基于制表位停止检测的页面布局分析方法_TesseractOCR内置
基于制表位的混合页面版面分析技术:
摘要:提出了一种新的混合页面布局分析算法,该算法使用自底向上的方法形成初始数据类型假设,并定位页面格式化时使用的制表符。检测到的制表符停止符用于推断页面的列布局。然后以自顶向下的方式应用列布局,对检测到的区域施加结构和读取顺序。完整的c++源代码实现可以在http://code.google.com/p/tesseract-ocr上作为Tesseract开源OCR引擎的一部分获得。
物理页面布局分析是OCR的第一步之一,它将图像划分为文本和非文本区域,并将多列文本划分为列。本文不讨论逻辑布局分析,这种分析可以检测文章的页眉、页脚、正文文本、编号列表和分段。物理布局分析对于使OCR引擎能够处理任意页面的图像是必不可少的,例如书籍、杂志、期刊、报纸、信件和报告。物理布局分析方法大致分为两类:
自底向上方法是最古老的[1]方法和最近发布的[2,3]方法。它们对图像的小部分(像素、像素组或连接的组件)进行分类,并像类型一样聚集在一起形成区域。自底向上方法的关键优势在于,它们可以轻松处理任意形状的区域。关键的缺点是它们很难考虑到图像中的高级结构,比如列。这通常会导致区域过度碎片化。
自顶向下方法[4]在垂直和水平方向沿空白区域递归地切割图像,这些空白区域被认为是列边界或段边界。尽管自顶向下方法具有这样的优势,即通过从页面上最大的结构开始查看,但他们无法处理许多杂志页面中出现的各种格式,例如非矩形区域和无缝地融合在下面的列中的跨列标题
第三种方法[5-7]是基于分析图像中的空白。这解决了递归自顶向下方法中的一些缺陷,通过自底向上的间隙分析找到列之间的间隙,显式地寻找白色矩形。这些算法大多仍然存在无法处理非矩形区域的问题。
当一个页面由专业的出版系统或普通的字处理程序布局时,页面的区域由制表符tap-stops限定。表的页边、列边、缩进和列都放置在固定的x位置上,在这个位置,文本行的边缘或中心是垂直对齐的。制表符-stops将表格与正文文本区分开来,它们还可以绑定矩形的非列元素,例如插入图像和拉出引号。
图1示例中的制表符-stop是列边界,带有用于段落缩进的附加制表符,而段落缩进不是查找页面布局所必需的。非矩形嵌入图像通常会偏离列边界。

在某种意义上,白色矩形与制表符匹配,但白色矩形可能会被背景噪声或背景图像打乱。此外,白色矩形的端点与制表符限定的区域的端点不匹配,因为白色矩形延伸到垂直的空白区域。
所提出的算法类似于空白矩形方法,因为它使用自底向上的方法来查找自顶向下的结构,但它不是查找列之间的空间,而是查找标记其边缘的制表符,并且通过进一步组合自底向上和自顶向下的方法,可以轻松处理非矩形区域。
主要阶段有:预处理,在预处理中,自下而上的形态和连接成分分析在局部数据类型上形成初始假设;自底向上的制表符stop检测;查找列的布局;最后应用列布局来创建有序的类型化区域集。这些阶段将在第3-6节中详细介绍。
3、预处理
预处理步骤的目的是识别行分隔符,图像区域,并将剩余的连接组件分离为可能的文本组件和较小数量的其他不确定的类型。
从图1的图像开始,Leptonica[8]的形态学处理检测出图2(a)所示的垂直线和图2(b)所示的图像掩码(image mask)。在将清洗后的图像传递给连接的组件分析之前,从输入图像中减去这些检测到的元素。
根据宽度、w和高度、h,连接组件(connected components, ccs)被过滤成小、中、大尺寸,如下:

这种过滤很重要,因为小的ccs(噪声或变音符)和大的非文本ccs(线条图、logo或框架)可能会混淆文本行算法,但大的文本标题对阅读顺序检测也很重要。在这个阶段,如果左邻或右邻具有相似的笔画宽度(stroke width),那么大的ccs被认为是文本。在“stressed”字体上,垂直线上的笔画宽度比水平线上的笔画宽度大,因此在两个方向上分别计算笔画宽度。笔划宽度是根据CC的二值图像上距离函数的水平和垂直局部最大值计算的。如图3所示,CCs被过滤为中型或大型文本。


4、寻找制表符位置作为分割线
查找制表符线段的过程有几个主要的子步骤:找到看起来可能位于文本区域边缘的候选制表符ccs,然后将它们分组到制表符行中,然后找到制表符行之间的连接,从而消除误判。
4/1 找到候选制表符组件
通过从预处理的每个已过滤的CC开始进行径向搜索,以找到初始候选制表符停止CCs。假设CC位于制表位,搜索将在应该有空间的沟槽中寻找对齐的邻居和邻居。每个CC都是独立处理的,并根据它是候选左选项卡、右选项卡还是都不是进行标记。图4(a)说明了候选制表符停止ccs。

