paqu动态网页使用selenium被反pa(1)
目标:是为了得到,该网站的免費圖庫相片 · Pexels所有图片,并分别对应保存到单独的文件夹中,其中获取得到对应的图片的标签信息以txt文件对应保存到文件中。以0,1,2,3,4.......顺序保存。 爬的网站为:https://www.pexels.com/zh-tw/
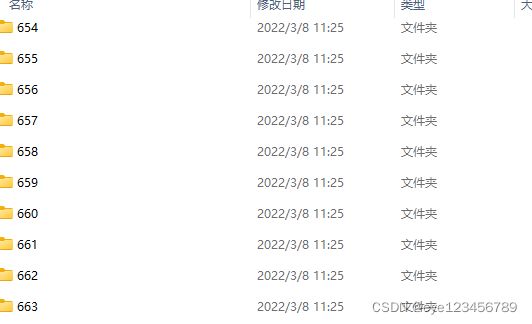
效果展示:
:
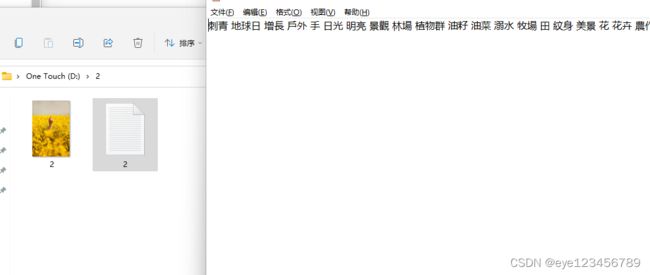
而这次的结果只是一个半成品,原因很简单,设置的
driver.execute_script("scroll(0,100000)") 这个100000的参数依旧不够浏览器滑到最底部,因为在自动加载的页面那里是可以继续尽心手动加载的。发现这个还是因为后面发现滚动条始终会停留在同一个地方,两次爬取完的图片数量是一致的。这就导致了这一次的爬取还是一个半成品,并没有实现爬取全部的图。
解决方案会在下一节记录。
过程记录:
首先想到的方法就是使用requests.get最常用的这个方法,来获取数据,然而直接面临
response.status_code的状态码是403,就此就应该考虑到这个网页是由反爬的设定的,常用方法加上hesders ,cookie,但是依旧是不能够访问的,(正常访问的状态码应该是200),在这个时候并没有想到要用selenium模拟浏览器解决反爬。而是在一个知乎上面看到了别人类似的情况用的selenium来处理动态网页的。因为动态网页一般都是用js,ajax进行加密的。
安装selenium和不同浏览器对应的chromedriver,网上有很多对这个的安装教程。需要一提的是:、chromedriver是对应的谷歌浏览器,而微软浏览器对应的应该是edgedriver。两者版本要对应下载,解压过后放在anaconda的scripts文件夹下,并且要进行环境变量的配置。参考链接:WIN10 python使用selenium调用Microsoft Edge浏览器_linstwo的博客-CSDN博客https://blog.csdn.net/linstwo/article/details/120049241
整个代码流程:
1.访问网页。使用selenium模拟浏览器打开网站,并实现将网站的滚动条拉至最底部,从而获取网页的全部element代码(而非ctrl+u看到的网页源代码)。其中此部分需要用到selenium的反反爬,(在做的过程中,就发现滚动条倒拉到了当前页面的最底部(我猜测就是网页源代码的最底部),但是不能够继续加载后面的,真正的网页最底部根本看不到!!后面查阅资料说,跟网页屏蔽selenium有关(也就是网页反selenium爬)
实现selenium不被反爬的代码:
#设置参数 excludeSwitches,达到selenium不被反爬(在这个地方卡了好久)
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
option.add_argument("--disable-blink-features")
option.add_argument("--disable-blink-features=AutomationControlled")
driver=webdriver.Chrome(options=option)#实例化一个初始浏览器
url='https://www.pexels.com/zh-tw/'
driver.get(url)
driver.maximize_window()
driver.implicitly_wait(30)实现滚动条拉至网页最底部:
