paper总结(7)Twin Contrastive Learning for Online Clustering
Introduction逻辑(论文动机&现有工作存在的问题)
聚类——其他聚类算法聚焦于设计不同的相似性尺度以及聚类策略——虽然有理论依据,但是模型效果受限于浅层模型——早期的深度聚类算法,需要把整个数据集一起输入,对大规模数据以及流型数据不友好——通过对每一个实例预测簇分配,以实现在大规模数据上的在线聚类
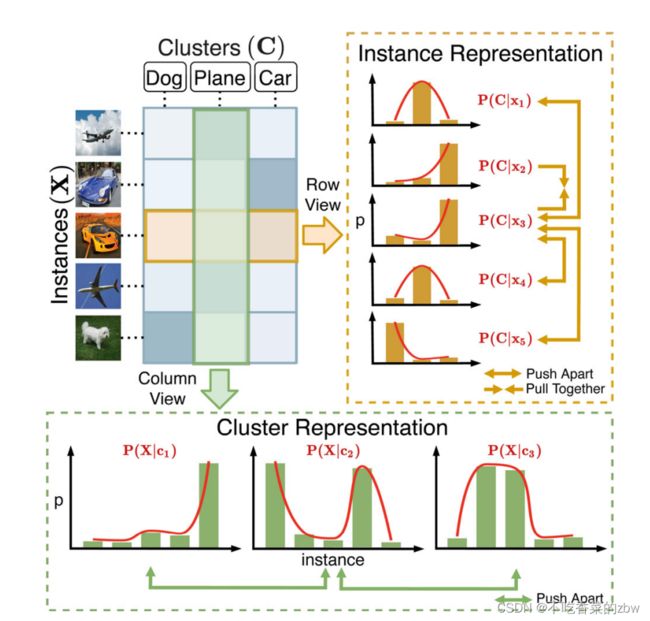
本文提出一个端到端的在线深度聚类模型(twin contrastive learning ,TCL),根据图1的观察所提出的。简要来说,特征矩阵的行列分别对应实例和聚类的特征表示。TCL分别在行列空间指导对比学习。TCL首先通过数据增广来构建对比样本对,使用了一强一弱(SimCLR)的数据增强策略。为了减轻固有假负对的影响,并纠正簇分配结果,选择置信度预测(即簇分配概率接近于one-hot的预测)来微调对比学习。这种策略设计的动机是,高置信度的预测正确率更高,可以作为伪标签使用。一旦模型收敛,可以以端到端的模式独立的对每一个实例进行簇分配。
论文核心创新点
揭示了特征矩阵中,行列与实例、簇的内在联系
新的数据增广策略
减轻内源假阴性的影响
提出了可以实现在线聚类的TCL算法
相关工作
对比学习
深度聚类
论文方法
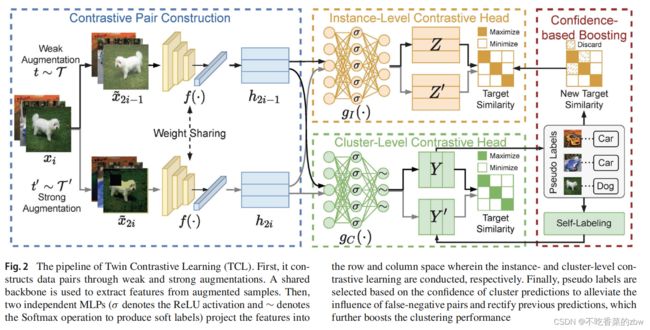
本文提出的TCL算法流程如图2所示,主要由三个部分组成对比对构建(contrastive pair construction,CPC),实例级对比头(intsance-level contrastive head,ICH) 以及簇级对比头(cluster-level contrastive head,CCH),通过双对比学习和基于置信度实现共同优化。
在双对比学习阶段,CPC先是通过数据增广构建对比对,然后将这些对映射到潜在的特征空间中。在这之后,ICH和CCH通过最小化本文提出的双路对比损失,在特征矩阵的行列上,分别指导实例级、簇级的对比学习。为了减轻在对比学习过程中,假阴性的样本对的影响,纠正聚类分布的结果,作者提出了一个基于置信度的加速策略(confidece-based boosting strategy,CB)。CB其实就是将高置信度的预测选择为伪标签,通过自监督对比损失(self-supervised contrastive loss)以及自标签损失(self-labeling loss),对实例级和簇级的对比学习结果进行精调,由此提高模型性能。
一旦模型收敛,CCH可以对每一个实例进行簇分配,以实现在线学习。值得注意的是,虽然双路对比学习可以直接作用于同一个对比头,但是作者的实验结果发现将其解耦到两个独立的子空间更可以进一步提高模型效果。
对比对构建Contrastive Pair Construction
收到其他对比学习算法启发,TCL通过数据增广来构建样本对。具体来说,对于每一个实例 ,TCL分别从两个数据增广家族
,TCL分别从两个数据增广家族![]() 中,各随机采样一个数据增广
中,各随机采样一个数据增广![]() ,将这两个数据增广应用于实例上,得到两个相关的样本(即,数据对),记为
,将这两个数据增广应用于实例上,得到两个相关的样本(即,数据对),记为![]() 。
。
现有的构建样本对的方法往往只使用了弱数据增广。本文提供了一种混合了强、弱增广的数据增广策略,取得了更好的效果。对于图像数据,本文中将SimCLR中使用的数据增广称为弱增广,将RandAugment中的增广称为强增广。