4.2 分组候选制表组件
候选选项卡cc被分组成行,如果一个组中有足够多的ccs,则保留它们。最小平方中值算法用于将一行拟合到组中每个CC的适当(左或右)边缘。在找到所有制表符停止线段后,所有的线都被重新调整到页均值方向,使所有的成员制表ccs落在线段的一侧。
4.3 跟踪文本行以连接制表符
下一步通过跟踪从一个制表符到另一个制表符的文本行来连接制表符。紧密相邻,垂直重叠的ccs符合条件,但不能跳过较大的间隙。有文本行连接的制表符停止符彼此关联,就像文本列的两端一样。图4(b)显示了制表符行以及连接的文本行。没有连接的制表符行将被丢弃。
记录连接制表位的文本行最常出现的宽度,以便在查找列布局时使用。
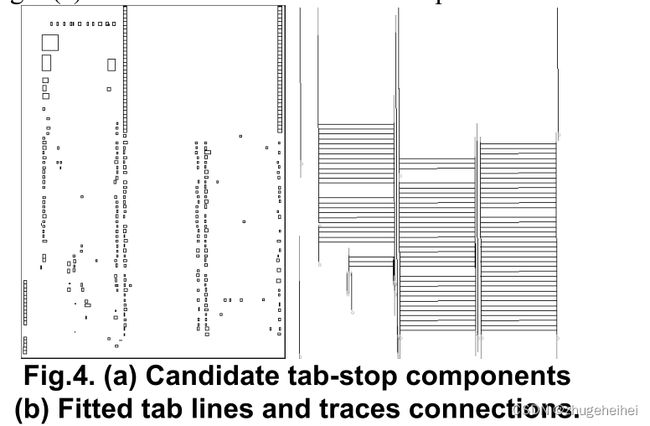
4.4 清理制表位结束
最后一步尝试使连接的制表线在相同的y坐标处结束,方法是允许末端在制表线边缘使用的最后一个成员CC和该线相交的第一个非成员CC之间移动。图5显示了最终的制表线段分割结果。

在构建制表位之后,ccs将被重新分类,使用与上面用于查找制表位stop之间连接相同的文本行跟踪算法,将其分类为“Text”或“Unknown”。如果一组具有显著宽度的ccs组成一个文本行,则将它们分类为文本。从形态学预处理的图像掩模中创建与体-文本CCd大小相同的人工图像ccs。
5、找到列布局
下一个主要步骤是找到页面的列布局。其余所有步骤都将使用现在创建的列分区/分割(CP)对象。从左到右、从上到下扫描ccs,将分类相似(文本、图像或未知)的ccs收集到CPs中,约束是没有CP可以越过制表符行。图6显示了该过程的结果。来自单个水平扫描的CPs集合存储在列分区集(Column Partition Set, CPset)中。

每个CPset都可能是在该垂直位置将页面划分为列。因此,寻找列布局是一个寻找最优cpset集的过程,它最好地“解释”(见下文)页面上的所有cpset,但首先给出一些定义:
一个好的CP要么在它的包围框的两个垂直边缘上接触制表行,要么它的宽度接近一个经常出现的宽度。(参见4.3)。
CPset的覆盖范围是它包含的所有好的CPs的总宽度。
CPset A优于CPset B,如果A有更大的覆盖率,或相同的覆盖率,但有更多的好CPs,或相同的好CPs,但有更多的总CPs。
CPset A解释了set B,除非下列一个或多个为真:
1. B的一个CPs的边缘在所有A的CPs之外。这是不允许的,因为这表明B的文本比A多。2. B的一个CP的边落在A的不同CP上,B CP的宽度是一个共同的CP。这意味着A分割了一个公共宽度的列。3.B的其中一个CP的右边缘与下一个B CP的左边缘位于相同的A CP中,并且B CP的宽度大致相同。看起来A和B的列数不同。相同宽度的条件允许A用拉出来解释B。4. B的两个CP的两条边都落在A的同一个CP上。这意味着A合并了B的两列。
注意,B的一个CPs的两条边允许落入A的两个CPs,只要宽度不是公共的。这允许合并B中的列的标题由A解释。
从页面上的cpset集合中生成一个候选列列表,将最佳列排在前面,并通过上面的A解释B规则消除重复项。在此过程中,将忽略所有图像CPs。
在创建初始候选对象之后,通过添加新的CPs和扩大现有CPs来改进它们,方法是在不同CPSet中使用CP的边缘,同时扩大不会导致CP重叠。
然后,迭代过程标记由候选列之一解释的连续页面的最长段(允许非常小的故障区域)y坐标。图7显示了该过程的结果。

