归接触的因子个数少于原始变量的个数,但是他们又包含原始变量的信息,所以,这一分析过程也成为降维。
正常情况下,可以用主成分分析的模型都可以用因子分析来做。所以因子分析的应用城的更广。
1.2基本形式·
分解1

1.3基本流程

1.4对比

1.5 因子分析的实例:

将原来的是个指标变成了四个因子,实现了降维。
1.6原理及性质
因子分析的原理

因子模型的性质:
 因子载荷矩阵的统计意义
因子载荷矩阵的统计意义

因子旋转(当得到的A不容易解释的时候)
已知,A不只有一个,所以我们遇到不容易解释的模型的时候,可以将因子旋转后再进行解释。

 因子得分
因子得分

1.7两种检验:

 二、基于Matlab的因子分析
二、基于Matlab的因子分析
例题
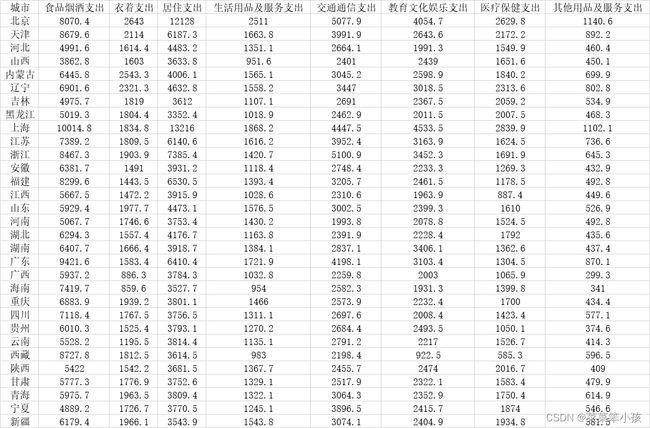 1.读取数据
1.读取数据
[data,textdata] = xlsread('D:\桌面\aa.xls')%读取数据
让我们来看一下,读取的 data 和 textdata
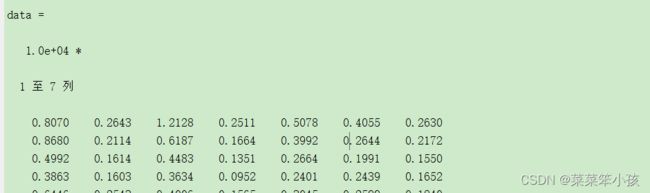
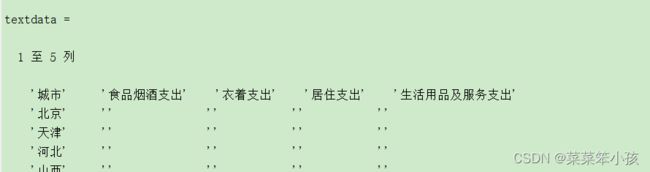 然后我们在读取一下变量名
然后我们在读取一下变量名
varname = textdata(1,2:end)%提取textdata的第1行,第2至最后一列,即变量名
最后我们再看一下它的每行的首项,
obsname = textdata(2:end,1)%提取textdata的第1列,第2行至最后一行,即地区名
2.数据标准化