给定一个构建好的数据对,使用一个共享权重的主干网络 来从增广的数据对提取特征
来从增广的数据对提取特征 ,即
,即![]() 。对于图像数据,使用ResNet主干网络。
。对于图像数据,使用ResNet主干网络。
双路对比学习Twin Contrastive Learning
实例级对比损失Instance-Level Contrastive Loss
实例级的对比学习,目标是最大化正对之间的相似性同时最小化负对的相似性。为了实现聚类,理想情况下,将一个类内的实例都定义为正的,类间的实例则为负的。但是,因为没有先验的标签信息提供,作为折衷方案,作者基于数据增广构造实例对。也就是,同一个实例的不同数据增广,则构成正对,反之则是负对。
对于一个尺寸为 的小批次数据,TCL对每一个实例应用两种数据增广,结果得到
的小批次数据,TCL对每一个实例应用两种数据增广,结果得到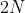 个增广样本
个增广样本![]() 。每个样本
。每个样本![]() 构成
构成 个样本对,其中我们将样本与其对应的增广样本组成的样本对
个样本对,其中我们将样本与其对应的增广样本组成的样本对![]() 称为正样本对,其他的
称为正样本对,其他的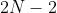 对则为负样本对。
对则为负样本对。
直接在特征矩阵上使用对比损失指导,会导致信息的损失,于是作者使用一个两层的非线性MLP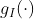 通过
通过![]() 将特征映射到一个子空间,并在该子空间上应用对比损失。使用余弦相似性来计算逐对之间的相似性,即:
将特征映射到一个子空间,并在该子空间上应用对比损失。使用余弦相似性来计算逐对之间的相似性,即:
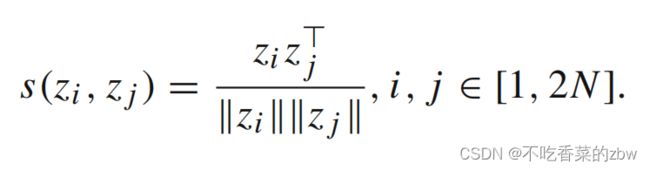
使用InfoNCE损失对余弦相似性进行优化。不失一般性,对于增广样本![]() (假定其与
(假定其与![]() 构成正样本对)的损失定义如下:
构成正样本对)的损失定义如下:
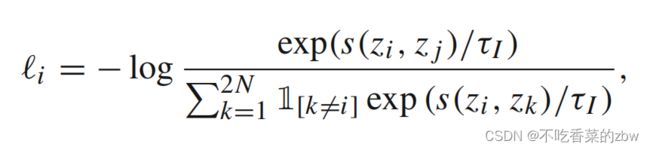
其中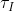 是实例级的温度参数,
是实例级的温度参数,![1_{[k \neq i]}](http://img.e-com-net.com/image/info8/cf8253479e0a4046a720d80cde3e640d.gif) 是一个指示函数,当
是一个指示函数,当![]() 的时候值为1。为每一个样本确定对应的正样本,在所有的增广样本上计算实例级对比损失,即:
的时候值为1。为每一个样本确定对应的正样本,在所有的增广样本上计算实例级对比损失,即:
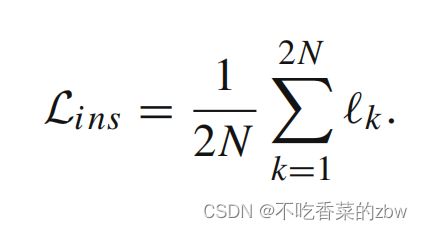
簇级对比损失Cluster-Level Contrastive Loss
当样本被映射到维度为簇的数目的子空间的时候,特征表示中的第 个元素代表该样本属于第个簇的概率。
个元素代表该样本属于第个簇的概率。
设簇的数目为 ,与实例级对比头相似,我们用另一个两层的MLP
,与实例级对比头相似,我们用另一个两层的MLP![]() 通过
通过![]() 映射到维的空间。其中
映射到维的空间。其中 对应增广样本
