深入理解Spark SQL原理
1、前言
本文是对自己阅读Spark SQL源码过程的一个记录,主线是对尚硅谷Spark SQL最后练习中建立的表的一个简单SQL编写的源码实现流程的跟读。通过自问自答的方式,学习完了整个Spark SQL的执行过程。
Spark SQL最终是通过Spark Core的RDD进行计算。所以在阅读Spark SQL源码之前,一定要深刻掌握Spark Core原理,而阅读源码的思路就是理解Spark SQL最后如何生成与Spark Core里同样类型的RDD,进一步如何转换为Job的。
本文从物理计划开始,描述各个结点的实际转换过程,如果你对物理计划的生成还不清楚,可以按照如下的路线进行学习:
- 编译原理里文法、决策树部分,推荐B站哈工大的课程。学习这部分是因为字符串的SQL语句是通过编译的方式生成的语法树,这部分的学习对于语法树生成的各种概念有一个系统性的认识。
- Antlr4。推荐《ANTLR4权威指南 by【英】特恩斯·帕尔》。Antlr4是语法树生成的框架,在被大量Java开源数据分析系统所使用,其内容对于编写一些简单的自定义文法也很有裨益。同时对代码生成的理解也有帮助。
- Catalyst里的逻辑计划优化。这部分参考知乎的一篇博文《是时候学习一定真正的Spark技术》和David Vrba的几篇博文【1】【2】。
- 其他参考。《Spark SQL内核剖析 by 朱锋, 张韶全, 黄明》讲叙的不是很好,但是能建立一个基本的概念。然后就是Jacek的这本《The Internals of Spark SQL》,作为参考资料不错,但是缺乏一个系统的思路。《Spark Definitive Guide》作为应用开发来说是一部绝佳的书籍,对于源码学习没有太大帮助,但是学习的路线肯定是掌握应用开发之后再学习源码。
有了这些基础后,再深入学习Spark SQL源码,难度能够降低很多。以下的内容更多的是对自己学习Spark SQL源码的心得整理,并不适合作为由浅入深的学习资料来看,我按照读者的角度重新整理了一下,如果对你有一点帮助那是再好不过了。
2、Spark SQL UI中的算子名称?
Spark SQL UI是查看Spark SQL运行过程的第一选择,但是从Spark Core过来的用户,会对里面图形的名称感到陌生,即使当你对Spark SQL的执行计划有所认识后,你也会对这些名称、RDD类型和RDD转换算子的关系感到混乱。这部分就是描述这些名称是如何产生的,这样你能够通过UI里的DAG获取更多的内部运算信息。
在Spark UI中对比查看SQL产生的Job和Core产生的Job,SQL产生Job中Stage里的蓝色框(同一个withScope方法内的操作,在withScope内生成的RDD会使用同一个名称)的名称并不和RDD的算子(函数)对应,而直接使用Core框架编写程序产生的Job里的算子名称和RDD的算子(函数)是对应的。这是因为SQL里调用withScope方法,指定了名称(使用的Exec结点的名称,比如BroadcastHashJoin),而Core框架不使用名称,这时withScope会自动查找调用方法,也就算子(比如map),作为Scope名称(也就是蓝色框名称)。当递归调用withScope时,不会覆盖外层的Scope名称。
所以Spark SQL UI蓝色框的名称叫做Scope名称比较合适,称为算子名称并不准确,Scope名称这种说法的缺点就是太抽象了,但能知道它到底从何而来。
3、Spark SQL如何划分Job(也就是如何生成执行RDD算子的Job)?【重点】
后面例子都以:
spark.sql("use atguigu")
val df = spark.sql("""
select city_name, count(1)
from city_info ci, user_visit_action uva
where ci.city_id = uva.city_id and ci.area = '华南'
group by ci.city_name
""")
为例。其中,city_info和user_visit_action见尚硅谷的Spark教程资料。df的执行树如下:

注意,这个最终执行树(executedPlan)是为了学习调试时方便,关闭了codegen后得到的。这时,调用df.show方法,会从SparkPlan树(物理计划)的顶结点执行execute方法,在例子中的顶节点就是HashAggregateExec(后面的描述中SparkPlan结点名称的Exec可能会省略)。execute方法会递归调用子节点的prepare后,再调用当前结点的doExecute方法,doExecute会决定如何调用子结点的方法。当执行到BroadcastHashJoin的doExecute方法时,会对BroadcastExchange执行executeBroadcast方法,然后利用得到的广播变量在Filter上执行execute方法后得到的rdd上进行算子操作得到新的rdd。最后HashAggregateExec的execute方法将返回rdd[InternalRow]。
