【超分辨率】【深度学习】SRCNN pytorch代码(附详细注释和数据集)
超分辨率
- 前言
- 1 数据集预处理
- 2 prepare.py 主要看注释(方便理解)
- 3 train.py 主要看注释
- 4 test.py
- 5 结果对比
前言
主要改进:
- 断点恢复,可以恢复训练。
- 注释掉原test.py的38行才是真正的超分辨率。
即image = image.resize((image.width // args.scale, image.height // args.scale), resample=pil_image.BICUBIC)
其中//代表整除的意思。- model.py存在两个与原论文有出入,请仔细思考,如果想不出来可以联系我,但自己思考更有成就感。
关于第二点的注释可以知道,这份代码更注重于研究图像生成,改善的是图像细节而非分辨率。
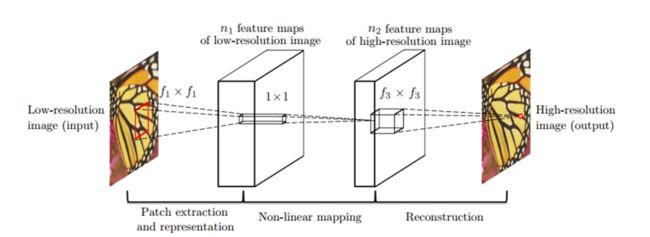
这里主要是对代码进行讲解,对SRCNN不了解的同学可以先去参考其他博文。
原论文链接:Image quality assessment for determining efficacy and limitations of Super-Resolution Convolutional Neural Network (SRCNN)
有问题,不知道如何跑代码的同学联系:[email protected]
代码转自:https://github.com/yjn870/SRCNN-pytorch
对于新学深度学习代码的同学来说,推荐先阅读这一篇文章:
一个完整的Pytorch深度学习项目代码,项目结构是怎样的?
下面是这篇代码的步骤。
1 数据集预处理
首先准备好数据集,这里以img-91作为训练集,Set5作为测试集。
数据集:
https://pan.baidu.com/s/1Mmgh5xMsnYyDUpG6xbb9iw?pwd=bkac
运行prepare.py 将两个数据集转为h5格式。(测试集要在命令加上 --eval)
之后运行train.py
2 prepare.py 主要看注释(方便理解)
import argparse
import glob
import h5py
import numpy as np
import PIL.Image as pil_image
from utils import convert_rgb_to_y
def train(args):
h5_file = h5py.File(args.output_path, 'w')
lr_patches = []
hr_patches = []
for image_path in sorted(glob.glob('{}/*'.format(args.images_dir))):
#将照片转换为RGB通道
hr = pil_image.open(image_path).convert('RGB')
#取放大倍数的倍数
hr_width = (hr.width // args.scale) * args.scale
hr_height = (hr.height // args.scale) * args.scale
#图像大小调整
hr = hr.resize((hr_width, hr_height), resample=pil_image.BICUBIC)
#低分辨率图像缩小
lr = hr.resize((hr_width // args.scale, hr_height // args.scale), resample=pil_image.BICUBIC)
#低分辨率图像放大
lr = lr.resize((lr.width * args.scale, lr.height * args.scale), resample=pil_image.BICUBIC)
#转换为浮点并取ycrcb中的y通道
hr = np.array(hr).astype(np.float32)
lr = np.array(lr).astype(np.float32)
hr = convert_rgb_to_y(hr)
lr = convert_rgb_to_y(lr)
for i in range(0, lr.shape[0] - args.patch_size + 1, args.stride):
for j in range(0, lr.shape[1] - args.patch_size + 1, args.stride):
lr_patches.append(lr[i:i + args.patch_size, j:j + args.patch_size])
hr_patches.append(hr[i:i + args.patch_size, j:j + args.patch_size])
lr_patches = np.array(lr_patches)
hr_patches = np.array(hr_patches)
#创建数据集
h5_file.create_dataset('lr', data=lr_patches)
h5_file.create_dataset('hr', data=hr_patches)
h5_file.close()
#下同
def eval(args):
h5_file = h5py.File(args.output_path, 'w')
lr_group = h5_file.create_group('lr')
hr_group = h5_file.create_group('hr')
for i, image_path in enumerate(sorted(glob.glob('{}/*'.format(args.images_dir)))):
hr = pil_image.open(image_path).convert('RGB')
hr_width = (hr.width // args.scale) * args.scale
hr_height = (hr.height // args.scale) * args.scale
hr = hr.resize((hr_width, hr_height), resample=pil_image.BICUBIC)
lr = hr.resize((hr_width // args.scale, hr_height // args.scale), resample=pil_image.BICUBIC)
lr = lr.resize((lr.width * args.scale, lr.height * args.scale), resample=pil_image.BICUBIC)
hr = np.array(hr).astype(np.float32)
lr = np.array(lr).astype(np.float32)
hr = convert_rgb_to_y(hr)
lr = convert_rgb_to_y(lr)
lr_group.create_dataset(str(i), data=lr)
hr_group.create_dataset(str(i), data=hr)
h5_file.close()
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--images-dir', type=str, required=True)
parser.add_argument('--output-path', type=str, required=True)
parser.add_argument('--patch-size', type=int, default=32)
parser.add_argument('--stride', type=int, default=14)
parser.add_argument('--scale', type=int, default=4)
parser.add_argument('--eval', action='store_true')
args = parser.parse_args()
if not args.eval:
train(args)
else:
eval(args)
3 train.py 主要看注释
之后运行,看不懂注释可以先去其他博文了解SRCNN的网络结构和训练过程。
import argparse
import os
import copy
import numpy as np
from torch import Tensor
import torch
from torch import nn
import torch.optim as optim
##gpu加速库
import torch.backends.cudnn as cudnn
from torch.utils.data.dataloader import DataLoader
#进度条
from tqdm import tqdm
from model import SRCNN
