Python-Sklearn内置数据集介绍与“三板斧”
Python-Sklearn内置数据集介绍与“三板斧”
- 前言
- 一、sklearn相关介绍
-
- 1. sklearn简介
- 2. sklearn基本操作
- 二、鸢尾花数据集(iris)
-
- 1. 数据集相关介绍
- 2. 导入iris数据集,加载数据
- 3. 查看数据集基本信息相关操作
- 4. 转化数据框,生成表格
- 三、波士顿房价数据集(boston)
-
- 1. 数据集相关介绍
- 2. 导入boston数据集,加载数据
- 3. 查看数据集基本信息相关操作
- 4. 转化数据框,生成表格
- 四、手写数字数据集(digits)
-
- 1. 数据集相关介绍
- 2. 导入digits数据集,加载数据
- 3. 查看数据集基本信息相关操作
- 4. 矩阵可视化,显示图片
- 五、sklearn“三板斧”
-
- 1. 实例化举例
- • Modelclass中基本通用方法
- 2. fit举例
- 3. fit_transform举例
- fit_predict举例
- 六、模型的保存(持久化)
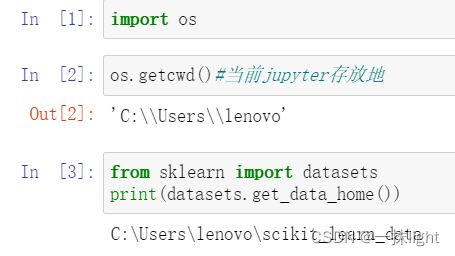
- 七、查找文件储存位置os
前言
上学期学习了专业课数据挖掘,打算利用寒假时间在CSDN上复习整理数据挖掘的相关笔记进行复习巩固相关理论与代码,与下学期的机器学习相结合。在这里想和大家一起学习一起进步。
首先对sklearn中的内置数据集进行了解,以鸢尾花数据集(iris)和波士顿房价数据集(boston)以及手写数字数据集(digits)为例,学习查看sklearn中自带数据集的相关概论以及数据预处理。接下来将对这几个数据集做相关处理。

一、sklearn相关介绍
1. sklearn简介
- sklearn是scikit-learn的简称,是基于 Python 语言的第三方模块,是简单高效的数据挖掘和数据分析工具。sklearn库集成了一些常用的机器学习方法 ,在进行机器学习任务时,并不需要实现算法,只需要简单的调用sklearn库中提供的模块就能完成大多数的机器学习任务。因此我认为sklearn可以比喻成一个调包侠,我们需要理解并熟练运用有关代码。
- sklearn库是在Numpy、Scipy和matplotib的基础 上开发而成的,因此在介绍sklearn的安装前,需要先安装这些依赖库。
2. sklearn基本操作

scikit-learn分别为6大类:
• 分类Classification
• 回归Regression
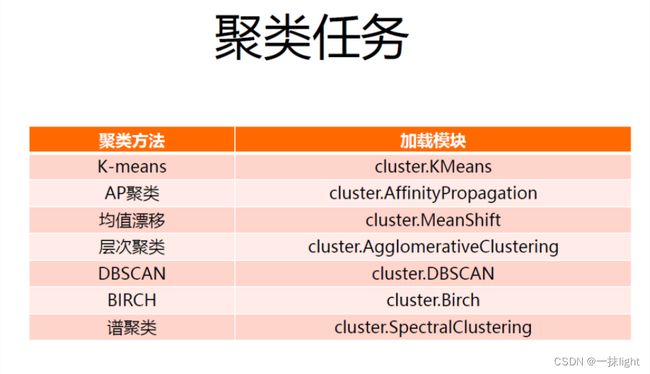
• 聚类Clustering
• 降维Dimensionality reduction
• 模型选择Model selection
• 数据预处理Preprocessing