# 将滚动条下拉至最低,才能得到全部的element代码!!!
#js = "var q=document.documentElement.scrollTop=10000"
#driver.execute_script(js)
all_window_height = [] # 创建一个列表,用于记录每一次拖动滚动条后页面的最大高度
all_window_height.append(driver.execute_script("return document.body.scrollHeight;")) #当前页面的最大高度加入列表
while True:
driver.execute_script("scroll(0,100000)") # 执行拖动滚动条操作
time.sleep(3)
check_height = driver.execute_script("return document.body.scrollHeight;")
if check_height == all_window_height[-1]: #判断拖动滚动条后的最大高度与上一次的最大高度的大小,相等表明到了最底部
break
else:
all_window_height.append(check_height) #如果不想等,将当前页面最大高度加入列表。2.获取全部的element代码。
一定要脑袋清醒,动态页面都是经过js处理的,所以要获得全部的某一部分的动态加载的数据,一定是在element当中存在,而不是在ctrl+u中存在。所以前面才会模仿浏览器将滚动条拉至最底部,这样才能获取到全部的网页代码。使用driver.page_source
3.解析数据。
driver.enconding='UTF-8'
soup=BeautifulSoup(driver.page_source,'html.parser')#得到全部的element代码
body=soup.find('div',attrs={'class':'l-container home-page'})
body=body.find('div',attrs={'class':'photos'})4.保存数据。
该部分的代码:
count=0
path='D:/'
f = open('D:/photos_related_tags.txt', 'w')
for column in body.find_all('div',attrs={'class':'photos__column'}):
for img in column.find_all('a',attrs={'class':'js-photo-link photo-item__link'}):
img_label=img.find('img')
img_url=img_label.attrs['data-big-src']#这个的使用很奇妙,值得多参考
print(img_url)
pattern = re.compile(r'\d+')
img_id=pattern.findall(img_url)[0]
txt_url='https://www.pexels.com/zh-tw/photo/'+img_id
f.write(txt_url)
f.write('\n')
image=requests.get(img_url)
byte=image.content
if os.path.isdir(path + str(count)):
pass
else:
os.mkdir(path + str(count))
document_path=path + str(count)
pic_path=document_path + '/'+str(count) + '.jpg'#这里用了‘/’来构成路径
fp = open(pic_path,'wb')
fp.write(byte)
fp.close()
count+=1
f.close()
print('爬取图片总数:',count)有关第一次使用的技巧:
a.在路径当中,为了实现顺序递增的文件夹名称,使用了在路径当中传参数
os.mkdir(path + str(count))b.为了实现在对应的文件夹下,写入.jpg,目标就是在文件夹的路径之下再保存一个.jpg,而这个.jpg的命名又要与文件夹同名(且是递增的)
document_path=path + str(count)
pic_path=document_path + '/'+str(count) + '.jpg'c.为了得到标签网站的url,从规律上可得出,图片对应的标签网站就是'https://www.pexels.com/zh-tw/photo/'+img_id
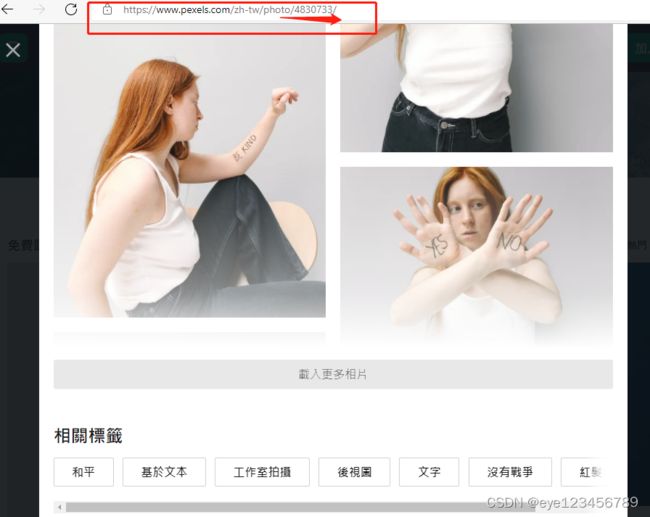
所以要相方设法地得到img的id,而在得到的图片网址中都存在img的id,此处就需要应用到正则表达式来提取字符串中的数字
pattern = re.compile(r'\d+')
img_id=pattern.findall(img_url)[0]
txt_url='https://www.pexels.com/zh-tw/photo/'+img_id*****实现获取并保存所有图片的完整源代码********:
将爬取的图片单独保存在一个文件夹中,将所有的图片的对应的标签网站路径保存在
D:/photos_related_tags.txt'这个文本文档里面,方便后面获取这些标签网站里面对应的标签。
import os
import time
import requests
import json
import lxml
from bs4 import BeautifulSoup
import random
import urllib3
import re
import selenium
'''