data=zscore(data) %数据标准化 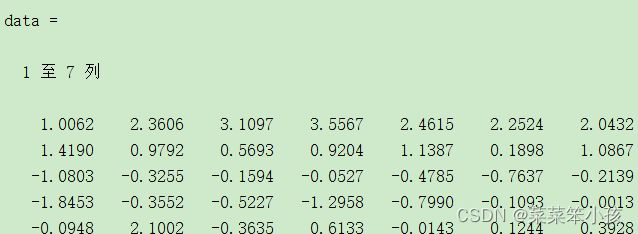
3.两种不同的做法
3.1 不用函数
3.1.1 求相关系数矩阵
r=corrcoef(data) %相关系数矩阵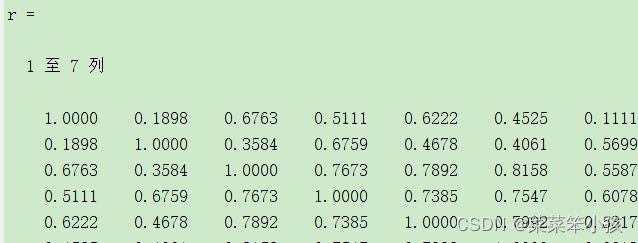
3.1.2 带入主成分分析进行计算
%进行主成分分析的相关计算
%vec是r的特征向量,val为r的特征值,con为各个主成分的贡献率
[vec,val,con]=pcacov(r); %进行主成分分析的相关计算3.1.3 求载荷矩阵
f1=repmat(sign(sum(vec)),size(vec,1),1);
vec=vec.*f1; %特征向量正负号转换
f2=repmat(sqrt(val)',size(vec,1),1);
a=vec.*f2 %求初等载荷矩阵 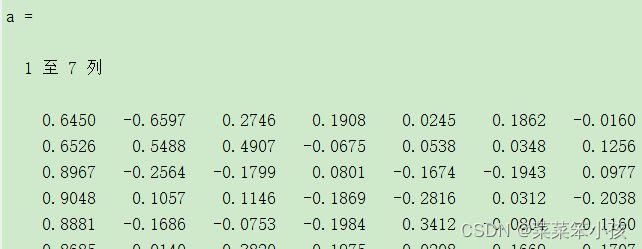
3.1.4 因子旋转(最大方差法)
num=input('请选择主因子的个数:'); %选择主因子的个数
%其中b为旋转后的载荷矩阵,t为变换的正交矩阵
[b,t]=rotatefactors(a(:,1:num),'method', 'varimax'); %对载荷矩阵进行旋转
bz=[b,a(:,num+1:end)] %旋转后的载荷矩阵 
3.1.5 贡献率
gx=sum(bz.^2); %计算因子贡献
gxv=gx/sum(gx); %计算因子贡献率3.1.6 因子得分
dfxsh=inv(r)*b; %计算得分函数的系数
F=data*dfxsh ;%计算各个因子的得分3.2 factoran()法
这个函数具有一定的 bug 所以不太建议使用!!!
3.2.1因子旋转
%调用factoran函数根据原始观测数据作因子分析4
% 进行因子旋转(最大方差旋转法)
%在这里选择2个主因子进行输出
num=input('请选择主因子的个数:'); %选择主因子的个数
[lambda,psi,T,stats,F] = factoran(data,num)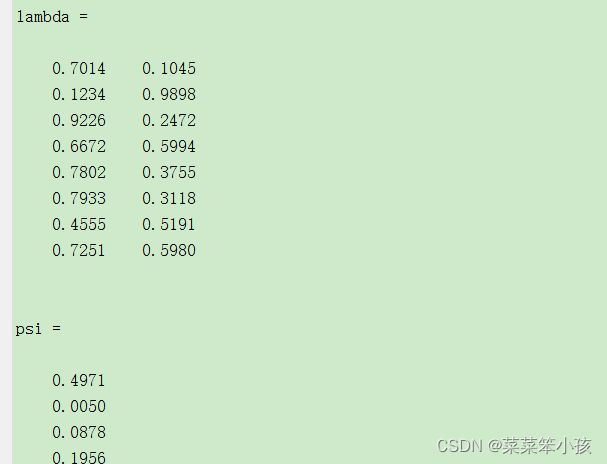
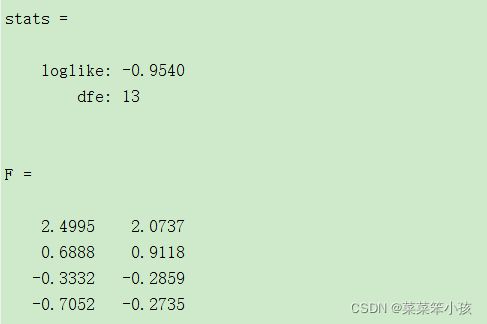
3.2.2 贡献率
%计算贡献率,因子载荷矩阵的列元素的平方和除以维数
gx = 100*sum(lambda.^2)/8
gxv = cumsum(Contribut) %计算累积贡献率3.2.3 因子得分
在上面 factoran() 函数的输出结果中就已经有了
4.对因子得分进行排序
%将因子得分F分别按因子得分1和因子得分2进行排序
obsF = [obsname, num2cell(F)] ;%将国家和地区名与因子得分刚在一个元胞数组中显示
F1 = sortrows(obsF, 2) ; % 按因子得分1排序
F2 = sortrows(obsF, 3); % 按因子得分2排序
head = {'地区','因子1','因子2'};
result1 = [head; F1]
result2 = [head; F2]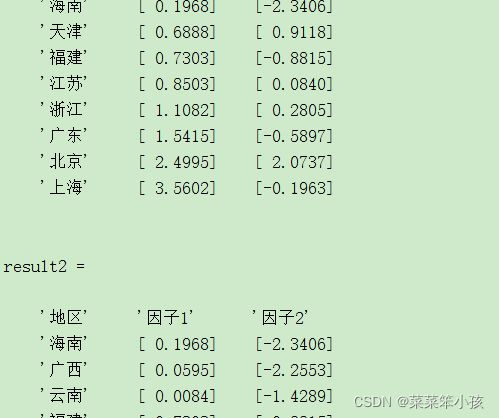
5.对因子得分进行画图
在这里就表示一个的哦!!表示函数法那个吧,另一种自己试试吧,结果不太一样!!!
gname() 函数 ,你鼠标选中哪个点,进行击右键就会显示地区名
%绘制因子得分负值的散点图
plot(F(:,1),F(:,2),'k.');%作因子
xlabel('因子得分1');
ylabel('因子得分2');
gname(obsname);%交互式添加各散点的标注
三、基于python的因子分析
3.1步骤分析