二、鸢尾花数据集(iris)
1. 数据集相关介绍
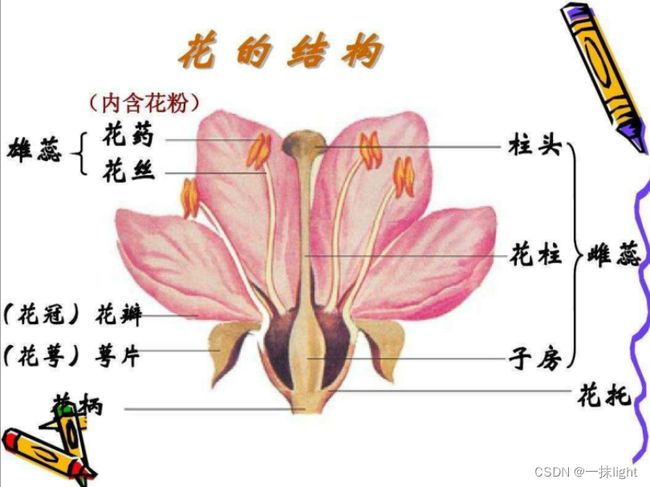
• iris鸢尾花数据集,分类数据集,查看内置数据集
• 因变量:Iris-Setosa刚毛鸢尾花;Iris-Versicolour变色鸢尾花;Iris-Virginica佛吉尼亚鸢尾花
• 自变量:萼片长度(cm);萼片宽度(cm);花瓣长度(cm);花瓣宽度(cm)
2. 导入iris数据集,加载数据
import sklearn#导入sklearn包
from sklearn.datasets import load_iris#导入自带iris数据集集,iris数据集分类问题
iris = load_iris()#导入iris数据集,加载数据
#iris
3. 查看数据集基本信息相关操作
iris.keys()#字典形式返回,特征、目标变量、标签、目标变量名、数据集介绍、特征变量名、文件名
![]()
字典形式返回,特征、目标变量、标签、目标变量名、数据集介绍、特征变量名、文件名
iris.filename#查看储存地址
![]()
print(iris.DESCR)#数据集内容

iris.target_names#查看目标变量名称
![]()
iris.target.shape#查看目标变量数目
![]()
iris.target#目标变量用0、1、2分别表示'setosa', 'versicolor', 'virginica'

目标变量用0、1、2分别表示’setosa’, ‘versicolor’, ‘virginica’
iris.feature_names#查看特征名称
萼片长度(cm);萼片宽度(cm);花瓣长度(cm);花瓣宽度(cm)

iris.data#等价于iris['data']
iris['data'].shape#行、列
该数据集共有150组数据,特征分别为萼片长度(cm);萼片宽度(cm);花瓣长度(cm);花瓣宽度(cm)
![]()
4. 转化数据框,生成表格
生成表格,更直观地观察数据
#转换数据框
import pandas as pd
iris_df = pd.DataFrame(iris.data,columns = iris.feature_names)#普通数据转化DataFrame
#columns 用什么命名
iris_df

#加一列
iris_df['class'] = iris.target
iris_df

三、波士顿房价数据集(boston)
1. 数据集相关介绍
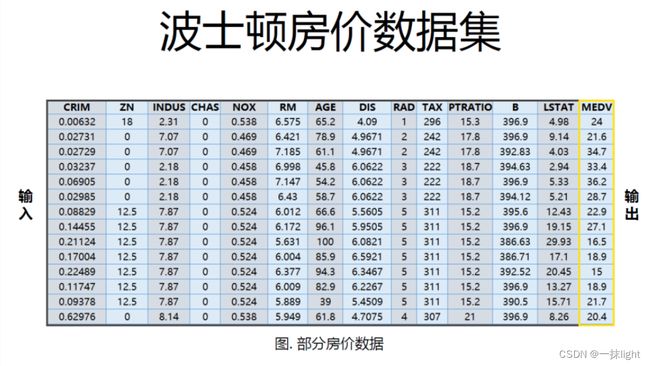
波士顿房价数据集包含506组数据,每条数据包含房屋以及房屋周围的详细信息。其中包括城镇犯罪率、一-氧化氮浓度、住宅平均房间数、到中心区域的加权距离以及自住房平均房价等。因此,波士顿房价数据集能够应用到回归问题上。

2. 导入boston数据集,加载数据
• 方法一
from sklearn import datasets
boston = datasets.load_boston()
boston#查看数据信息
• 方法二
from sklearn.datasets import load_boston
boston=load_boston()
3. 查看数据集基本信息相关操作
boston.keys()#字典形式返回,特征、目标变量、特征变量名、数据集介绍、文件名
![]()
boston.filename#查看储存地址
print(boston.DESCR)#数据集内容

boston.feature_names#查看特征名称
每条数据包含房屋以及房屋周围的详细信息。其中包括城镇犯罪率、一-氧化氮浓度、住宅平均房间数、到中心区域的加权距离以及自住房平均房价等。