实际上df.show更直接的调用是HashAggregate的executeTake方法,该方法里将会通过sparkContext的runJob方法提交任务。而在runJob之前,还将会调用execute方法来驱动物理计划树的execute流程。再次强调,通过execute流程,我们得到的只是rdd,但是这个过程也有副作用,比如executeBroadcast也会提交job。
Spark SQL会产生3个Job。第1个是在执行executeBroadcast时,通过[broadcast-exchange]线程提交的。第2个,就是HashAggregate的executeTake里提交的任务。这个Job分成两个Stage,这是由于Exchanger结点导致的(生成ShuffledRowRDD),为什么会出现这个结点在Ensure Requirements规则里描述。第3个Job实际上也是HashAggregate的executeTake里提交的,executeTake执行时先尝试对1个outputPartition进行处理,然后再依据扩大因子的配置增加,这样能够减少对partition不必要的处理,扩大因子的默认值是4,这里只有4个outPartition,所以剩下的3个在Job 3中一次处理了。值得一提的是,第3个Job能重复利用第2个Job产生的中间结果,所以在Job 3中跳过了第一个stage,是不是很神奇和巧妙呢!
4、为什么是4个outPartitioin?
这个是由物理计划决定的,也就是在利用Ensure Requirements生成Exchanger时确定的,不过这里是因为本地运行时设置了spark.sql.shuffle.partitions为4。
5、Ensure Requirements规则?
这是生成物理计划时的一个规则。最终物理计划的生成实际上分为两步,第一步是依据成本规则得到物理计划,对应queryExecution的sparkPlan;第二步是perpareForExecution,这里是对得到的物理计划做执行前准备,保证分区和排序规则能够满足等,而准备中有一个规则就是Ensure Requirements,执行完这些规则后得到executedPlan,这也正是DataFrame的explain方法的输出。
6、对任务数更进一步的理解?
考虑如下的sql:
spark.sql("use atguigu")
val query = spark.sql("""
select uva.user_id, count(*)
from user_visit_action uva, user_visit_action uva2
where uva.user_id = uva2.user_id and uva.city_id > 1 and uva2.city_id < 1000
group by uva.user_id
""")
query.show
query的executedPlan是

这个例子和之前的例子类似,但是运行下来发现不是3个Job,而是2个。而且,第二个Job的最后一个stage只有一个task。事实上,我们看到ExecutedPlan里ShuffleExchangeExec里是设置为4个partition的,难道这个partition还会被其他规则改变?
答案并非如此,事实上,这与之前提到executeTake的实现机制有关,executeTake先对1个outputPartition进行处理,而由于query.show只会显示20行内容,所以1个outputPartition的处理已经能满足需求,后面的就不再执行了。
7、BroadcastExchange的过程?
在executeBroadcast里,通过Expression构造key,形成key-row的map构造出HashedRelation,再通过sparkContext广播出去。
8、BroadcastHashJoin的过程?
从BroadcastExchange得到的broadcast值获取HashedRelation,然后在Filter执行得到的rdd上调用mapPartitions,在分区内进行join操作。
以例子的join作说明操作过程,例子为innerjoin,在innejoin方法里,会遍历Filter的到的Rdd[InternalRow],遍历时计算每一行的key,然后通过key获取HashedRelation的行,如果这个行存在,那么将Filter的InternalRow与HashedRelation里key对应的InternalRow合并返回,完成join操作。
9、HashAggregate的过程?
