Detection of Trust Shilling Attacks in Recommender Systems
摘要 大多数关于检测先令攻击的研究都集中在用户的评分行为上,但没有考虑到攻击者也可能攻击用户的信任行为。例如,攻击者可能会给其他用户的评分打低分,这样人们就会认为用户的评分没有帮助。在本文中,我们定义了信任先令攻击,提出了信任攻击的行为特征,并提出了一种使用机器学习方法的有效检测方法。实验结果表明,基于我们提出的信任攻击行为特征,我们可以准确地检测信任先令攻击以及传统的先令攻击。
1.介绍
推荐系统在信息过滤方面取得了巨大成功,并有效地解决了信息过载问题。但由于对用户历史信息的依赖,部分异常用户利用欺骗手段将攻击用户的信息注入推荐系统,并操纵这些用户模拟正常用户的评分和评论,从而提高或降低推荐系统的推荐频率。目标产品。这种行为被称为“先令攻击”。攻击性行为会干扰推荐系统的正常结果,损害普通用户的根本利益,降低普通用户的推荐体验和推荐质量,从而危及推荐系统的安全性和鲁棒性。
学者们在先令攻击领域进行了研究和探索,尤其是在检测方面。他们在基于分类模型 [2]-[4]、半监督学习算法 [5]-[8]、无监督模型 [9]、[10] 和特征选择[11],[12]。
除了直接给物品打分外,用户还可以给其他用户的打分和评论打分或喜欢/不喜欢。用户对评分的评分或用户对评论的点赞/不喜欢代表了用户对评分/评论的信任。先令攻击者不仅可以直接攻击目标项目,例如直接给予评分,还可以攻击高/低评分。例如,攻击者可能会对普通用户对目标项目的高评分给予低分,或者对用户的低评分和评论给予高分。如果很多用户对某项评论表示不喜欢,则会大大降低收到该项推荐信息的用户的信任度,从而破坏推荐系统的有效性和可信度。
检测基于信任的先令攻击至关重要。我们将这种攻击——对普通用户的高评分给予低分,对普通用户的低评分给予高分——定义为信任先令攻击。然而,很少有研究与基于信任的先令攻击有关。因此,在本文中,我们定义了信任先令攻击,提取了基于可信的特征,并提出了一种机器学习算法来检测信任先令攻击。
本文的其余部分安排如下。sect2、我们定义了信任先令攻击。sect 3,我们介绍我们的方法论,并在 Sect. 4,我们展示了实验结果。第 5 节给出了本文的结论。
2. 信任先令攻击
2.1 信任评级的定义
许多在线网站不仅直接为用户提供项目评级,还提供其他用户评级/评论的评级。其他人的评分/评论的评分揭示了用户在多大程度上信任其他用户的评分/评论。因此,我们将给他人的评分/评论评分定义为信任评分。
2.2 信任先令攻击的定义
我们将以下任何一种情况定义为信任先令攻击:
• 攻击者对普通用户对目标项目的高评分给予低分
• 攻击者对普通用户对目标项目的低评分给予高分
• 攻击者对同伴对目标项目的高/低评分给予高分
• 对竞争对手项目的高/低评分 • 攻击者对普通用户对竞争对手项目的高评分给予低分
• 攻击者对普通用户对竞争对手项目的低评分给予高分竞争对手的物品
• 攻击者对同行对竞争对手物品的高/低评分给予高分
2.3 信任先令攻击的行为特征
• 攻击伪装:对于信任先令攻击,攻击者不仅会攻击目标项目的评分/评论,还会对其他非相关项目(例如热门项目)的评分/评论进行随机/平均评分伪装自己。我们将此特征称为信任先令攻击的伪装。
• 攻击协调:信任先令攻击的协调不仅仅是一个特定的攻击者攻击一个特定的目标,而是一群同谋攻击它。用户通常会给同行的信任评级打高分,以说服其他用户相信他们的信任评级。我们将此特征称为信任先令攻击的协调。
• 攻击同时性:如果普通用户对攻击者想要高分的目标项目给予低分,信任先令攻击者不仅对普通用户的高评分给予高分,而且对普通用户的低评分给予低分。如果普通用户对攻击者想要给低分的目标项目给予高分,信任先令攻击者不仅对普通用户的低分给予高分,而且对普通用户的高分给予低分。当攻击者在执行信任攻击时同时给出高分和低分时,我们将此特征称为信任先令攻击的同时性。
3. 方法
3.1 提取信任攻击特征
• 信任提供者和信任接收者之间的信任相似度(TSGR):在信任社交网络中,用户不仅信任其他用户的评分/评论,还接受他人对自己评分的信任/评论。我们定义 TSGR 来计算用户信任提供者和用户信任接收者之间的相似度。我们认为普通用户的 TSGR 可能不同于信任先令攻击者的 TSGR。攻击者的信任提供者和信任接收者之间的相似性可能高于普通用户,因为攻击者可能比普通用户更频繁地给予和接受信任。在等式。 (1)、TSGRi 是用户 i 在信任提供者和信任接收者之间的信任相似度。 tgi 是用户 i 的信任给予者的数量,tri 是用户 i 的信任接收者的数量,分子是用户 i 的信任给予者和信任接收者的重叠数,分母是信任给予者和信任的并集数用户 i 的接收器。