6、发现区域
在找到列之后,根据CPs所跨越的列的数量为其指定类型。单个列中的CPs是流动的(flowing),涉及多个列但不跨越任何一个列的外边缘的分区是拉出的(pull-out),完全跨越多个列的分区是标题的(heading)。
6.1 创建CPs流
每个CP选择其最佳匹配的上下伙伴,即水平重叠的垂直方向上最近的CP。由于每个CP将自己注册到其选择的合作伙伴,因此每个CP可以有零个或多个注册的上、下合作伙伴。
注册合伙人列表的大小被强制为0或上下各为1,使用以下规则:
1. 类型。如果有多种类型,文本只能使用自己的(确切的)类型,而图像可以使用任何其他图像类型。
2. 可传递的伙伴快捷方式被破坏了。如果A有两个伙伴B和C, B也有C作为同一方向的伙伴,那么删除C作为A的伙伴,留下一个干净的A-B-C链。同样,如果A有一个伙伴B, B也有一个方向相同的伙伴A,打破这个循环。
3.(仅限文本)如果A仍然有两个伙伴B, C,跟踪B和C的伙伴,看谁的链最长。
从A中删除链最短的伙伴,并将最短链的类型转换为pull-out。
4. (仅供图片)选择水平重叠最大的伙伴CP。
所有CPs现在都有0或1个伙伴。即便如此,(重新)运行上面的规则1。这将所有文本链净化为单一类型,并将文本链从图像链中分离出来。通过将链中的所有CPs设置为链中最一般的类型,可以净化图像链。图8显示了最终输入的CPs,其中流动文本为蓝色,标题文本为青色,标题图像为品红,拉出图像为橙色。

文本CPs链被进一步划分为统一行间距的组,这些组构成文本块。现在,每个CPs链代表一个候选区域,但是这些区域必须是有序的。
6.2 读取顺序的确定
回想一下,图像和文本分区有三种类型:流动、拉出和标题。此外,页面被划分为一致的列布局的部分。有了这些信息,合理的阅读顺序就包含了几个简单的规则:
1. 流动的块后面跟着列中的y位置。
2. 拉出块之后,在它们接触的实列之间的虚列中y的位置。
3.标题跨越多个列,并跟随在所跨越的列中或列之间高于它的任何内容。位于标题下面同一列中的任何内容都在标题之后。
4. 列布局的改变就像标题一样。
任何已更改列中的任何内容(或它们之间的任何内容)都放在新列中的任何内容之前。
未更改的列不受列布局更改的影响。
5. 在标题之间,列的内容从左到右排序
6.3 找出每个区域的多边形边界
为了实现简单,区域多边形是等线的:即边缘在水平和平行于平均制表线之间交替(大约垂直)。多边形边的选择是为了使顶点数量最小化,同时满足所有的CPs都包含在其区域多边形内,并且没有来自其他区域的CP相交的约束。图9显示了为图1的输入图像创建的最终块。

7、测试和结果
本文描述的算法是用c++实现的,源代码可作为Tesseract开源OCR系统的一部分[9,10]。它在3.4 GHz的奔腾4上运行一个典型的8MPixel图像,大约1秒。
正确地测试页面布局分析是一个困难的问题[11],因为对于复杂的杂志页面,公开可用的集很少。除非在所有正文文本之后放置了图标题,否则UNLV测试集[12]只测量文本区域,并计算数数错误。
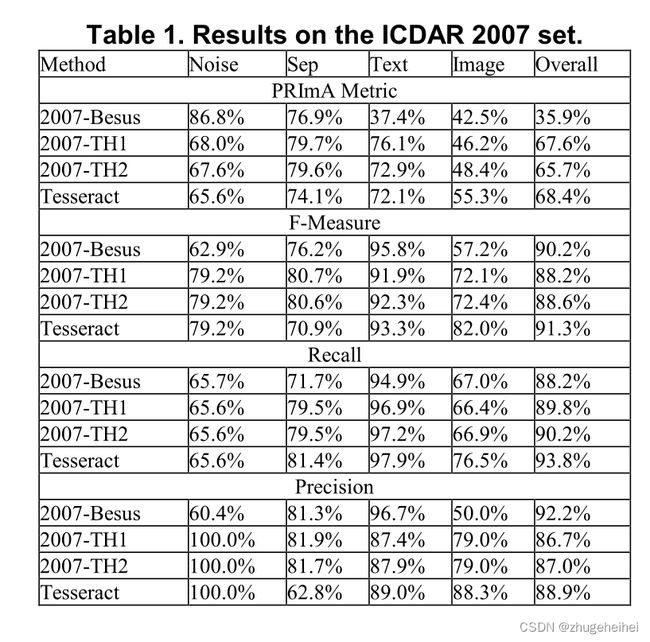
ICDAR页面布局分析比赛提供了更好的整体精度测量,该算法的结果出现在2009年的比赛[13]。图10显示了一些图形结果,表1显示了与ICDAR 2007竞赛参赛者的数值比较。
表1中的结果仅在2007年测试集上计算,作者要感谢Apostolos Antonocopoulos提供了这些结果。关于测试方法的详细信息,请参见参考文献[11]和[13]。

10、结论展望
制表符是一种有趣且有用的替代白色矩形来寻扎页面列结构的方法。
将自顶向下的列结构概念与自底向上的分类方法相结合,使页面布局分析能够轻松处理现代杂志页面上复杂的非矩形布局,而不会丢掉“大图片”,而这在单独使用自下而上的方法时经常发生。所描述的算法没有表检测或分析,但是制表符停止对两者都非常有用,因此将来将添加表分析。
VS