《SCAttNet: Semantic Segmentation Network with Spatial and Channel ......Remote Sensing Images》
论文阅读笔记:《SCAttNet: Semantic Segmentation Network with Spatial and Channel Attention Mechanism for High-Resolution Remote Sensing Images》
论文下载地址:https://ieeexplore.ieee.org/document/9081937
转载请注明:https://blog.csdn.net/weixin_42143615/article/details/109168980
一、论文简介
高分辨率遥感图像(HRRSIs)包含大量地物信息,如纹理、形状和空间位置。语义分割是像素提取的一项重要任务,在海量HRRSIs处理中得到了广泛的应用。然而,由于地物的多样性和复杂性,HRRSIs往往表现出较大的类内方差和较小的类间方差,给语义分割任务带来了很大的挑战。文章的核心工作:
1、提出了一种新的基于空间和通道注意的语义分割网络SCAttNet,网络集成了轻量级的空间和通道注意模块,能够自适应地细化特征。
2、将空间和通道注意模块学习到的特征形象化,以解释为什么我们的方法有效。
3、在Vaihingen和Potsdam数据集上的实验表明,通过空间和通道注意模块来学习HRRSIs的特征,在小目标上获得的结果得到了显著性提升。
二、论文内容
2.1 引言
遥感图像的语义分割是将图像中的每一个像素划分为一个特定类别的基本任务。
传统的方法利用物体的颜色、纹理、形状和空间位置关系来提取特征,然后使用聚类、分类和阈值算法分割图像。然而,这些方法在很大程度上依赖于人为的设计特征,并显示出一些瓶颈。近年来,基于深度学习的方法被认为是解决图像语义分割问题的一种很有前途的方法。例如,基于全卷积网络(FCN)的方法已经在许多自然图像数据集上获得了最先进的分割结果。
遥感图像不同于自然图像,通常从自上而下的角度观看。因此,成像范围广,背景复杂多样。特别是在高分辨率遥感影像中,地物的差异更加显著。为了有效地分割HRRSIs,人们提出了许多先进的方法。
近年来,注意力机制已经成功地应用于语义分割。这些方法可分为两类:一种是利用注意力机制在通道维度上选择有意义的特征。然而,这些方法并没有考虑到在空间维度上增强特征表示。另一种是自我注意机制,它通过加权和所有其他位置的特征来计算每个位置的特征表示。这样就可以对任务的语义信息进行长范围的分割。不过,这些方法在模型尺寸上比较复杂,计算效率低下,这将给海量遥感图像的处理带来很大的挑战。文中采用两个包含空间注意和通道注意的轻量级注意模块对HRRSIs进行语义分割。空间注意模块对HRRSIs的空间特征进行建模,通道注意模块捕获需要增强的内容。整合这两个注意模块可以有效地提高语义切分的准确性。
2.2 方法
2.2.1 SCAttNet概述
提出的语义分割网络如图1所示。它由两部分组成:特征提取网络和注意模块。注意模块由通道注意模块和空间注意模块级联而成。对于输入的遥感图像,首先利用主干网络进行特征提取。然后将提取出来的特征映射输入到通道注意模块中,对通道中的特征进行细化。然后,我们将细化后的通道特征图输入到空间注意模块中,在空间轴上进行细化。最后,通过卷积和SoftMax运算得到语义分割结果。
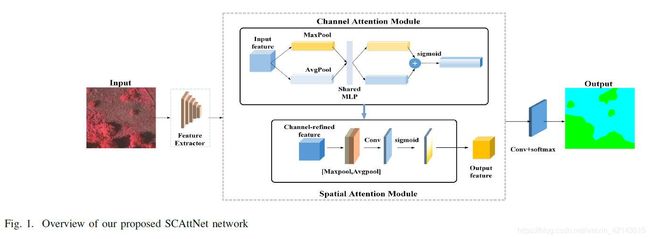
2.2.2 特征提取架构