3.2代码
1.导入库
# 数据处理
import pandas as pd
import numpy as np
# 绘图
import seaborn as sns
import matplotlib.pyplot as plt
# 因子分析
from factor_analyzer import FactorAnalyzer2.读取数据
df = pd.read_csv("D:\桌面\demo.csv",encoding='gbk')
df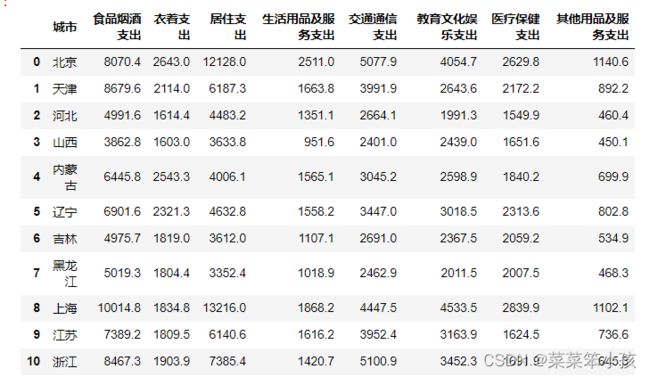
如果不想要城市那一列的话,可以在读取的时候就删除,也可以后面再删
比如,读取时删除
df = pd.read_csv("D:\桌面\demo.csv", index_col=0,encoding='gbk').reset_index(drop=True)
df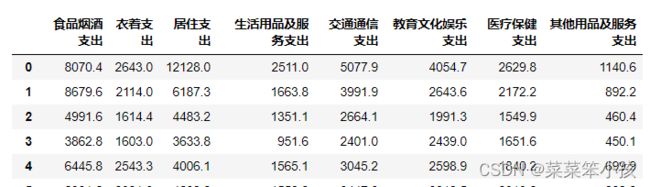
然后我们查询一下,数据的缺失值情况:
df.isnull().sum()
然后,我们可以针对的,对数据进行一次处理:
比如删除无效字段的那一列
# 去掉无效字段
df.drop(["变量名1","变量名2","变量名3"],axis=1,inplace=True)或者,删除空值
# 去掉空值
df.dropna(inplace=True)3.充分性检测
在进行因子分析之前,需要先进行充分性检测,主要是检验相关特征阵中各个变量间的相关性,是否为单位矩阵,也就是检验各个变量是否各自独立。
3.1 Bartlett's球状检验
检验总体变量的相关矩阵是否是单位阵(相关系数矩阵对角线的所有元素均为1,所有非对角线上的元素均为零);即检验各个变量是否各自独立。
如果不是单位矩阵,说明原变量之间存在相关性,可以进行因子分子;反之,原变量之间不存在相关性,数据不适合进行主成分分析
from factor_analyzer.factor_analyzer import calculate_bartlett_sphericity
chi_square_value, p_value = calculate_bartlett_sphericity(df)
chi_square_value, p_value
3.2 KMO检验
检查变量间的相关性和偏相关性,取值在0-1之间;KOM统计量越接近1,变量间的相关性越强,偏相关性越弱,因子分析的效果越好。
通常取值从0.6开始进行因子分析
#KMO检验
from factor_analyzer.factor_analyzer import calculate_kmo
kmo_all,kmo_model=calculate_kmo(df)
kmo_model 
通过结果可以看到KMO大于0.6,也说明变量之间存在相关性,可以进行分析。
4.选择因子个数
方法:计算相关矩阵的特征值,进行降序排列
4.1 特征值和特征向量
faa = FactorAnalyzer(25,rotation=None)
faa.fit(df)
