其他模型训练OCT图像分类
目录
1.分类模型比较
2.ResNet:
3.googlenet(InceptionV3):
4.densenet:
4.1裁剪权重:
4.2修改cfg文件:
4.3训练图片:
4.4参考文献:
5.参考文献:
基于深度学习的13种通用图像分类模型及其实现
图像分类(深度模型)总结
迁移学习:残差网络ResNet152(附代码)
GoogleNetv1,ResNet,DenseNet总结
6.附件
附件1:修改后的densenet结构cfg文件:
返回OCT图像分类
1.分类模型比较
darknet分类模型比较

各个网络的具体性能,pytorch官方给出的表格。

darknet分类官网(https://pjreddie.com/darknet/imagenet/)并没有InceptionNet-v3模型,只有ResNet152和DenseNet201.
2.ResNet:
darknet框架基于resnet34模型训练OCT图片
3.googlenet(InceptionV3):
大话CNN经典模型:GoogLeNet(从Inception v1到v4的演进)
动手学深度学习PyTorch版-GoogLeNet代码(PyTorch实现)
Pytorch实现GoogLeNet
4.densenet:
densenet201
4.1裁剪权重:
参考如何训练darknet模型:修改官网已有模型训练自己图片裁剪从官网下载的权重文件densenet201.weights
darknet partial densenet201.cfg backup/densenet201.weights _densenet201.weights 302删除了最后一层权重得到权重文件_densenet201.weights。
4.2修改cfg文件:
参考如何训练darknet模型:修改官网已有模型训练自己图片,对下载的cfg文件densenet201.cfg做如下修改:
batch=16
subdivisions=4因为此处只是分类2种类别,因此最后一个卷积层的filter由原来的1000改为2
[convolutional]
filters=2训练图像张数10000,
maxbatches初始值:
begin = 160 0000
参考迁移学习darknet模型,epoch学习率应该怎么设置,我们知道
epoch=(end-begin)*batch/训练图像张数,
如果epoch设置为100,则maxbatches修改后的值(end)应该=100*10000+160 0000=260 0000
所以,下载的cfg文件densenet201.cfg中maxbatches应该设置为:3000000,这里稍微比100epoch设置一点冗余。
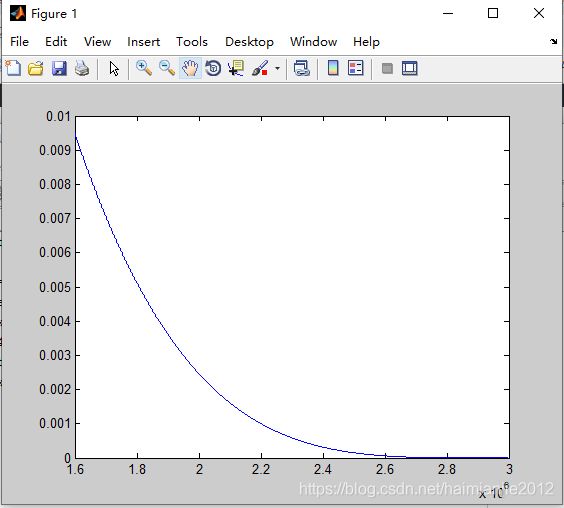
maxbatchs = 3000000设置maxbatches值之后,然后参照darknet分类,迁移学习,还没有达到预期,学习率降为0了,怎么破?,调整学习率,因为学习策略为poly,所以根据函数:
maxbatches = 3000000;
begin = 1600000
rate = 0.2;
x = begin:maxbatches;
y=1-(x/maxbatches);
k=y.^4;
z= rate*k;
plot(x,z)学习率rate设置为0.2,设置后学习率变化图像如下:
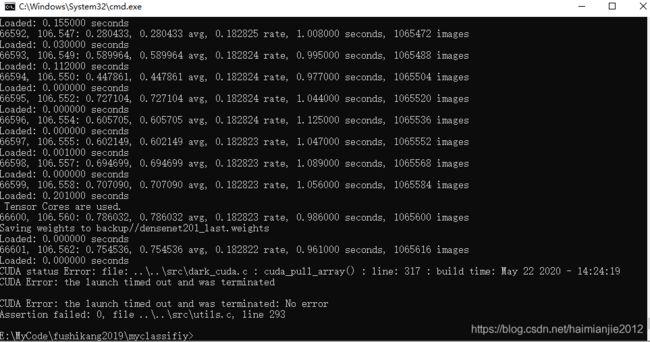
4.3训练图片:
darknet classifier train metal.data densenet201.cfg backup/_densenet201.weights Tensor Cores are used.
66600, 106.560: 0.786032, 0.786032 avg, 0.182823 rate, 0.986000 seconds, 1065600 images
Saving weights to backup//densenet201_last.weights
Loaded: 0.000000 seconds
66601, 106.562: 0.754536, 0.754536 avg, 0.182822 rate, 0.961000 seconds, 1065616 images
Loaded: 0.000000 seconds
CUDA status Error: file: ..\..\src\dark_cuda.c : cuda_pull_array() : line: 317 : build time: May 22 2020 - 14:24:19
CUDA Error: the launch timed out and was terminated
CUDA Error: the launch timed out and was terminated: No error
Assertion failed: 0, file ..\..\src\utils.c, line 293
4.4参考文献:
DenseNet算法详解,DenseNet模型
CVPR 2017最佳论文解读:密集连接卷积网络DenseNet
5.参考文献:
基于深度学习的13种通用图像分类模型及其实现
图像分类(深度模型)总结
迁移学习:残差网络ResNet152(附代码)
GoogleNetv1,ResNet,DenseNet总结
6.附件
附件1:修改后的densenet结构cfg文件:
[net]
# Training
# batch=128
# subdivisions=4
# Testing
# batch=1
# subdivisions=1
batch=16
subdivisions=4
height=256
width=256
max_crop=448
channels=3
momentum=0.9
decay=0.0005
burn_in=1000
learning_rate=0.2
policy=poly
power=4
max_batches=3000000
angle=7
hue=.1
saturation=.75
exposure=.75
aspect=.75
[convolutional]
batch_normalize=1
filters=64
size=7
stride=2
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1,-3
[convolutional]
filters=2
size=1
stride=1
pad=1
activation=linear
[avgpool]
[softmax]
groups=1