from datasets import TrainDataset, EvalDataset
from utils import AverageMeter, calc_psnr
##需要修改的参数
#epoch.pth
#losslog
#psnrlog
#best.pth
if __name__ == '__main__':
#初始参数设定
parser = argparse.ArgumentParser()
parser.add_argument('--train-file', type=str, required=True)
parser.add_argument('--eval-file', type=str, required=True)
parser.add_argument('--outputs-dir', type=str, required=True)
parser.add_argument('--scale', type=int, default=3)
parser.add_argument('--lr', type=float, default=1e-4)
parser.add_argument('--batch-size', type=int, default=16)
parser.add_argument('--num-workers', type=int, default=0)
parser.add_argument('--num-epochs', type=int, default=400)
parser.add_argument('--seed', type=int, default=123)
args = parser.parse_args()
#输出放入固定文件夹里
args.outputs_dir = os.path.join(args.outputs_dir, 'x{}'.format(args.scale))
if not os.path.exists(args.outputs_dir):
os.makedirs(args.outputs_dir)
#benckmark模式,加速计算,但寻找最优配置,计算的前馈结果会有差异
cudnn.benchmark = True
#gpu模式
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
#每次程序运行生成的随机数固定
torch.manual_seed(args.seed)
#运算模式
model = SRCNN().to(device)
#恢复训练
#model.load_state_dict(torch.load('outputs/x3/epoch_173.pth'))
#代价函数MSE
criterion = nn.MSELoss()
#优化函数Adam,lr代表学习率
optimizer = optim.Adam([
{'params': model.conv1.parameters()},
{'params': model.conv2.parameters()},
{'params': model.conv3.parameters(), 'lr': args.lr*0.1}
], lr=args.lr)
#预处理训练集
train_dataset = TrainDataset(args.train_file)
train_dataloader = DataLoader(
#数据
dataset=train_dataset,
#分块
batch_size=args.batch_size,
#数据集数据洗牌,打乱后取batch
shuffle=True,
#工作进程,像是虚拟存储器中的页表机制
num_workers=args.num_workers,
#锁页内存,不换出内存
pin_memory=True,
#不取余,丢弃不足batchSize的图像
drop_last=True)
#预处理验证集
eval_dataset = EvalDataset(args.eval_file)
eval_dataloader = DataLoader(dataset=eval_dataset, batch_size=1)
#拷贝权重
best_weights = copy.deepcopy(model.state_dict())
best_epoch = 0
best_psnr = 0.0
#画图用
lossLog=[]
psnrLog=[]
#恢复训练
#for epoch in range(args.num_epochs):
for epoch in range(1, args.num_epochs + 1):
#for epoch in range(174, 400):
#模型训练入口
model.train()
#变量更新,计算epoch平均损失
epoch_losses = AverageMeter()
#进度条,就是不要不足batchsize的部分
with tqdm(total=(len(train_dataset) - len(train_dataset) % args.batch_size)) as t:
#t.set_description('epoch:{}/{}'.format(epoch, args.num_epochs - 1))
t.set_description('epoch:{}/{}'.format(epoch, args.num_epochs))
#每个batch计算一次
for data in train_dataloader:
#对应datastes.py中的__getItem__,分别为lr,hr图像
inputs, labels = data
inputs = inputs.to(device)
labels = labels.to(device)
#训练
preds = model(inputs)
#获得损失
loss = criterion(preds, labels)
#显示损失值与长度
epoch_losses.update(loss.item(), len(inputs))
#梯度清零
optimizer.zero_grad()
#反向传播
loss.backward()
#更新参数
optimizer.step()
#进度条更新
t.set_postfix(loss='{:.6f}'.format(epoch_losses.avg))
t.update(len(inputs))
#记录lossLog 方面画图
lossLog.append(np.array(epoch_losses.avg))
#可以在前面加上路径
np.savetxt("lossLog.txt", lossLog)
#保存模型
torch.save(model.state_dict(), os.path.join(args.outputs_dir, 'epoch_{}.pth'.format(epoch)))
#是否更新当前最好参数
model.eval()
epoch_psnr = AverageMeter()
for data in eval_dataloader:
inputs, labels = data
inputs = inputs.to(device)
labels = labels.to(device)
#验证不用求导
with torch.no_grad():
preds = model(inputs).clamp(0.0, 1.0)
epoch_psnr.update(calc_psnr(preds, labels), len(inputs))
print('eval psnr: {:.2f}'.format(epoch_psnr.avg))
#记录psnr
psnrLog.append(Tensor.cpu(epoch_psnr.avg))
np.savetxt('psnrLog.txt', psnrLog)
if epoch_psnr.avg > best_psnr:
best_epoch = epoch
best_psnr = epoch_psnr.avg
best_weights = copy.deepcopy(model.state_dict())
print('best epoch: {}, psnr: {:.2f}'.format(best_epoch, best_psnr))
torch.save(best_weights, os.path.join(args.outputs_dir, 'best.pth'))
print('best epoch: {}, psnr: {:.2f}'.format(best_epoch, best_psnr))
torch.save(best_weights, os.path.join(args.outputs_dir, 'best.pth'))
4 test.py
之后运行test.py就可以了,其中跟train.py差不多就不注释了。
test.py是放入图片、权重和倍数就行,会生成两张图片。
5 结果对比