# 得到特征值ev、特征向量v
ev,v=faa.get_eigenvalues()
print(ev,v)
4.2 可视化展示
将特征值和因子个数的变化绘制成图形:
# 同样的数据绘制散点图和折线图
plt.scatter(range(1, df.shape[1] + 1), ev)
plt.plot(range(1, df.shape[1] + 1), ev)
# 显示图的标题和xy轴的名字
# 最好使用英文,中文可能乱码
plt.title("Scree Plot")
plt.xlabel("Factors")
plt.ylabel("Eigenvalue")
plt.grid() # 显示网格
plt.show() # 显示图形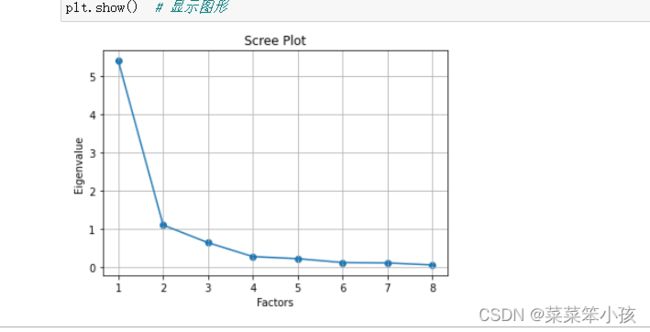
从上面的图形中,我们明确地看到:选择2或3个因子就可以了
4.3 可视化中显示中文不报错
只需要在画图前,再导入一个库即可,见代码
import matplotlib as mpl
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题5.因子旋转
5.1 建立因子分析模型
在这里选择,最大方差化因子旋转
# 选择方式: varimax 方差最大化
# 选择固定因子为 2 个
faa_two = FactorAnalyzer(2,rotation='varimax')
faa_two.fit(df)
ratation参数的其他取值情况:
varimax (orthogonal rotation)
promax (oblique rotation)
oblimin (oblique rotation)
oblimax (orthogonal rotation)
quartimin (oblique rotation)
quartimax (orthogonal rotation)
equamax (orthogonal rotation)
5.2 查看因子方差-get_communalities(
查看公因子方差
# 公因子方差
faa_two.get_communalities()
查看每个变量的公因子方差数据
pd.DataFrame(faa_two.get_communalities(),index=df.columns) 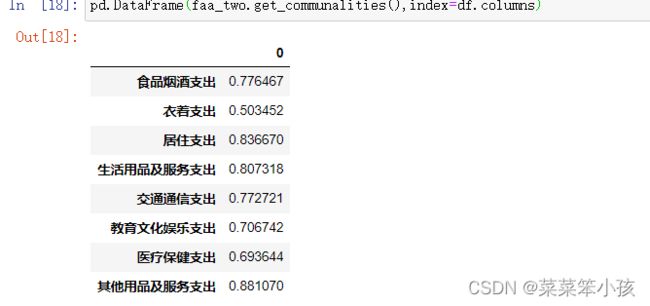
5.3 查看旋转后的特征值
faa_two.get_eigenvalues()
pd.DataFrame(faa_two.get_eigenvalues())
5.4 查看成分矩阵
查看它们构成的成分矩阵
# 变量个数*因子个数
faa_two.loadings_
如果转成DataFrame格式,index就是我们的变量,columns就是指定的因子factor。转DataFrame格式后的数据:
pd.DataFrame(faa_two.loadings_,index=df.columns) 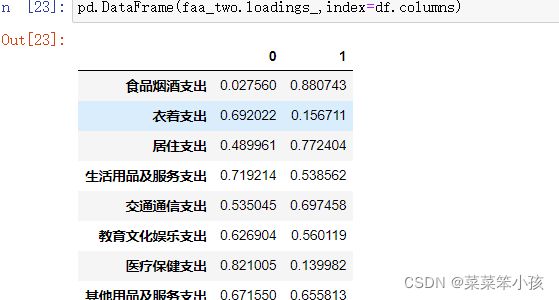
5.5 查看因子贡献率

