从零开始的数模(十八)熵权法
目录
一、概念
二、基于python的熵权法
2.1步骤
mapminmax介绍
2.2例题
整体代码
三、基于MATLAB的熵权法
3.1例题
2.2 某点最优型指标处理
整体代码
一、概念
1.1相关概念
熵权法是一种客观赋值方法。在具体使用的过程中,熵权法根据各指标的变异程度,利用信息熵计算出各指标的熵权,再通过熵权对各指标的权重进行修正,从而得到较为客观的指标权重。
一般来说,若某个指标的信息熵指标权重确定方法之熵权法越小,表明指标值得变异程度越大,提供的信息量越多,在综合评价中所能起到的作用也越大,其权重也就越大。
相反,若某个指标的信息熵指标权重确定方法之熵权法越大,表明指标值得变异程度越小,提供的信息量也越少,在综合评价中所起到的作用也越小,其权重也就越小。
1.2基本形式

二、基于python的熵权法
2.1步骤
1.指标正向化
这个步骤视情况自己决定把。。。。
不同的指标代表含义不一样,有的指标越大越好,称为越大越优型指标。有的指标越小越好,称为越小越优型指标,而有些指标在某个点是最好的,称为某点最优型指标。为方便评价,应把所有指标转化成越大越优型指标。
设有m个待评对象,n个评价指标,可以构成数据矩阵 
mapminmax介绍
语法
[Y,PS] = mapminmax(X,YMIN,YMAX)
[Y,PS] = mapminmax(X,FP)
Y = mapminmax('apply',X,PS)
X = mapminmax('reverse',Y,PS)说明:
[Y,PS] = mapminmax(X,YMIN,YMAX) mapminmax(X,YMIN,YMAX) 将矩阵的每一行压缩到 [YMIN,YMAX],其中当前行的最大值变为YMAX,最小值变为YMIN。PS为结构体储存相关信息,如最大最小值等
[Y,PS] = mapminmax(X,FP) 其中FP为结构体类型,这时就是将矩阵的每一行压缩到[ FP.ymin, FP.ymax]中
Y = mapminmax('apply',X,PS) 可以将之前储存的结构体应用到新的矩阵中,利用上一步得到的PS来映射X到Y
X = mapminmax('reverse',Y,PS) 可按照之前数据规律,反归一化,利用归一化后的Y和PS重新得到X
2.数据标准化

3.计算信息熵

4.计算权重以及得分

2.2例题
用一篇高引用的核心期刊论文[1]为例,针对各个银行的资产收益率,费用利润率,逾期贷款率,非生息资产率,流动性比率,资产使用率,自有资本率指标进行评价。设资产收益率为A,费用利润率为B,逾期贷款率为C,非生息资产率为D,流动性比率为E,资产使用率为F,自有资本率为G。数据表格如下:
1.导入相关库
#导入相关库
import copy
import pandas as pd
import numpy as np2.读取数据
#读取数据
data=pd.read_excel('D:\桌面\shangquan.xlsx')
print(data)
首先,我们先提取一下变量名
label_need=data.keys()[2:]
print(label_need)