文中使用两个具有代表性的架构进行特征提取:SegNet和ResNet50。在此基础上,提出了两种网络:以SegNet为主干的SCAttNet V1和以ResNet50为主干的SCAttNet V2。对于SegNet网络,它作为遥感图像语义分割的基本模型得到了广泛的应用,取得了良好的语义分割效果。ResNet50也是语义分割任务的通用架构,因为它可以构建一个具有广泛接受域的深层模型。在我们的工作中,我们对ResNet50使用了8次降采样。与SegNet和ResNet50网络不同,我们不直接利用最后一层的特征进行语义推理,而是将最后一层的特征映射输入注意模块进行特征细化,然后进行语义推理,有利于学习更好的特征表达。
2.2.3 注意模块
(1)通道注意模块
给出一幅高分辨率遥感图像,它将产生一幅经过几个卷积层之后的多通道特征图![]() (其中C,H,W表示通道数,特征图高度和宽度)。每个通道的特征图所表达的信息是不同的。信道注意的目的是利用每个信道之间的关系特征映射学习一个1D权值
(其中C,H,W表示通道数,特征图高度和宽度)。每个通道的特征图所表达的信息是不同的。信道注意的目的是利用每个信道之间的关系特征映射学习一个1D权值![]() ,然后将其乘以相应的通道。这样,它就可以更加关注当前任务中有意义的语义信息。为了学习有效的权重表示,我们首先通过全局平均池和全局最大池来聚合空间维度信息,为每个通道生成两个特征描述符。然后将这两个特征描述器输入一个具有一个隐藏层(其中隐藏层单元数为C/8)的共享多层感知器,生成更具代表性的特征向量。然后,我们通过元素求和运算合并输出特征向量。最后,利用sigmoid函数,得到最终的通道注意图。在图1的通道注意模块中示出了该流程图。信道注意的计算公式如公式1所示:
,然后将其乘以相应的通道。这样,它就可以更加关注当前任务中有意义的语义信息。为了学习有效的权重表示,我们首先通过全局平均池和全局最大池来聚合空间维度信息,为每个通道生成两个特征描述符。然后将这两个特征描述器输入一个具有一个隐藏层(其中隐藏层单元数为C/8)的共享多层感知器,生成更具代表性的特征向量。然后,我们通过元素求和运算合并输出特征向量。最后,利用sigmoid函数,得到最终的通道注意图。在图1的通道注意模块中示出了该流程图。信道注意的计算公式如公式1所示:

![]()
(2)空间注意模块
对于空间注意,它关注的是对当前任务有价值的地方。在高分辨率遥感影像中,地物的表现形式多样,分布复杂。因此,利用空间注意有助于聚集空间信息,特别是对于小型地物。空间注意利用不同空间位置之间的关系来学习二维空间权重图Ws,然后将其乘以相应的空间位置以学习更具代表性的特征。为了有效地学习空间权重关系,我们首先通过全局平均池和全局最大池操作为每个空间位置生成两个特征描述符。然后将两个特征描述子连接在一起,通过7×7卷积运算生成空间注意图。最后,我们使用一个sigmoid函数将空间注意映射缩放到0∼1。在图1的空间注意模块中示出了流程图。空间注意的计算公式如公式2所示。
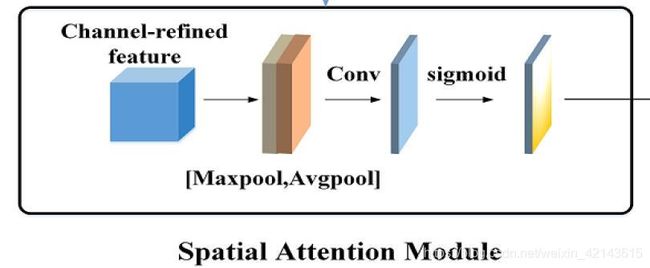
![]()
其中![]() 代表与7×7卷积核大小的卷积操作。
代表与7×7卷积核大小的卷积操作。
我们可以很容易地计算出,对于我们的scattnetv1和scattnetv2,注意模块的参数数目非常小,以至于可以忽略它们。具体而言,通道注意模块的参数个数为C×C/4(C为通道数),空间注意模块的参数个数为98。另外,我们只在主干网的终端层增加了注意模块,因此很少给我们的网络带来计算复杂度。
在本研究中,我们遵循Woo的方法对这两个注意模块进行整合。首先,利用通道注意在每一层选择有意义的特征映射,然后利用空间注意在每个特征映射中选择相当数量的神经元活动,有利于提取更有价值的特征表达。