faa_two.get_factor_variance() 
6.隐藏变量可视化
为了更直观地观察每个隐藏变量和哪些特征的关系比较大,进行可视化展示,为了方便取上面相关系数的绝对值
df1 = pd.DataFrame(np.abs(faa_two.loadings_),index=df.columns)
print(df1)
然后我们通过热力图将系数矩阵绘制出来:
# 绘图
plt.figure(figsize = (14,14))
ax = sns.heatmap(df1, annot=True, cmap="BuPu")
# 设置y轴字体大小
ax.yaxis.set_tick_params(labelsize=15)
plt.title("Factor Analysis", fontsize="xx-large")
# 设置y轴标签
plt.ylabel("Sepal Width", fontsize="xx-large")
# 显示图片
plt.show()
# 保存图片
# plt.savefig("factorAnalysis", dpi=500)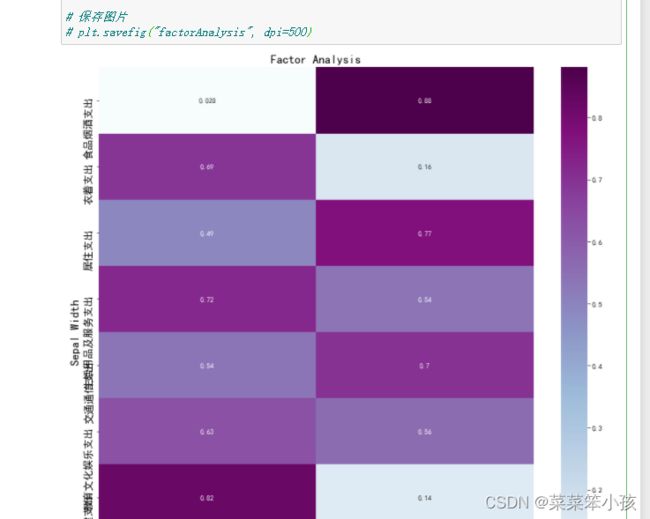
7.转成新变量
上面我们已经知道了2个因子比较合适,可以将原始数据转成2个新的特征,具体转换方式为:
faa_two.transform(df)
转成DataFrame格式后数据展示效果更好:
df2 = pd.DataFrame(faa_two.transform(df))
print(df2)