tgi:自己评价别人的评分
tri:别人对自己评分的评论
• 相关可疑频率 (RSF):此功能描述了用户对可疑项目进行评级的次数。为了评估每个用户的 RSF 值,我们首先提出如何识别可疑物品。攻击者可能会专注于在特定时期内攻击目标项目。在特定时期内,正常项目的评级分布与受攻击(即可疑)项目的评级分布不同。因此,我们使用动态时间规整 [19] 计算每个项目对的相似性以确定可疑项目。我们为每个项目建立了一个二维时间序列 TS,其中 x 是时间戳,y 是当时收到的评分数,如方程式所示。 (2)。 (xn, yc) 表示,对于从 x1 到 xn 的时间序列,项目 i 收到 yc 次的评分。
![]()
其次,为了计算每个项目对 (i, j) 的相似度,我们创建时间序列对 (TSi, TSj)。我们正则化开始于坐标 (1, 1) 并结束于 (|TSi|, |TSj|) 的路径,因此对于路径调节的距离矩阵 D(s, t),我们产生方程。 (3)。

其中 dist(s, t) 表示 |TSi| 中第 s 个点之间的欧几里得距离序列和 |TSj| 中的第 t 个点序列,D(|TSi|, |TSj|) 是项目 i 和 j 的最终正则化路径。 D(|TSi|, |TSj|) 的值越小,项目 i 和 j 的两个时间序列之间的相似度越高。
如果 |TSi| 的长度与 |TSj| 不同,我们使用 k 来表示两个序列的最终拉伸长度,如 Eq. (4)。

由于我们假设一小部分项目是可疑的,而大多数项目是正常的,因此平均距离高的项目将被认为是可疑的。
• 信任行为比率(TBR):普通用户客观地进行信任评级。他们根据自己的真实感受给予信任。然而,信任先令攻击者可能只考虑攻击目标项目,或者给予他们的合作伙伴或与他们具有相同评级的普通用户给予正面信任,或者给予具有不同评级/评论的普通用户消极信任。由于信任先令攻击者的目的和攻击性,攻击者信任行为的正负性与普通用户不同。我们定义正面信任行为比率 (PTBR) 和负面信任行为比率 (NTBR) 来描述这一特征。等式 (5) 说明了我们如何计算用户 u 的 PTBR 值,Nu 是用户 u 信任其他用户的评分/评论的总数,pnu 是用户 u 给予正面信任评分的项目的总数。同样,方程式。 (6) 描述了如何计算用户 u 的 NTBR 值。 nnu 是 u 给出负信任评级的用户总数。

