用TensorFlow object detection API实战demo
https://blog.csdn.net/c2a2o2/article/details/78436716 TensorFlow内包含了一个强大的物体检测API,我们可以利用这API来训练自己的数据集实现特殊的目标检测。
Dat Tran就分享了自己实现可爱的浣熊检测器的经历,在文章中作者把检测器的训练流程进行了梳理,我们可以举一反三来训练其他在工作项目中需要的检测器。下面我们一起来学习一下吧!
为什么要做这件事?
方便面君不仅可爱,在国外很普遍的与人们平静地生活在一起。处于对它的喜爱和与浣熊为邻的情况,作者选择了它作为检测器的检测对象。完成后可以将摄像安装在房子周围,检测是否有浣熊闯入了你家,你就能及时知道是否来了不速之客了。看来浣熊还真多啊!

创建数据集
机器学习需要数据作为原料,那么我们首先需要做的就是建立起一个可供训练的数据集,同时我们需要利用符合Tensorflow的数据格式来保持这些数据及其标签:
1. Tensorflow的物体检测接口主要使用TFRecord文件格式,我们需要将数据转换为这个格式;
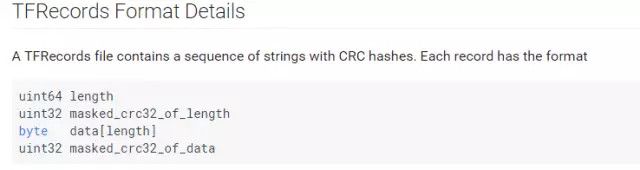
2.有很多工具可以完成数据的转换,无论是类似PASCAL VOC数据集或是Oxford Pet数据集的格式,都有很多成熟的脚本来完成转换,甚至也可以自己写一个脚本来转换,跟着文档解释不会太难;
3.在准备输入数据之前你需要考虑两件事情:其一,你需要一些浣熊的彩色图片;其二,你需要在图中浣熊的位置框坐标(xmin,ymin,xmax,ymax)来定位浣熊的位置并进行分类。对于只检测一种物体来说我们的任务十分简单,只需要定义一类就可以了;
4.哪里去找数据呢?互联网是最大的资源啦。包括各大搜索引擎的图片搜索和图像网站,寻找一些不同尺度、位姿、光照下的图片。作者找了大概两百张的浣熊图片来训练自己的检测器(数据量有点小,但是来练手还是可以的);
 5.有了数据以后我们需要给他们打标签。分类很简单都是浣熊,但是我们需要手动在每一张图中框出浣熊的位置。一个比较好的打标工具是LabelImg。编译好后只要要在图片上轻点鼠标就可以得到PASCAL VOC格式的XML文件,再利用一个脚本就可以转换成Tensorflow需要的输入格式了;有时候在Mac上打开jpeg图像会出现问题,需要将其转换为png来解决;
5.有了数据以后我们需要给他们打标签。分类很简单都是浣熊,但是我们需要手动在每一张图中框出浣熊的位置。一个比较好的打标工具是LabelImg。编译好后只要要在图片上轻点鼠标就可以得到PASCAL VOC格式的XML文件,再利用一个脚本就可以转换成Tensorflow需要的输入格式了;有时候在Mac上打开jpeg图像会出现问题,需要将其转换为png来解决;
6.最后,将图像的标签转换为TFRecord格式后,并将起分为训练集(~160张)和测试集(~40张)就可以开始下一步的工作了!