2.3 实验
在本节中,我们将评估我们的网络在ISPRS Vaihingen和ISPRS Potsdam数据集中的性能。
2.3.1 数据集和评估指标
ISPRS Vaihingen数据集包含33个正射影像图和相关的DSMs。其中16个被贴上标签。图像平均尺寸为2494×2064,分辨率为9cm。每幅图像包含三个波段:近红外波段、红色波段和绿色波段。此外,它还包括六个类别:不透水的表面、建筑物、低植被、树木、汽车和杂物/背景。ISPRS Potsdam数据集包含38个正射影像图和相关的标准化DSMs。其中24个被贴上标签。每幅图像尺寸为6000×6000,分辨率为5cm。每幅图像包含四个波段:近红外、红色、绿色和蓝色波段。它有与ISPRS Vaihingen数据集相似的类别。
为了评估我们所提出的模型,我们使用三个评估指标来评估语义分割的性能,包括平均交叉合并区间(MIoU)、平均F1分数(AF)和整体准确度(OA)。
2.3.2 实施细节
考虑到实际中很多遥感数据集都没有DSMs,我们在实验中没有使用这些数据集,因为它们具有广泛的应用价值。对于ISPRS Vaihingen数据集,我们将标记数据集分为两部分,其中(ID 30、32、34、37)用于评估网络性能,其余12幅图像用于训练。由于Vaihingen数据集的数量较少,为了防止过度拟合,我们首先将训练数据集随机裁剪成256×256大小,然后通过旋转和平移操作对数据进行扩展,最后得到12000个patch用于训练。Potsdam数据集也分为两部分,其中(ID 2_12、3_12、4_12、5_12、6_12、7_12)用于测试,其余18幅图像用于训练。之后,我们随机裁剪得到27000个256×256的patch用于训练。
我们从头开始训练所有的模型,没有任何附加的功能。包括FCN-32s、FCN-8s、Unet、SegNet、G-FRNet等型号均采用VGG-16作为框架。对于RefineNet和DeepLabv3+,采用ResNet50为主干,RefineNet降采样32次,DeepLabv3+采用8次下采样作为原稿。我们还采用ResNet50作为主干,对CBAM进行了8次的降采样。为了训练所提出的SCAttNet V1,我们将Vaihingen和Potsdam数据集上的SCAttNet V1的学习速率分别设置为1e-3和1e-4。为了训练SCAttNet V2,我们将两个数据集上的SCAttNet V2的学习速率设置为1e-3。模型均采用Adam作为优化器,交叉熵作为损失函数。训练期设置为50。考虑到计算资源有限,批大小设置为16。为了测试以上的所有模型,我们只使用一个不重叠的滑动窗口来裁剪图像,然后缝合在一起。我们在Tensorflow平台上,用NVIDIA 1080Ti GPU进行了所有实验。
2.3.3 Vaihingen数据集上的结果
表1记录了ISPRS Vaihingen数据集的语义分割。我们采用[23][24]的做法,不报告杂波/背景类的准确性,因为Vaihingen数据集有较少的杂波/背景。从表1的实验结果可以看出,通过信道注意模块,MIoU、AF、OA较原始SegNet增加了1.4%、1.25%、0.56%。这说明信道注意模块捕获有意义语义信息的有效性;在空间注意模块的帮助下,汽车等小物体的IoU、 f1得分提高了3.08%、3.21%。这说明空间注意模块在原始图像小目标为32倍下采样的情况下,仍能聚合更多的位置信息。虽然不透水表面、建筑物和树木类的精度略有下降,但将通道细化特征输入空间注意模块后,MIoU、AF仍比原始SegNet增加了2.9%、2.59%。此外,在SCAttNet V2中,MIoU、AF、OA较基线模型ResNet50增加1.21%、0.83%、0.90%。此外,我们发现在FCN-32s中,carcategory的准确率较低,但是FCN-8s中的carcategory相比FCN-32s有了很大的提高,这说明了低层特征对于小目标分割的重要性。