对应增广样本![]() 的簇分配概率。
的簇分配概率。![]() 记为一个小批次的在弱增广
记为一个小批次的在弱增广 下簇分配概率(并且
下簇分配概率(并且![]() 为一个小批次的在强增广
为一个小批次的在强增广![]() 下簇分配概率)。基于图一的观察,
下簇分配概率)。基于图一的观察, 和
和![]() 的列对应一个小批次中的簇的分配。即使聚类的维度比ground-truth的数目还大,图一的观察也是成立的。
的列对应一个小批次中的簇的分配。即使聚类的维度比ground-truth的数目还大,图一的观察也是成立的。
为了清晰起见,将中的第列记为![]() (
(![]() 的第列记为
的第列记为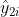 ),即,在弱(强)增广下的簇的特征表示。在两个数据增广下构成的正簇对
),即,在弱(强)增广下的簇的特征表示。在两个数据增广下构成的正簇对![]() ,其他的则为负对。与上文相似,使用余弦相似性来衡量相似性,公式如下:
,其他的则为负对。与上文相似,使用余弦相似性来衡量相似性,公式如下:
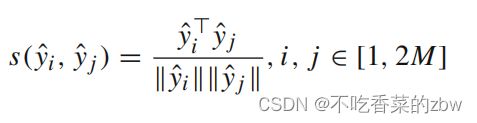
对簇 构成的所有簇对计算簇级对比损失:
构成的所有簇对计算簇级对比损失:
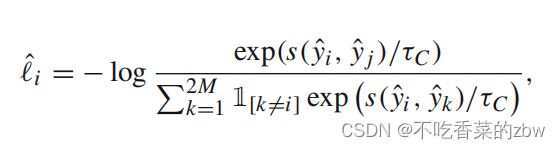
其中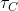 是簇级温度参数,是一个指示函数,当
是簇级温度参数,是一个指示函数,当![]() 的时候值为1。对所有簇计算簇级对比损失:
的时候值为1。对所有簇计算簇级对比损失:

在簇级对比损失做简单的优化可能会导致生成琐碎解,即将大多数簇分配到少量的簇中心。于是添加一个簇熵去避免模型崩溃,可以得到更为均衡的簇分配。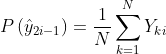 表示弱增广下,一个小批次分配给簇的概率;
表示弱增广下,一个小批次分配给簇的概率;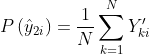 表示强增广下,一个小批次分配给簇的概率。簇熵计算如下:
表示强增广下,一个小批次分配给簇的概率。簇熵计算如下:
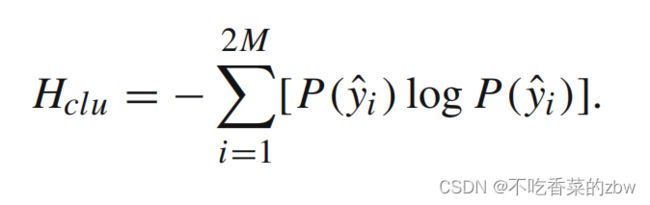
与前式相加,得到簇级的对比损失:
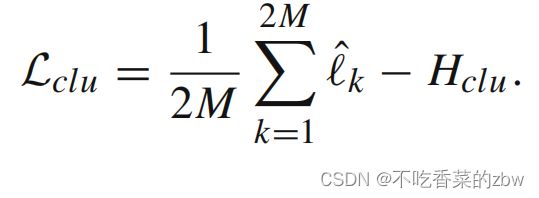
基于置信度的提升Confidence-Based Boosting
在训练过程中,作者注意到模型更倾向于做出更值得相信的预测,并且这些预测的准确率更高。基于对此的观察,在boosting stage,作者选择那些最高置信度的预测作为伪标签,同时对实例级和簇级的对比学习进行精调。
伪标签的选择基于以下准则:
对于一个大小为的小批次,我们使用原始数据 作为输入去计算预测结果,对于每一个实例的预测结果的置信度为
作为输入去计算预测结果,对于每一个实例的预测结果的置信度为![]() ,公式如下:
,公式如下:

在每一个小批次中,从每一个簇中选择![]() 的预测结果作为伪标签,其中
的预测结果作为伪标签,其中 为置信度,固定为0.5。一个预测
为置信度,固定为0.5。一个预测![]() 满足下列准则就会被选为伪标签:
满足下列准则就会被选为伪标签:
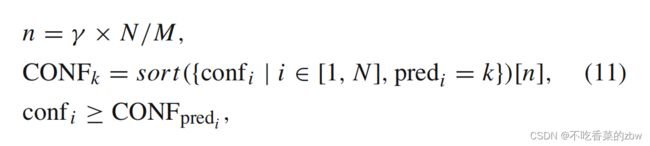
其中![]() 是第
是第 个最大置信度的基于簇