3.2 检测过程
我们通过首先注入不同规模的攻击者并模拟信任先令攻击来验证我们假设的特征是否可以检测到信任先令攻击。然后我们提取假设的特征,TSGR、RSF 和 TBR。最后,利用这些提取的特征,我们应用不同的机器学习模型来检测信任先令攻击,区分信任先令攻击者和普通用户。
4. 实验
4.1 实验数据集和设置
我们使用公共的 CiaoDVD[20] 数据集,因为它有用户-电影评分数据和用户-用户信任数据,可能会受到信任先令攻击。我们使用的数据信息如表 1 所示。信任评级是在用户对电影进行评级后,其他用户对这些评级进行评级。我们通过测试不同大小的信任先令攻击者来验证我们的模式的检测效果。我们分别注入 1%、3% 和 5% 的攻击用户,并使用随机攻击来瞄准物品。在模拟了信任先令攻击后,我们使用 70% 的数据进行训练,使用 30% 的数据进行测试。
最后,我们通过在实验中模拟信任先令攻击、传统先令攻击和混合先令攻击来验证我们提出的方法是否可以检测传统先令攻击。

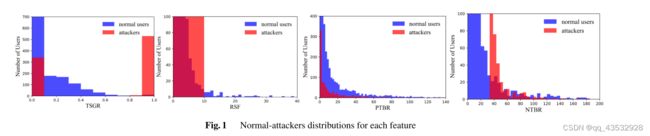
4.2 信任攻击特征分析 我们通过绘制具有每个特征值的正常用户/攻击者分布来评估每个提议的特征的效率,如图 1 所示。我们计算每个特征的每个值有多少正常用户/攻击者。重叠是指一个特征值相同的普通用户/攻击者的数量。我们展示了具有基于信任的特征 TSGR、RSF、PTBR 和 NTPF 的普通用户(蓝色)/攻击者(红色)分布。每个功能都可以提供一个线索,如何识别针对普通用户的攻击者。例如,TSGR 可以通过其值在视觉上区分普通用户和攻击者:攻击具有比普通用户更高的值的趋势。
为了以高精度检测信任先令攻击者,我们使用具有这些提议特征的机器学习模型。
4.3 实验结果
我们使用精度、召回率和 F1 分数作为指标来评估我们的检测算法。表 2 展示了我们在不同学习模型、攻击类型和规模下的实验结果。我们应用 10 折交叉验证来评估我们的模型,将我们的数据集分为 10 折,9 折用于训练,1 折用于测试。我们使用平均 F1 分数来证明我们的方法是可靠的。对于信任先令攻击,我们通过不同的攻击规模和不同的集成模型获得了大约 95% ∼ 98% 的 F1 分数。

我们还使用我们提出的信任攻击特征来检测传统的先令攻击,在不同的实验设置下获得大约 87% ∼ 95% 的平均 F1 分数。
我们还使用我们提出的信任攻击特征来检测传统的先令攻击,在不同的实验设置下获得大约 87% ∼ 95% 的平均 F1 分数。最后,我们对所提出的特征进行了混合攻击试验。 F1 分数低于 trucst 先令攻击,但高于传统先令攻击。我们获得了近 98% 的 F1 分数,攻击规模为 1% 和 3%。对于 5% 的大小,我们获得了 94% 的 F1 分数。此外,我们在相同的实验环境中验证了最先进的方法对传统先令攻击的性能。表 3 总结了结果。对于信任攻击,DSA-AURB [10] 和 FAP [17] 的 F1 分数平均比我们提出的方法低 10% ∼ 20%。对于混合攻击,DSA-AURB 和 FAP 最多获得 70% ∼ 80% F1 分数。
5. 结论
在本文中,我们介绍了信任先令攻击的概念。为了解决这个问题,我们提出了几个信任攻击特征,包括 TSGR、RSF 和 TBR,它们可以用作任意机器学习模型中的输入特征来检测信任先令攻击。我们在 CiaoDVD 数据集上进行了实验。结果表明,我们提出的方法可以有效地检测信任先令攻击以及传统的先令攻击,而之前传统的先令检测方法的性能有限。