python Dataframe iloc时一直报out-of-bounds 和 根据行索引取Dataframe的多行值
今天在用pandas时候遇到了Dataframe的iloc一直报out-of-bounds这个错,这个简单理解就是越界了。
1.普通情况
举个简单的例子:
import pandas as pd
dataset=[[1,2.222,3,4,5],[2,None,None,None,5],[None,None,3,4,None],[1,2.5661,3,4,5.234]]
df=pd.DataFrame(dataset)
# 删除df中的一行
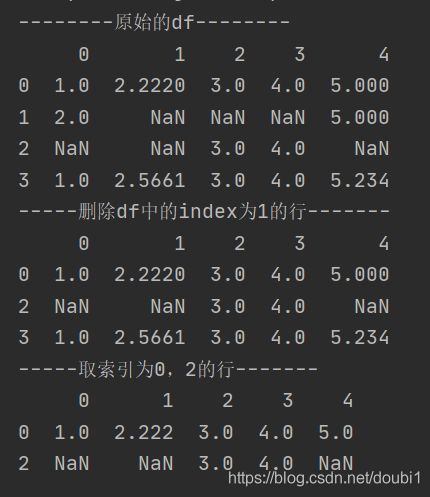
print("--------原始的df--------")
print(df)
print(df.iloc[1,5])
我先定义了一个数组并采用pandas转为DataFrame,然后采用iloc去取值,运行结果如下
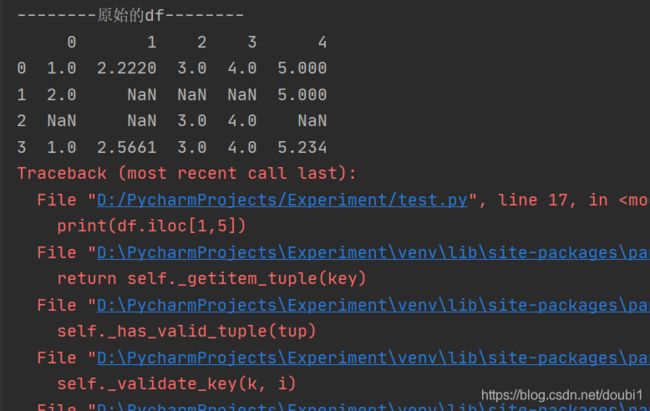
这个例子很简单,我iloc了第5列,但实际没有,所以报错。
2.进阶
而我实现的功能较为复杂,是需要先删除掉一些行,再根据索引去取多行的值。这里调了半天才发现,iloc是取的相对位置,而不是根据索引取的行。
举例:
import pandas as pd
dataset=[[1,2.222,3,4,5],[2,None,None,None,5],[None,None,3,4,None],[1,2.5661,3,4,5.234]]
df=pd.DataFrame(dataset)
# 删除df中的一行
print("--------原始的df--------")
print(df)
print("-----删除df中的index为1的行-------")
df=df.drop([1])
print(df)
print("-----采用iloc打印df的1-------")
print(df.iloc[[1]])
# 根据索引进行打印
print("-----根据索引进行打印-------")
print(df.iloc[[df.index.get_loc(2)]])
运行结果
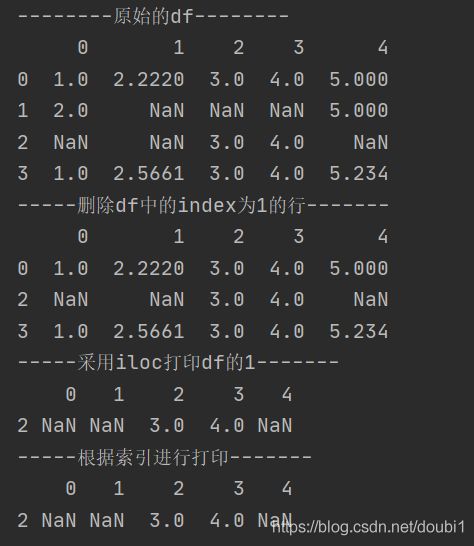
从这里我们可以看出,当我们删除索引为1的行时,我们用iloc[1]实际取的是相对的第1行,真正根据索引去去要先采用
index=df.index.get_loc(2)#2是索引号
然后再用iloc[index]去取索引2对应的行。
3.根据行索引值取多行
先放源码
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# @Time : 2020/12/11 20:18
# @Author : Lijuan Ren
import numpy as np
import pandas as pd
#根据索引获得iloc的行号
def get_multi_row_by_index(dataset, index_list):
datas_with_index = []
for i in range(len(index_list)):
data = dataset.index.get_loc(index_list[i])
datas_with_index.append(data)
return datas_with_index
dataset=[[1,2.222,3,4,5],[2,None,None,None,5],[None,None,3,4,None],[1,2.5661,3,4,5.234]]
df=pd.DataFrame(dataset)
copy_df=np.copy(df)
# 删除df中的一行
print("--------原始的df--------")
print(df)
print("-----删除df中的index为1的行-------")
df=df.drop([1])
print(df)
print("-----取索引为0,2的行-------")
index_list=[0,2]
iloc_index=get_multi_row_by_index(df, index_list)
print(df.iloc[iloc_index])
运行结果