ImageNet Classification with Deep ConvolutionalNeural Networks--文献笔记
摘要
作者训练了一个庞大深层卷积神经网络,在ImageNet LSVRC-2010比赛中,将120万张高分辨率图像分为1000个类别。
测试数据上,错误率 :top-1 =37.5% 、top-5 = 17.0% .
神经网络包括 6000万个参数和650,000个神经元,由5个卷积层,其中一些之后是最大池化层,以及3个全连接层,最后是1000个softmax输出。
为了加快训练速度,采用非饱和神经元 和 能高效进行卷积运算的GPU实现。
为了减少过拟合,采用了新开发的 ' dropout '正则化方法。
介绍
本文的具体贡献如下:
在 ILSVRC-2010 和 ILSVRC-2012 竞赛 中使用的 ImageNet 子集上训练了迄今为止最大的卷积神经网络之一,并取得了迄今为止报告的最佳结果这些数据集。我们编写了一个高度优化的 2D 卷积 GPU 实现以及训练卷积神经网络中固有的所有其他操作。我们的网络包含许多新的和不寻常的特征,这些特征可以提高其性能并减少其训练时间。我们网络的规模使得过度拟合成为一个严重的问题,即使有 120 万个标记的训练示例,所以我们使用了几个防止过拟合的有效技术。我们的最终网络包含五个卷积层和三个全连接层,这个深度似乎很重要:我们发现删除任何卷积层(每个卷积层包含不超过 1 % 的模型参数)导致性能不佳。
最后,网络的大小主要受到当前 GPU 上可用内存量和我们愿意容忍的训练时间量的限制。我们的网络需要五到六天的时间在两个 GTX 580 3GB GPU 上进行训练。我们所有的实验都表明,我们的结果可以通过等待更快的 GPU 和更大的数据集变得可用来改进。
数据集
ImageNet是一个拥有超过1500万个已标记高分辨率图像的数据集,大概有22,000个类别。
ImageNet大型视觉识别挑战赛(ILSVRC)
ILSVRC使用的是ImageNet的一个子集,每1000个类别中大约有1000个图像。总共有大约120万张训练图像,50,000张验证图像和150,000张测试图像。
ImageNet由可变分辨率的图像组成,而我们的系统需要固定的输入尺寸。
我们将图像下采样到256×256的固定分辨率。给定一个矩形图像,我们首先重新缩放图像,使得短边长度为256,然后从结果中裁剪出中心的256×256的图片。除了将每个像素中减去训练集的像素均值之外,我们没有以任何其他方式对图像进行预处理。所以我们在像素的(中心)原始RGB值上训练了我们的网络。
结构
包含八个学习层——五个卷积层和三个全连接层。
1、Relu非线性单元
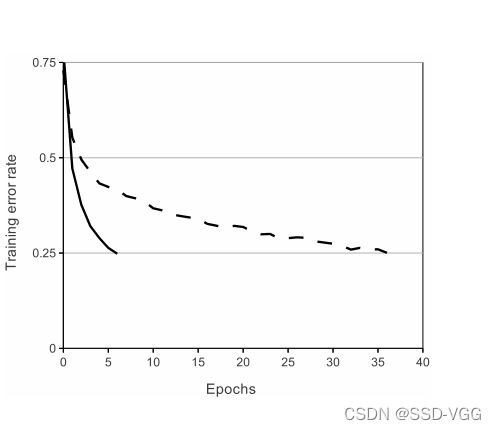
该图展示了对于一个特定的四层CNN,CIFAR-10数据集训练中的误差率达到25%所需要的迭代次数。具有 ReLU 的网络始终比具有饱和神经元的网络快几倍。
2、在多个GPU上训练
单个 GTX 580 GPU 只有 3GB 内存,120 万个训练样本足以训练太大而无法在一个 GPU 上容纳的网络。
因此,我们将网络分布在两个 GPU 上。
两种方法:
1、跨 GPU 并行化;
2、GPU 仅在某些层中通信(论文采用这种,该方案分别将我们的top-1和top-5错误率分别降低了1.7%和1.2%。)
双GPU网络的训练时间比单GPU网络更少。
3、局部响应归一化
响应归一化将我们的top-1和top-5的错误率分别降低了1.4%和1.2%。
4、重叠池化
池化层可以被认为是由间隔 s 个像素的池化单元网格组成,每个池化单元汇总一个大小为 z × z 的邻域,以池化单元的位置为中心。
设置s < z,得到重叠池化。
令s = 2 和 z = 3,该方案将 top-1 和 top-5 错误率分别降低了 0.4% 和 0.3%.