为了比较语义分割结果,我们对ID32的语义分割结果进行可视化。可视化结果如图2第一行所示。我们可以看到,我们的SCAttNet V1比原始的SegNet模型获得了更多的相干结果。此外,我们的模型可以更准确地推断出小的目标区域,比如图像中间的汽车。我们还测试了ID32区域的准确性。SegNet的MIoU、AF、OA为60.57%、74.01%、82.78%,而我们的SCAttNet V1的为64.92%、77.74%、85.49%。在此基础上,我们的网络可以通过有效地加入注意模块来提高语义分割的准确率。

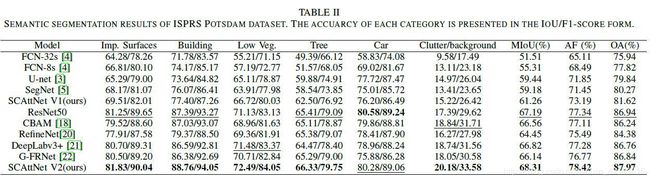

2.3.4 Potsdam数据集上的结果
表II记录了ISPRS Potsdam数据集的语义分割结果。从语义分割结果来看,提出的SCAttNet V2模型优于比较模型。此外,它在MIoU、AF、OA指标上比ResNet50作为基准模型高出1.12%、1.08%、1.03%。在SCAttNet V1中,MIoU、AF、OA与作为基准模型的SegNet相比分别增加了2.08%、1.74%和1.35%。从而进一步验证了注意模块的有效性。
图2的第二行是ISPRS Potsdam数据集ID 5_12区域的可视化结果。与比较模型相比,我们提出的网络在建筑区域取得了较好的分割效果,特别是在避免背景干扰方面。我们还测试了语义分割的性能。SegNet网络的MIoU、AF、OA为57.19%、68.87%、83.81%,而SCAttNet V1网络的MIoU、AF、OA为59.50%、71.16%、85.04%。我们发现,与比较模型相比,我们的网络在所有三个指标上都达到了更高的精度。
2.3.5 改进的可解释性的定量分析
为了分析注意力模块对网络的增强,我们在ISPRS Vaihingen数据集上可视化了SegNet网络和SCAttNet V1网络的特征表达。我们可以简单地覆盖在SoftMax操作之前的网络热图与原始图像,相关的区域可以突出一个特定的类别。可视化结果如图3所示。在加入注意模块后,我们的网络可以聚焦于较好地目标和抑制了其他类别的影响。如图3第一列所示,在加入attention模块后,我们的网络只在汽车类中有较强的响应,而其他区域都是冷色调,这意味着其他区域的相关性很低。然而,在原有的SegNet网络中,不透水区域也表现出一定的响应,可能会对car类产生干扰。此外,如图3第三列的建筑类别所示,在加入attention模块后,不透水表面积被抑制。这样,不透水表面积就避免归入建筑类。

2.4 结论
在本研究中,我们提出了一种新的基于注意模块的语义分割网络,可以自适应地细化特征。在ISPRS Vaihingen和Potsdam数据集上的实验证明了该方法的有效性。然而,仍然存在一些缺点。这项研究只使用了两个常见的注意模块。因此,如何有效地设计注意模块,捕捉更多的语义推理特征是未来研究的一个方向。
三、总结
1、提出了一种新的基于空间和通道注意的语义分割网络SCAttNet,网络集成了轻量级的空间和通道注意模块,能够自适应地细化特征。
2、将空间和通道注意模块学习到的特征形象化,以解释为什么我们的方法有效。
3、在Vaihingen和Potsdam数据集上的实验表明,通过空间和通道注意模块来学习HRRSIs的特征,在小目标上获得的结果得到了显著性提升。