通过groupingExpression和aggregateExpression来构造TungstenAggregationIterator,当然还有输入行。例子里groupingExpression就是city_name#2,aggregateExpression就是partialCount(1)和count(1)。
聚合迭代器在创建时就进行了聚合操作,next只是返回处理好的值。在TungstenAggregationIterator的类定义里有一个processInputs方法,这个方法在创建对象时就开始处理数据。逻辑很复杂,大致的思路就是利用key为groupingExpression,value为aggregateExpression计算值的hashmap来存结果,还要考虑排序和内存不够写磁盘等逻辑。
Hash的由来就是使用了hashmap,这和HashedRelation的名字由来一样。
10、LocalTableScan结点如何决定Task数量?(与本例子无关)
为什么几行就有几个Task,因为取行数和机器并行度(家里电脑为4核)的最小值。
11、UnsafeRow的结构?【重点】
UnsafeRow是Spark SQL生成的rdd对象泛型参数的具化类型,在源码分析过程中反复出现,弄清其结构对于理解一些复杂的过程很有帮助。
UnsafeRow的格式为:[null bit set] [values] [variable length portion]。
举例[0,0,1800000009,6e61687a6f616978,67]表示[0,xiaozhang]。都是用16进制表示,一个字符代表4个bit,一个“,”表示一个[8-byte word]。第一个[8-byte word] 0表示[null bit set],后面的[8-byte word]依次为field的值(这里有2个field),而第二个[8-byte word]就是0。第三个[8-byte word] 存储的是该field的offset和size,前32bit为offset,后32bit为size,所以0x18就是24是offset值(24字节后就是第二个field的值),9为xiaozhang的长度,而[6e61687a6f616978,67]正是xiaozhang。
12、Broadcast为什么会出现多次?
尚硅谷SparkCore里广播变量例子,会生成两次broadcast块的原因是,task也是通过broadcast传给Executor的。
13、BroadcastJoin和SortMergeJoin不同?
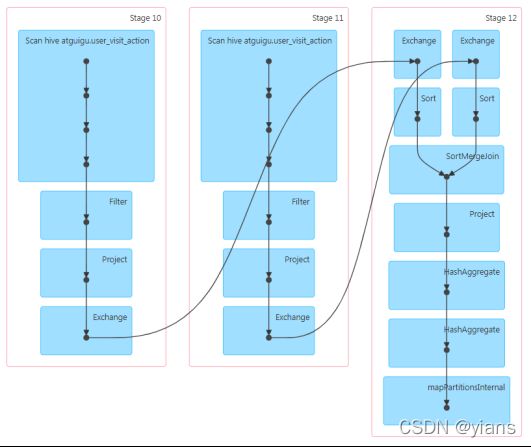
为了构造SortMergeJoin的例子,将一个大表自己与自己Join(不过大表也没超过10M),这时运行速度为40s。于是通过Hint方式指定进行SortMergeJoin,此时分为3个Stage,但都只运行了1个Task,实际Exchange参数为4(应该有4个Task),原因见上面的分析,通过SortMergeJoin在7s内返回了结果,因为show(1)只需要部分执行Stage12的一个Task。例子如下:
spark.sql("""
select /*+ MERGE(uva) */ uva.user_id, count(1)
from user_visit_action uva, user_visit_action uva2
where uva.user_id = uva2.user_id
and uva.city_id > 1 and uva2.city_id < 1000
group by uva.user_id
""").show(1)
包含SortMergeJoin的DAG图如下,为了支持SortMergeJoin,ER要保证上游数据的分区和排序,所以加入了Exchange和Sort节点。这是进行SortMergeJoin的关键前提!好好理解!
14、代码生成的阶段?
同ER,在perpareForExecution时,与ER同在一个seq下的rule:CollapseCodegenStages。对sparkPlan树所有能应用codegen的exec结点,使用WholeStageCodegen结点合并相邻的结点。
15、总结
通过对一个典型的Spark SQL语句进行源码级的理解,我们对于Spark SQL的内部实现流程已经非常清楚,其中,还穿插了一些相关的源码分析。到此为止,对Spark SQL的源码学习告一段落,相信有了更加深厚的内功基础后,再去进行Spark SQL应用的优化、解决使用过程中的问题,必然得心应手!