pyqt5 yolov4实现车牌识别系统
一、pyqt5界面展示: 可支持图片和视频实时检测识别

1.对图片识别效果:
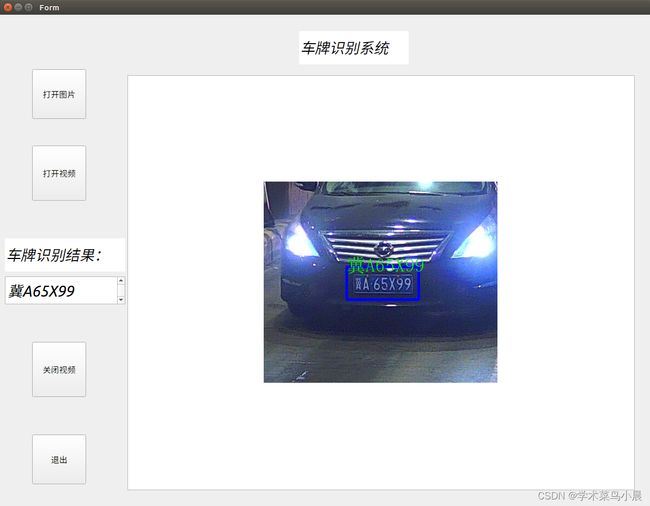

2. 对视频的识别:

二、环境配置
1.安装pyqt5
pip install PyQt52.安装opencv
Ubuntu下opencv4.4 带CUDA的编译安装_学术菜鸟小晨的博客-CSDN博客
3.yolov4的下载和编译(其他检测算法也可)
darknet下yolov4训练自己的数据集及其调参规则快速教程_学术菜鸟小晨的博客-CSDN博客_yolov4调参
三、训练
训练集:标注的是每个字符,我们将其分为70个类,分别为:"plate", "0", "1", "2", "3", "4", "5", "6", "7", "8", "9", "A", "B", "C", "D", "E", "F", "G", "H", "J", "K", "L", "M", "N", "P", "Q", "R", "S", "T", "U", "V", "W", "X", "Y", "Z", "澳","川","鄂","甘","赣","港","贵","桂","黑","沪","吉","冀","津","晋","京","警","辽","鲁","蒙","闽","宁","青","琼","陕","苏","皖","湘","新","学","渝","豫","粤","云","浙","藏"。

将数据集放入下面文件夹中:

通过makeTxt.py
import os
import random
trainval_percent = 0.1
train_percent = 0.9
xmlfilepath = './VOC2008/Annotations'
txtsavepath = './VOC2008/ImageSets'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('./VOC2008/ImageSets/trainval.txt', 'w')
ftest = open('./VOC2008/ImageSets/test.txt', 'w')
ftrain = open('./VOC2008/ImageSets/train.txt', 'w')
fval = open('./VOC2008/ImageSets/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftest.write(name)
else:
fval.write(name)
else:
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()和 voc_label.py
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets=[('2008', 'train'), ('2008', 'test'),('2008', 'val')]
classes = ["plate", "0", "1", "2", "3", "4", "5", "6", "7", "8", "9",
"A", "B", "C", "D", "E", "F", "G", "H", "J", "K", "L",
"M", "N", "P", "Q", "R", "S", "T", "U", "V", "W", "X",
"Y", "Z", "澳","川","鄂","甘","赣","港","贵","桂","黑","沪","吉","冀","津","晋","京","警","辽","鲁","蒙","闽","宁","青","琼","陕","苏","皖","湘","新","学","渝","豫","粤","云","浙","藏"]
#找到英文label名称在list中的位置
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
in_file = open('VOC%s/Annotations/%s.xml'%(year, image_id))
out_file = open('VOC%s/labels/%s.txt'%(year, image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
# difficult = obj.find('difficult').text
cls = obj.find('name').text
# if cls not in classes or int(difficult)==1:
if cls not in classes:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('VOC%s/labels/'%(year)):
os.makedirs('VOC%s/labels/'%(year))
image_ids = open('VOC%s/ImageSets/%s.txt'%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOC%s/JPEGImages/%s.jpg\n'%(wd, year, image_id))
convert_annotation(year, image_id)
list_file.close()
os.system("cat 2008_train.txt 2008_val.txt > train.txt")
#os.system("cat 2008_train.txt 2008_val.txt 2008_test.txt> train.txt")
#os.system("cat 2014_train.txt 2014_val.txt 2012_train.txt 2012_val.txt > train.txt")
#os.system("cat 2007_train.txt 2007_val.txt 2007_test.txt 2012_train.txt 2012_val.txt > train.all.txt")参考上一步3中的训练规则训练,也可以加入自己的数据,优化检测结果。
将训练好的模型放入下面文件夹中