然后,我们提取变量名下的数据值
data1=data[label_need].values
print(data1)
2.指标正向化
#指标正向 化处理后数据为data2
data2=data1
print(data2)2.1 越小越优型处理
#越小越优指标位置,注意python是从0开始计数,对应位置也要相应减1
index=[2,3]
for i in range(0,len(index)):
data2[:,index[i]]=max(data1[:,index[i]])-data1[:,index[i]]
print(data2)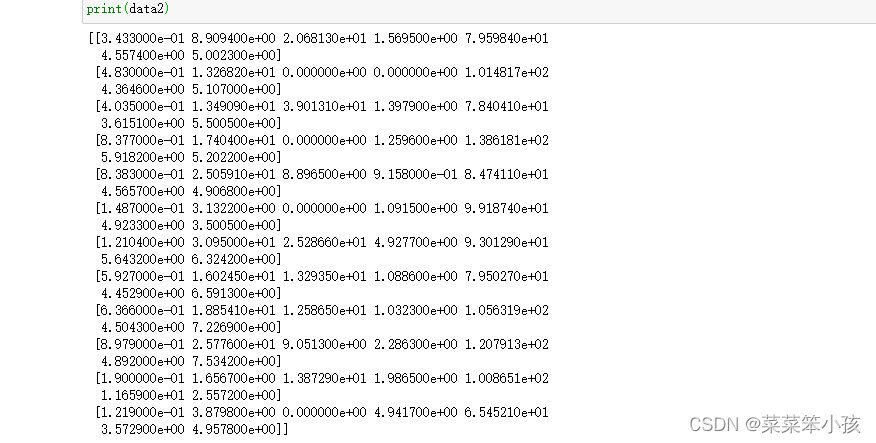
2.2 某点最优型指标处理
#某点最优型指标
index1=[4]
a=90 #最优型数值
for i in range(0,len(index1)):
data2[:,index1[i]]=1-abs(data1[:,index1[i]]-a)/max(abs(data1[:,index1[i]]-a))
print(data2)3.数据标准化
#0.002~1区间归一化
[m,n]=data2.shape
data3=copy.deepcopy(data2)
ymin=0.002
ymax=1
for j in range(0,n):
d_max=max(data2[:,j])
d_min=min(data2[:,j])
data3[:,j]=(ymax-ymin)*(data2[:,j]-d_min)/(d_max-d_min)+ymin
print(data3)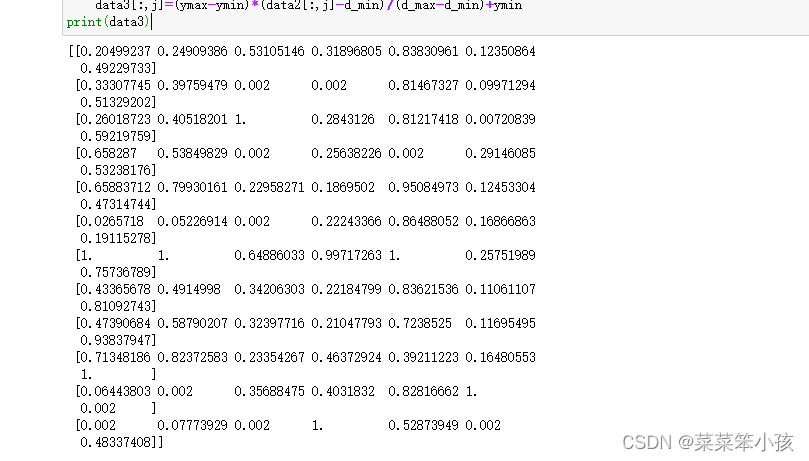
4.计算信息熵
#计算信息熵
p=copy.deepcopy(data3)
for j in range(0,n):
p[:,j]=data3[:,j]/sum(data3[:,j])
print(p)
E=copy.deepcopy(data3[0,:])
for j in range(0,n):
E[j]=-1/np.log(m)*sum(p[:,j]*np.log(p[:,j]))
print(E)
5.计算权重
# 计算权重
w=(1-E)/sum(1-E)
print(w)
6.计算得分
#计算得分
s=np.dot(data3,w)
Score=100*s/max(s)
for i in range(0,len(Score)):
print(f"第{i}个评价对象得分为:{Score[i]}")整体代码
#导入相关库
import copy
import pandas as pd
import numpy as np
#读取数据
data=pd.read_excel('D:\桌面\shangquan.xlsx')
print(data)
label_need=data.keys()[2:]
print(label_need)
data1=data[label_need].values
print(data1)
#指标正向 化处理后数据为data2
data2=data1
print(data2)
#越小越优指标位置,注意python是从0开始计数,对应位置也要相应减1
index=[2,3]
for i in range(0,len(index)):
data2[:,index[i]]=max(data1[:,index[i]])-data1[:,index[i]]
print(data2)
#某点最优型指标
index1=[4]
a=90 #最优型数值
for i in range(0,len(index1)):
data2[:,index1[i]]=1-abs(data1[:,index1[i]]-a)/max(abs(data1[:,index1[i]]-a))
print(data2)
#0.002~1区间归一化
[m,n]=data2.shape
data3=copy.deepcopy(data2)
ymin=0.002
ymax=1
for j in range(0,n):
d_max=max(data2[:,j])
d_min=min(data2[:,j])
data3[:,j]=(ymax-ymin)*(data2[:,j]-d_min)/(d_max-d_min)+ymin