小提示:
1. 还有很多图像标注工具,包括 FIAT (Fast Image Data Annotation Tool)、BBox-Label-Tool、以及matlab自带的trainingImageLabeler等等,可以根据条件和需要自行选择;
2. 图像格式转换同样也有很多工具,作者推荐了ImageMagick的工具,当然我们还有ps,美图的工具,甚至自己写一个脚本也是一两分钟的事;
3. 整个训练过程中最耗时的就是数据的标注了,作者表示仅仅一类图像200张的排序和打标签就花了他两个多小时的时间,如果需要大量图像的话还是要情人帮忙或者找标注公司,例如CrowdFlower, CrowdAI 和 Amazon’s Mechanical Turk;
4. 对于图像的选择,尽量选择适中的图像,要是太大不仅运算速度慢还会造成内存溢出,需要调节训练批量的大小。
训练模型
输入数据搞定后我们就开始训练模型啦。一般对于物体识别训练来说有标准的工作流程。首先需要利用一个预训练模型来作为训练的基础,作者使用了ssd_mobilenet_v1。同时需要将分类改变为1,并更改模型、训练数据、标签数据的路径。对于学习率、批量大小和其他超参数先用默认参数来进行训练。
随后构建标签映射就可以进行训练了。
 小提示:
小提示:
1. API中有一个数据增强选项data_augmentation_option,这个选项对于较为单一的训练数据来说十分有用。
2. 重要!标签的值需要从1开始标记,0是一个占位符,在为每一类分类标签赋值时需要注意。
做完了这些进一步的准备工作,我们终于可以开始训练了。我们可以选择在自己本地的GPU上训练网络,或者在云服务器上训练。在云服务器上可能需要一额外的配置文件。作者使用Google Cloud就需要一个YAML的文件来定义使用机器的参数。
在训练的过程中,我们可以通过tensorboard 来实时监测模型的训练情况一遍在出现异常时及时调整训练策略。
下图是作者基于24幅图的批量大小进行了一个多小时22k次训练的结果,但在40min左右就出现了很好的收敛结果。
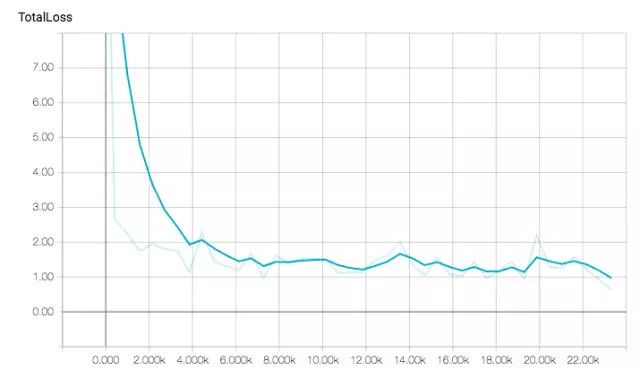 图中显示了loss和精度随训练的变化情况。在预训练模型的帮助下,损失函数下降很快。
图中显示了loss和精度随训练的变化情况。在预训练模型的帮助下,损失函数下降很快。
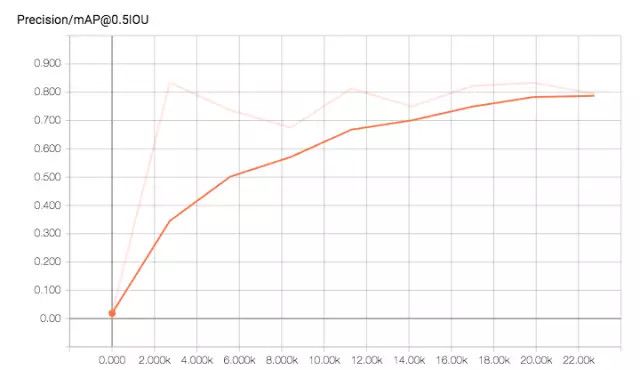 同时作者还将训练过程中模型表现随训练次数的变化呈现了出来:
同时作者还将训练过程中模型表现随训练次数的变化呈现了出来:
在经过测试和轻微的调整之后(实现自己的精度),就可以完成训练了。
模型的使用
完成训练之后我们需要将模型保存下来,通常使用checkpoint的模式来保存。由于我们是基于云端训练的,需要通过一个脚本将模型导入到本机使用。下面是作者将这个模型放到一个youtube浣熊视频中的结果:
浣熊出没

捕捉到浣熊
 看完视频我们会发现有时会出现漏识别和误识别。这主要是因为我们用于训练的数据集太小了,模型缺乏鲁棒性和泛化性,需要更多的数据来提高它的性能,而这也是目前人工智能面临的最大问题。
看完视频我们会发现有时会出现漏识别和误识别。这主要是因为我们用于训练的数据集太小了,模型缺乏鲁棒性和泛化性,需要更多的数据来提高它的性能,而这也是目前人工智能面临的最大问题。
结语
在跟随作者完成物体检测器的训练后,我们应该也可以通过相应的步骤开发自己的检测器。当然需要提高分类器的表现,就需要更多的数据,数据,数据!
这个一检测器训练时间很短而且表现看起来不错。但对于多类物体的的话,表现是会有些许下降的,同时训练时间也要增加才能得到较好的结果。同时我们需要在心中谨记一个原则,最终的模型一定是速度与精度,效率与效果的平衡。深度学习和其他的科学一样都有矛盾与平衡的一面,真正的产品效果其实取决于你倾向天平的哪一方!