个最大置信度的基于簇![]() 预测结果。值得注意的是,与基于阈值的准则相比,从每个集群中选择最自信的预测会产生更类平衡的伪标签。将所有样本的伪标签存在内存中,记为
预测结果。值得注意的是,与基于阈值的准则相比,从每个集群中选择最自信的预测会产生更类平衡的伪标签。将所有样本的伪标签存在内存中,记为
根据下列公式,使用伪标签对模型进行精调:
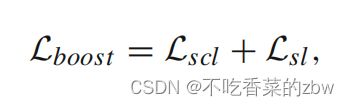
其中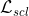 是自监督对比损失,用来减轻假负样本对对于实例级对比学习的影响;
是自监督对比损失,用来减轻假负样本对对于实例级对比学习的影响;![]() 是自标签损失修正由CCH进行的簇分配。
是自标签损失修正由CCH进行的簇分配。
回想在实例级对比学习中,将不同实例的增广样本视为负样本对,这个过程中没有给予标签信息。但是对于下游任务,比如分类和聚类,类内(within-class)的样本不应该被推远。为此,在伪标签的帮助下,从负样本中移除类内的样本,并且应用自监督对比损失对实例级对比学习进行精调。对于每一个增广样本及其伪标签![]() ,自监督对比损失定义如下:
,自监督对比损失定义如下:
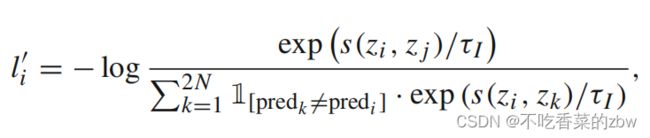
其中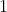 是指示器。受启发于negative learning paradigm,作者只移除了潜在的类内对(within-class pair),但是并没有将其视为正对,考虑到随后的策略会在伪标签更高质量的情况下变得更加鲁棒。遍历了所有的增广样本后,自监督实例级对比损失计算如下:
是指示器。受启发于negative learning paradigm,作者只移除了潜在的类内对(within-class pair),但是并没有将其视为正对,考虑到随后的策略会在伪标签更高质量的情况下变得更加鲁棒。遍历了所有的增广样本后,自监督实例级对比损失计算如下:

对于簇级对比头,自标签策略用来修正之前的预测。将在强增广样本![]() 自标签损失定义为交叉熵损失,即:
自标签损失定义为交叉熵损失,即:
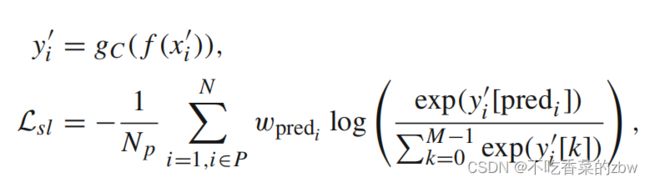
其中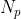 是在一个小批次中有伪标签的实例数量,
是在一个小批次中有伪标签的实例数量,![]() 是对于簇
是对于簇 的权重参数。加权损失可以防止大簇控制优化结果。
的权重参数。加权损失可以防止大簇控制优化结果。
虽然置信率是固定的![]() ,但是也不意味着50%的预测会被选择为伪标签。在boosting和batch shuffle之后,更多的伪标签会被逐步的选择。考虑到模型可能在选择伪标签的过程中犯错,移除了置信度低于阈值的标签,即:
,但是也不意味着50%的预测会被选择为伪标签。在boosting和batch shuffle之后,更多的伪标签会被逐步的选择。考虑到模型可能在选择伪标签的过程中犯错,移除了置信度低于阈值的标签,即:![]() 。其中
。其中 是置信度下界,设为0.99。这种清除机制保持了伪标签的高质量,并使模型有机会纠正以前的预测。
是置信度下界,设为0.99。这种清除机制保持了伪标签的高质量,并使模型有机会纠正以前的预测。
算法流程如下

原文链接:https://blog.csdn.net/qq_43497436/article/details/126759044