print(data3)
#计算信息熵
p=copy.deepcopy(data3)
for j in range(0,n):
p[:,j]=data3[:,j]/sum(data3[:,j])
print(p)
E=copy.deepcopy(data3[0,:])
for j in range(0,n):
E[j]=-1/np.log(m)*sum(p[:,j]*np.log(p[:,j]))
print(E)
# 计算权重
w=(1-E)/sum(1-E)
print(w)
#计算得分
s=np.dot(data3,w)
Score=100*s/max(s)
for i in range(0,len(Score)):
print(f"第{i}个评价对象得分为:{Score[i]}")三、基于MATLAB的熵权法
3.1例题
1.读取数据
%读取数据
data=xlsread('D:\桌面\shangquan.xlsx')
在这里,我们可以看到读取的数据中,有部分是我们不想要的,于是我们得做处理
在这里,我们可以看到读取的数据中,有部分是我们不想要的,于是我们得做处理2.指标正向化
%指标正向 化处理后数据为data1
data1=data;2.1 越小越优型处理
%%越小越优型处理
index=[3,4];%越小越优指标位置
for i=1:length(index)
data1(:,index(i))=max(data(:,index(i)))-data(:,index(i))
end
2.2 某点最优型指标处理
%%某点最优型指标处理
index=[5];
a=90;%最优型数值
for i=1:length(index)
data1(:,index(i))=1-abs(data(:,index(i))-a)/max(abs(data(:,index(i))-a))
end
3.数据标准化
data2=mapminmax(data1',0.002,1) %标准化到0.002-1区间
由于是mapminmax对行进行标准化,所以需要转置一下
data2=data2' 
4.计算信息熵
%得到信息熵
[m,n]=size(data2);
p=zeros(m,n);
for j=1:n
p(:,j)=data2(:,j)/sum(data2(:,j))
end
for j=1:n
E(j)=-1/log(m)*sum(p(:,j).*log(p(:,j)))
end 
5.计算权重
%计算权重
w=(1-E)/sum(1-E) 
6.计算得分
%计算得分
s=data2*w';
Score=100*s/max(s);
disp('12个银行分别得分为:')
disp(Score)
整体代码
clc;clear;
%读取数据
data=xlsread('D:\桌面\shangquan.xlsx');
data=data(:,3:end); %只取指标数据
%指标正向 化处理后数据为data1
data1=data;
%%越小越优型处理
index=[3,4];%越小越优指标位置
for i=1:length(index)
data1(:,index(i))=max(data(:,index(i)))-data(:,index(i));
end
%%某点最优型指标处理
index=[5];
a=90;%最优型数值
for i=1:length(index)
data1(:,index(i))=1-abs(data(:,index(i))-a)/max(abs(data(:,index(i))-a));
end
%数据标准化 mapminmax对行进行标准化,所以转置一下
data2=mapminmax(data1',0.002,1); %标准化到0.002-1区间
data2=data2';
%得到信息熵
[m,n]=size(data2);
p=zeros(m,n);
for j=1:n
p(:,j)=data2(:,j)/sum(data2(:,j));
end
for j=1:n
E(j)=-1/log(m)*sum(p(:,j).*log(p(:,j)));
end
%计算权重
w=(1-E)/sum(1-E);
%计算得分
s=data2*w';
Score=100*s/max(s);
disp('12个银行分别得分为:')
disp(Score)