boston.data#等价于boston['data']
boston['data'].shape#行、列
包含506组数据

4. 转化数据框,生成表格
更直观查看数据
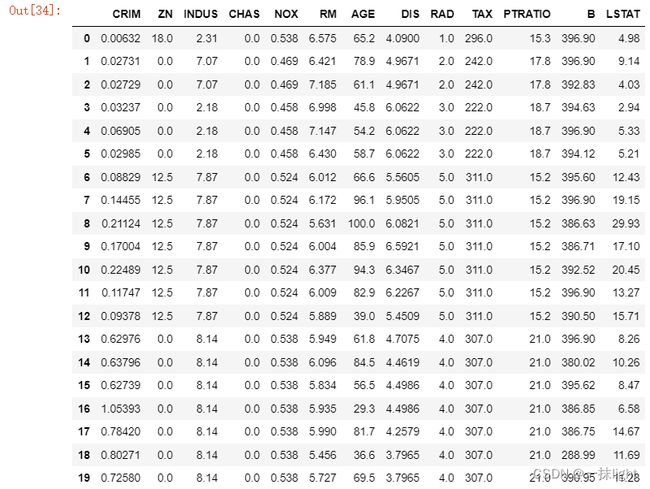
boston_df = pd.DataFrame(boston.data,columns = boston.feature_names)
#boston_df
boston_df.head(20)#查看前20行,若无则查看前5行
四、手写数字数据集(digits)
1. 数据集相关介绍
• 手写数字数据集包括1797个0-9的手写数字数据,每个数字由8*8大小的矩阵构成,矩阵中值的范围是0-16 ,代表颜色的深度。
• 手写数据集,图片处理;存储图片RGB红黄蓝,色数大小,矩阵表示;像素越高矩阵每一格越小,图像越逼真。

2. 导入digits数据集,加载数据
from sklearn.datasets import load_digits
digit=load_digits()
digit
3. 查看数据集基本信息相关操作
digit.keys()
![]()
digit.images.shape
![]()
digit.data.shape#有1797张图片,64维,将原图片拉长
![]()
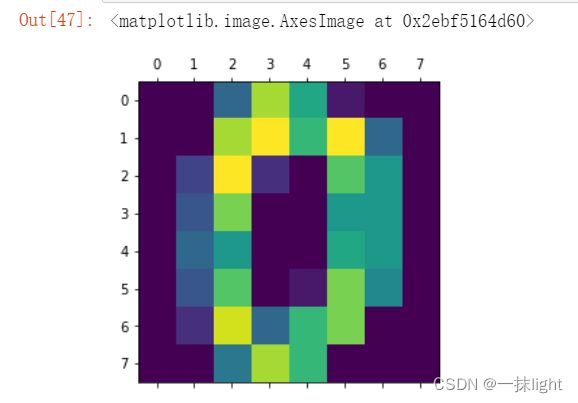
digit.images[0]#数字大颜色深或浅

4. 矩阵可视化,显示图片
import matplotlib.pyplot as plt
%matplotlib inline
#矩阵可视化,显示图片
plt.matshow(digit.images[0])#可自由选择相关数字
五、sklearn“三板斧”
实例化–>fit 拟合–>transform转化 or Predict预测
1. 实例化举例
from sklearn import preprocessing#预处理
#去除量缸的影响
std = preprocessing.StandardScaler()#实例化
std
![]()
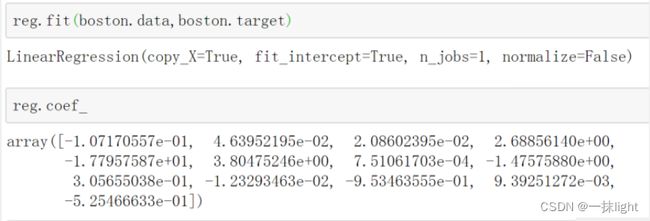
from sklearn import linear_model
reg = linear_model.LinearRegression()
reg
![]()
from sklearn import decomposition
dec = decomposition.PCA()
dec
![]()
from sklearn import svm
svv = svm.SVC()
svv

• Modelclass中基本通用方法

std.get_param()#查看参数

std.set_param(copy=False)#设置参数
![]()
2. fit举例
std.fit(boston.data)
![]()
std.mean_#均值,期望

std.var_#方差

3. fit_transform举例
std.transform(boston.data)#两条命令合二为一

std.fit_transform(boston.data)

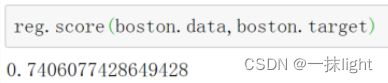
fit_predict举例

六、模型的保存(持久化)
可以直接使用通过使用Python的pickle模块将训练好的模型保存为外部文件,但最好使用sklearn中的joblib模块进行操作。

七、查找文件储存位置os