#单张下载
url='https://images.pexels.com/photos/10171227/pexels-photo-10171227.jpeg?auto=compress&' # 标签 data-big-src
response=requests.get(url)
byte=response.content
f=open('photo.jpg','wb')
f.write(byte)
time.sleep(0.5)
'''
'''
#json格式数据当中的下载路径可以用 photoModalImageDownloadLink:
#验证实验部分
url='https://cn.bing.com/images/search?q=%e7%99%be%e5%ba%a6%e5%9b%be%e7%89%87&qpvt=%e7%99%be%e5%ba%a6%e5%9b%be%e7%89%87&form=IGRE&first=1&tsc=ImageBasicHove'
headers={'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 Edg/98.0.1108.62',
'cookie':'MMCA=ID=2029A8CC7A5B4B8FA6A034B6B228AE2F; MUID=1B55153F4A386CA43DF904634E386D3E; SRCHD=AF=NOFORM; SRCHUID=V=2&GUID=0F880C884790422D8191152C95777019&dmnchg=1; MUIDB=1B55153F4A386CA43DF904634E386D3E; MUIDV=NU=1; SUID=M; ABDEF=V=13&ABDV=11&MRNB=1646366080559&MRB=0; _SS=SID=3A5B0CC3EB0662E530D81D9EEA60631A&PC=U531; SRCHS=PC=U531; ipv6=hit=1646382288083&t=4; SRCHUSR=DOB=20220303&T=1646380565000; _EDGE_S=SID=09339E81541F6B442A628FDC55796A83&ui=zh-cn; SNRHOP=I=&TS=; SRCHHPGUSR=SRCHLANG=zh-Hans&BZA=1&BRW=S&BRH=M&CW=1177&CH=944&SW=1920&SH=1080&DPR=1&UTC=480&DM=0&EXLTT=31&HV=1646381921&WTS=63781977365'}
response=requests.get(url,headers=headers)
print(response.status_code)
soup=BeautifulSoup(response.content,'lxml')
print(soup)
#踩了一个大坑,之前以为获取到的代码与element不一样,是由于动态网页的缘故,实际上根本就没有获取到信息,网页反爬虫,访问不到
#已经通过百度图片网站验证了,普通的用request.get获取到的动态网页代码只是 ctrl+u得到的未经过js加工的代码(即是一层不变的,可以理解为去掉javascript之后的代码),而我们通过element查看到的代码是动态变化的,往往我们需要获取的信息也是这部分
'''
'''
from selenium import webdriver
driver =webdriver.Chrome()
if __name__=='main':
driver.get('http://www.baidu.com/')
'''
from selenium import webdriver#selenium可以模拟浏览器,可以解决反爬,之前直接使用requests.get请求是403(访问不了)
from bs4 import BeautifulSoup
import requests
from lxml import etree
#踩坑记录:前两天一直报错,就是因为网页是反爬的,后面使用了selenium解决了
#使用不同的浏览器记载同一个网站,可能会出现一个加载很快,一个加载不动的情况(今天就在这里踩坑了,使用webdriver.Chrome()选用的是谷歌浏览器,加载的时候就基本不动,而webdriver.Chrome()加载网站的时候就很快
#又一次发现失败,原来不是因为浏览器的原因,而是因为现在的网站在页面渲染之前就已经对webdriver的属性进行检测了,正常情况这个属性应该是undefined,而我们一旦使用了selenium这个属性就被置为true
import time
from selenium.webdriver.chrome.options import Options
from selenium.webdriver import ChromeOptions
import os
#设置参数 excludeSwitches达到selenium被反爬(在这个地方卡了好久)
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
option.add_argument("--disable-blink-features")
option.add_argument("--disable-blink-features=AutomationControlled")
driver=webdriver.Chrome(options=option)#实例化一个初始浏览器
url='https://www.pexels.com/zh-tw/'
driver.get(url)
driver.maximize_window()
driver.implicitly_wait(30)