5、整体网络
这个网络包含了八层权重;前五个是卷积层,其余三个为全连接层。最后的全连接层的输出被送到1000维的softmax函数,其产生1000个类的预测。

我们的 CNN 架构示意图,明确显示了两个 GPU 之间的职责划分。一个 GPU 运行图顶部的层部分,而另一个 GPU 运行底部的层部分。 GPU 仅在某些层进行通信。网络的输入为 150,528 维,网络剩余层的神经元数量由 253,440–186,624–64,896–64,896–43,264–4096–4096–1000 给出。
---------------------------------------------------------------------------------------------------------------------------------
第二,第四和第五个卷积层的内核仅与上一层存放在同一GPU上的内核映射相连(见上图)。第三个卷积层的内核连接到第二层中的所有内核映射。全连接层中的神经元连接到前一层中的所有神经元。响应归一化层紧接着第一个和第二个卷积层。 最大池化层,后面连接响应归一化层以及第五个卷积层。将ReLU应用于每个卷积层和全连接层的输出。
第一个卷积层的输入为224×224×3的图像,对其使用96个大小为11×11×3、步长为4(步长表示内核映射中相邻神经元感受野中心之间的距离)的内核来处理输入图像。
第二个卷积层将第一个卷积层的输出(响应归一化以及池化)作为输入,并使用256个内核处理图像,每个内核大小为5×5×48。
第三个、第四个和第五个卷积层彼此连接而中间没有任何池化或归一化层。
第三个卷积层有384个内核,每个的大小为3×3×256,其输入为第二个卷积层的输出。
第四个卷积层有384个内核,每个内核大小为3×3×192。
第五个卷积层有256个内核,每个内核大小为3×3×192。
全连接层各有4096个神经元。
过拟合
两种方法:
1、数据增强
减小过拟合的最简单且最常用的方法就是,使用标签保留转换,人为的放大数据集。
2、添加dropout
它会以50%的概率将隐含层的神经元输出置为0。
以这种方法被置0的神经元不参与网络的前馈和反向传播。因此,每次给网络提供了输入后,神经网络都会采用一个不同的结构,但是这些结构都共享权重。这种技术减少了神经元的复杂适应性,因为神经元无法依赖于其他特定的神经元而存在。因此,它被迫学习更强大更鲁棒的功能,使得这些神经元可以与其他神经元的许多不同的随机子集结合使用。以这种方法被置0的神经元不参与网络的前馈和反向传播。因此,每次给网络提供了输入后,神经网络都会采用一个不同的结构,但是这些结构都共享权重。这种技术减少了神经元的复杂适应性,因为神经元无法依赖于其他特定的神经元而存在。因此,它被迫学习更强大更鲁棒的功能,使得这些神经元可以与其他神经元的许多不同的随机子集结合使用。
Dropout大概会使达到收敛的迭代次数翻倍。
训练细节
使用随机梯度下降的方法来训练我们的模型;
batch = 128
动量 = 0.9
权重衰减 = 0.0005
(权重衰减在这里不仅仅是一个正则化方法:它减少了模型的训练误差。)
学习率 = 0.01
结果
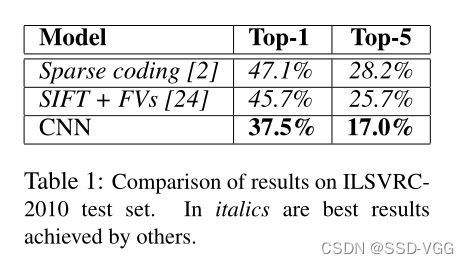
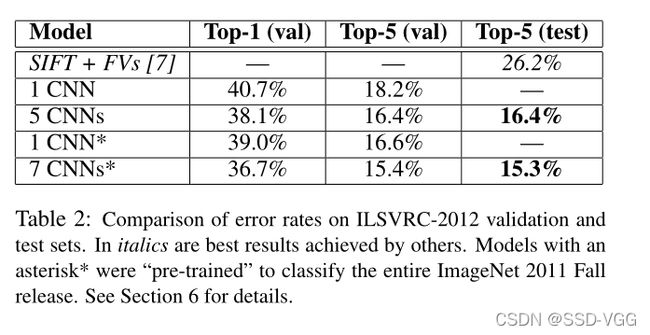
讨论
研究结果表明,一个大的深层卷积神经网络能够在纯粹使用监督学习的情况下,在极具挑战性的数据集上实现破纪录的结果。值得注意的是,如果移除任何一个卷积层,网络的性能就会下降。例如,删除任何中间层的结果会导致网络性能的top-1错误率下降2%。因此网络的深度对于实现我们的结果真的很重要。
参考:
(22条消息) AlexNet论文(ImageNet Classification with Deep Convolutional Neural Networks)(译)_hongbin_xu的博客-CSDN博客_alexnet论文