# 将滚动条下拉至最低,才能得到全部的element代码!!!
#js = "var q=document.documentElement.scrollTop=10000"
#driver.execute_script(js)
all_window_height = [] # 创建一个列表,用于记录每一次拖动滚动条后页面的最大高度
all_window_height.append(driver.execute_script("return document.body.scrollHeight;")) #当前页面的最大高度加入列表
while True:
driver.execute_script("scroll(0,100000)") # 执行拖动滚动条操作
time.sleep(3)
check_height = driver.execute_script("return document.body.scrollHeight;")
if check_height == all_window_height[-1]: #判断拖动滚动条后的最大高度与上一次的最大高度的大小,相等表明到了最底部
break
else:
all_window_height.append(check_height) #如果不想等,将当前页面最大高度加入列表。
#解析数据部分
driver.enconding='UTF-8'
soup=BeautifulSoup(driver.page_source,'html.parser')#得到全部的element代码
body=soup.find('div',attrs={'class':'l-container home-page'})
body=body.find('div',attrs={'class':'photos'})
#保存数据
count=0
path='D:/'
f = open('D:/photos_related_tags.txt', 'w')
for column in body.find_all('div',attrs={'class':'photos__column'}):
for img in column.find_all('a',attrs={'class':'js-photo-link photo-item__link'}):
img_label=img.find('img')
img_url=img_label.attrs['data-big-src']
print(img_url)
pattern = re.compile(r'\d+')
img_id=pattern.findall(img_url)[0]
txt_url='https://www.pexels.com/zh-tw/photo/'+img_id
f.write(txt_url)
f.write('\n')
image=requests.get(img_url)
byte=image.content
if os.path.isdir(path + str(count)):
pass
else:
os.mkdir(path + str(count))
document_path=path + str(count)
pic_path=document_path + '/'+str(count) + '.jpg'#这里用了‘/’来构成路径
fp = open(pic_path,'wb')
fp.write(byte)
fp.close()
count+=1
f.close()
print('爬取图片总数:',count)
单独打开图片标签所在的网页。进行提取标签的代码,生成标签txt,存储在对应文件夹中,此部分完整代码如下:
import os
from selenium import webdriver#selenium可以模拟浏览器,可以解决反爬,之前直接使用requests.get请求是403(访问不了)
from bs4 import BeautifulSoup
import requests
from lxml import etree
#踩坑记录:前两天一直报错,就是因为网页是反爬的,后面使用了selenium解决了
#使用不同的浏览器记载同一个网站,可能会出现一个加载很快,一个加载不动的情况(今天就在这里踩坑了,使用webdriver.Chrome()选用的是谷歌浏览器,加载的时候就基本不动,而webdriver.Chrome()加载网站的时候就很快
#又一次发现失败,原来不是因为浏览器的原因,而是因为现在的网站在页面渲染之前就已经对webdriver的属性进行检测了,正常情况这个属性应该是undefined,而我们一旦使用了selenium这个属性就被置为true
import time
from selenium.webdriver.chrome.options import Options
from selenium.webdriver import ChromeOptions
import os
f_url= open('D:/photos_related_tags', 'r')
count=0
for line in f_url:
# 设置参数 excludeSwitches达到selenium被反爬(在这个地方卡了好久)
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
option.add_argument("--disable-blink-features")
option.add_argument("--disable-blink-features=AutomationControlled")
driver = webdriver.Chrome(options=option) # 实例化一个初始浏览器
#print(line)
url=line
print('****',line)
driver.get(url)
driver.maximize_window()
driver.implicitly_wait(30)
# 将滚动条下拉至最低,才能得到全部的element代码!!!
# js = "var q=document.documentElement.scrollTop=10000"
# driver.execute_script(js)
all_window_height = [] # 创建一个列表,用于记录每一次拖动滚动条后页面的最大高度
all_window_height.append(driver.execute_script("return document.body.scrollHeight;")) # 当前页面的最大高度加入列表
while True:
driver.execute_script("scroll(0,100000)") # 执行拖动滚动条操作
time.sleep(3)
check_height = driver.execute_script("return document.body.scrollHeight;")
if check_height == all_window_height[-1]: # 判断拖动滚动条后的最大高度与上一次的最大高度的大小,相等表明到了最底部
break
else:
all_window_height.append(check_height) # 如果不想等,将当前页面最大高度加入列表。
# 解析数据部分
driver.enconding = 'UTF-8'
soup = BeautifulSoup(driver.page_source, 'html.parser') # 得到全部的element代码
body = soup.find('ul', attrs={'class': 'photo-page__related-tags__container'})
# print(body)
# body1=soup.select('.photo-page__related-tags__container')#使用 soup.select(.类名) 查找到
path='D:/' + str(count)
txt_path = path + '/' + str(count) + '.txt'
f_txt = open(txt_path, 'w')
for info in body.find_all('a', attrs={'class': 'rd__tag'}):
print(info.text)
f_txt.write(info.text)
f_txt.write(" ")
f_txt.close()
count+=1
注释:两个功能是分别用一个.py文件实现的。第一个.py先生成标签信息的网站,保存在一个文本文档,第二个.py用for循环去一个一个依次访问网站,读取网站中的数据,在进行保存。