东京大学&商汤&悉尼大学等提出融合了动态规划、分治算法的MIM,实现绿色高效层次Transformer!已开源!...
关注公众号,发现CV技术之美
本文分享论文『Green Hierarchical Vision Transformer for Masked Image Modeling』,由东京大学&商汤&悉尼大学提出融合了动态规划、分治算法的Masked Image Modeling,实现绿色高效层次Transformer!代码已开源!
详细信息如下:

论文链接:https://arxiv.org/abs/2205.13515
项目链接:https://github.com/LayneH/GreenMIM
01
摘要
本文提出了一种基于分层视觉Transformer(ViT)的掩蔽图像建模(MIM)的有效方法,例如Swin Transformer,该方法允许分层ViT丢弃mask patch,只对可见patch进行操作。本文的方法包括两个关键部分。
首先,对于窗口注意力,作者按照分治策略设计了一个群体窗口注意力(Group Window Attention)方案。为了减轻自注意的二次复杂性的影响,群体注意力鼓励对任意大小的每个局部窗口内的可见patch进行统一的划分,可以将大小相等的patch分组,然后在每个组内执行masked self-attention。
其次,作者通过动态规划算法进一步改进分组策略,以最小化对分组patch的注意力的总体计算成本。因此,MIM现在可以以绿色高效的方式处理分层VIT。例如,作者可以将分层ViT的训练速度提高约2.7倍,并将GPU内存使用量减少70%,同时在ImageNet分类方面仍具有竞争力,在下游COCO目标检测基准上仍具有优势。
02
Motivation
由于掩蔽语言建模(Masked Language Modeling ,MLM)在自然语言处理(NLP)领域的巨大成功以及视觉Transformer(ViT)的进步,掩蔽图像建模(MIM)成为计算机视觉(CV)的一种有希望的自监督预训练范式。MIM可以利用masked prediction从未标记数据中学习表示,例如,预测离散token、潜在特征或随机掩蔽输入图像块的原始像素。其中,具有代表性的工作掩蔽自动编码器(Masked Autoencoder,MAE)表现出了有竞争力的性能和极高的效率。本质上,MAE为MIM提出了一种非对称编码器-解码器架构,其中编码器(例如,标准ViT模型)仅在可见patch上运行,而轻量级解码器恢复所有patch以进行掩蔽预测。
一方面,非对称编解码结构显著减少了预训练的计算负担。另一方面,MAE仅支持ViT结构作为编码器,而大多数现代视觉模型采用层次结构,部分原因是需要处理视觉元素的尺度变化。事实上,层次结构和局部归纳偏置在各种CV任务中至关重要,这些任务需要不同级别或尺度的表示来进行预测,包括图像分类和目标检测。然而,如何将层次视觉Transformer(如Swin Transformer)集成到MAE框架中仍然不明确。此外,尽管SimMIM研究了用于MIM的Swin Transformer,可在可见和掩蔽patch上运行,但与MAE相比,计算成本高。
为此,作者本着绿色AI的精神,努力为MIM设计一种新的绿色方法,采用分层模型。本文的工作重点是将MAE的非对称编码器-解码器结构扩展到分层视觉Transformer中,特别是代表性的模型Swin Transformer,以便仅对可见patch进行有效的预训练。作者发现,主要障碍是局部窗口注意的局限性。尽管局部窗口注意广泛应用于分层视觉Transformer中,但它不能很好地与随机mask配合使用,因为它会创建各种大小的局部窗口,无法并行计算。
本文提供了解决这个问题的第一次尝试。本文的方法在概念上很简单,由两个部分组成。首先,在分治原则的指导下,作者提出了一种组窗口注意力方案,该方案首先将可见patch数量不均匀的局部窗口划分为若干个大小相等的组,然后在每个组中应用mask attention。其次,作者将前面提到的组划分表述为一个约束优化问题,其中的目标是找到一个组划分,使对分组token注意力的计算成本最小。受动态规划概念和贪心原理的启发,作者提出了一种最优分组算法,该算法自适应地选择最优分组大小,并将局部窗口划分为最小数量的组。
本文的方法是通用的,并且没有对骨干模型的架构做任何修改,这样就可以在可见和掩蔽patch上与baseline进行公平的比较。在本文的实验评估中,作者观察到本文的方法需要更少的训练时间,消耗更少的GPU内存,而性能与baseline相同。具体而言,使用Swin-B,与SimMIM相比,本文的方法只需要一半的训练时间和大约40%的GPU内存消耗,同时在ImageNet-1K上实现与SimMIM相当的83.7%的top-1微调精度。
03
方法
3.1 Preliminary
Notations
设表示输入特征,其中C、H、W分别为X的通道数、高度和宽;表示训练中随机生成的空间mask,其中0表示一个patch对编码器不可见,反之亦然。
Masked Image Modeling
MIM通过从其部分观察中,预测输入X的屏蔽部分来学习表示,即。根据操作,现有的MIM方法分为两类。大多数方法使用Hadamard积进行掩蔽并保留掩蔽patch,即,其中M沿着通道维度广播C次。与这些方法形成鲜明对比的是,掩蔽自动编码器MAE (mask Autoencoders)提出在掩蔽阶段抛去掩蔽patch,即:

MAE设计了一种非对称的编码器-解码器结构:编码器只对不带mask token的可见patch进行操作;解码器从可见patch和mask patch的表示中重建原始图像。这种设计使MAE取得了具有竞争力的性能和极高的效率,例如,与所有patch操作相比,MAE达到了3倍的训练速度。
然而,MAE只适用于各向同性的ViT(即非层次的ViT),目前尚不清楚如何将MAE的效率转化为分层ViT,分层ViT在大多数视觉任务中几乎一致优于各向同性的ViT。在本文中,作者试图回答这个问题,并层次ViT提出了一个更绿色MIM的方法。
3.2 Green Hierarchical Vision Transformer for Masked Image Modeling
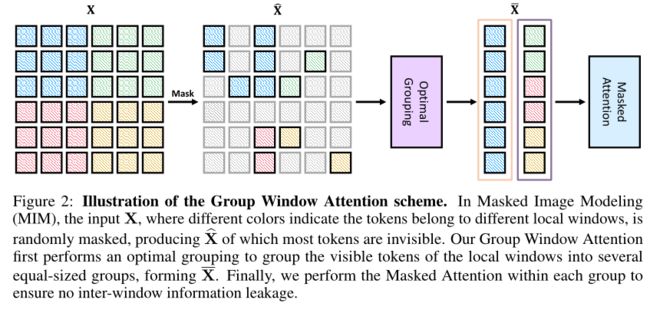
Base architecture
作者选择swin Transformer作为本文的baseline,它主要由前馈网络(FFN)和移位窗口注意组成。虽然FFN是逐点操作,并且只能对可见patch进行操作,但窗口注意力不能这样做。
给定一个窗口大小p(例如,Swin为7),窗口注意力首先将特征映射X划分为个不重叠的局部窗口,其中每个包含个patch。由于每个窗口包含相同数量的patch,因此在每个窗口内并行地独立执行MSA。然而,当局部窗口内patch数量不均匀时,如何高效并行计算注意力尚不清楚(如上图所示,mask之后每个窗口内的patch可能不一致)。
为此,作者提出了一种高效的群体窗口注意力(Group Window Attention)方案,直接替换Swin中所有的移位的窗口注意力,使其只对可见patch进行操作。
Group Window Attention
针对上述问题,作者提出了一种组窗口注意方案,该方案大大提高了掩蔽特征上窗口注意的计算效率。给定mask特征,作者收集了一组不均匀的局部窗口,其中每个元素只包含可见token,相应的大小为。
如上图所示,本文的组窗口注意力首先使用最优分组算法将不均匀的窗口划分为几个大小相等的组,然后在每个组内执行mask attention,以避免信息泄露。
3.3 Optimal Grouping with Dynamic Programming
General formulation
优化分组的第一步是找到一个索引分区与组大小相关:
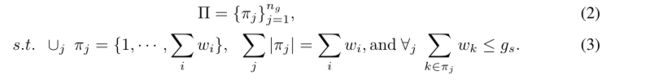
其中为组的个数。条件约束分区包含所有没有重复的局部窗口,并强制每个组的实际大小小于。基于分区,可以获得一组分组token:
![]()
在这狙token上执行mask attention。最后,作者应用索引分区的逆操作来恢复输出token的位置。
根据上面的公式,仍然有两个问题没有解决:1)如何选择最优分组大小, 2)给定,如何获得最优分区。为此,作者将目标表述为下面的min-min优化问题:

其中是一个cost函数,衡量的是分组token的注意力计算成本。直观上,式(5)旨在找出最佳分组大小,使得的计算成本最小。方程(6)在方程(3)的约束下寻找最优分区。有了最优的分组大小,可以直接得到最优分区。
Group partition with Dynamic Programming
作者发现(6)和(3)式中的优化问题是具有相同容量的多个子集和问题(MSSP-I)的一种特殊情况,它是具有相同容量的0-1多个背包问题(MKP-I)的变种。在本文的例子中,群体的大小类似于背包的容量,可见token的数量类似于货物的价值,货物的重量与它们的价值相同,背包的数量是无界的。虽然一般的多背包问题是NP-complete的,但它的变体MSSP-I可以在伪多项式时间内使用动态规划算法求解。具体来说,作者对单背包问题采用DP算法:
![]()
具体的伪代码如下所示:

Cost function
因为本文主要关心效率,所以作者使用FLOPs来衡量分组token上的多头注意力的计算复杂度,即:
![]()
其中C为通道数。虽然复杂度和group size的关系是二次的,但使用更小的可能产生更多的组,影响效率。因此,在训练过程中可以自适应地确定最优 group size。
Putting everything together
模型从到,遍历可能的组大小值,以找到最佳的组大小。对于每个选择的分组大小,作者首先使用式(7)中的DP算法对窗口进行划分,然后计算注意力在此划分上的计算代价。选择成本最小的群体作为最优群体规模。最优分组的伪代码总结如下所示。

3.4 Masked Attention
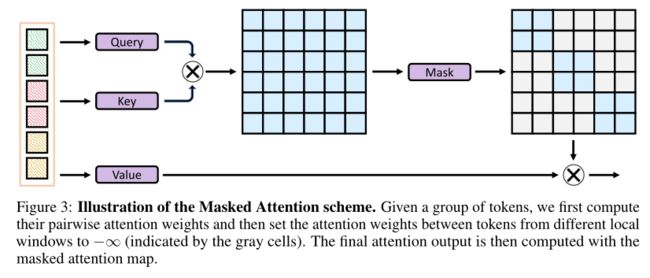
由于不相邻的局部窗口被划分为相同的组,因此需要mask这些局部窗口之间的注意力权值,以避免这些局部窗口之间的信息交换。如上图所示,在计算了attention map之后,作者只保留窗口内的注意权值(即对角线元素),而丢弃窗口间的注意力权值。在检索相对位置偏差时,作者也采用了类似的掩蔽方案,存储每个token的原始绝对位置,并实时计算相对位置来检索相应的偏差。
3.5 Batch-wise Random Masking
作者观察到,每个样本的随机掩蔽策略会降低本文方法的效率:1)它可能会产生不同数量的局部窗口组,这对于被掩蔽注意力的并行计算是棘手的;2)当mask patch尺寸小于分层模型的最大patch尺寸时,有些patch可能同时包含可见和mask输入。因此,作者提出将mask patch大小设置为与编码器最大patch大小相同的值,并对相同GPU设备中的所有样本使用相同的随机mask。
04
实验
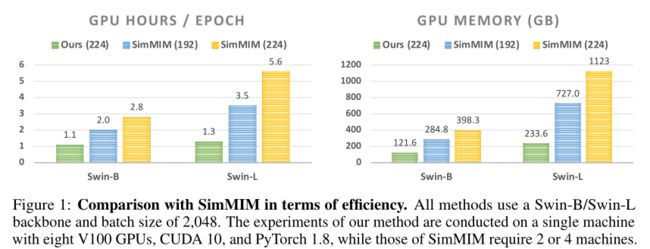
上图将本文的方法的效率与SimMIM进行了比较,可以看出本文方法的计算效率远高于SimMIM。
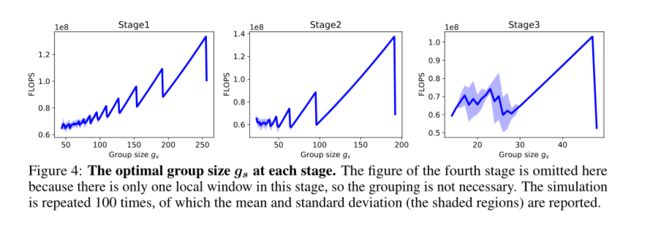
由于层次模型有多个阶段,具有不同的特征尺度,因此每个阶段的最佳组大小也可能不同。对此,作者设计了一个实验来分析不同阶段的最优。在实验中,作者随机生成100个mask,计算不同选择的成本,并在上图中报告成本的平均值/标准偏差。一般来说,作者观察到成本随组大小的平方增加而增加,但在某些情况下,组大小正好等于局部窗口子集的和。
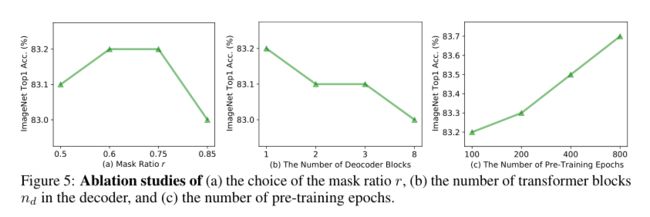
从上图(a)可以看出,掩蔽比r在0.5到0.85之间变化时,本文的方法的性能非常稳定。在上图(b)中,作者还研究了解码器深度的影响。有趣的是,结果表明更少的解码器块可以产生更好的结果。这项研究支持SimMIM采用分层模型的简单预测头设计,并与MAE采用各向同性模型的观察结果形成对比。此外,作者还研究了预训练预算对本文的方法的影响。如上图(c)所示,微调精度随着训练epoch的增加而稳步提高,并且似乎没有停滞,这表明它有可能进一步提高性能。

如上表所示,窗口大小加倍的预训练只会略微增加不到10%/20%的训练时间/GPU内存,但会带来适度的性能改善 。
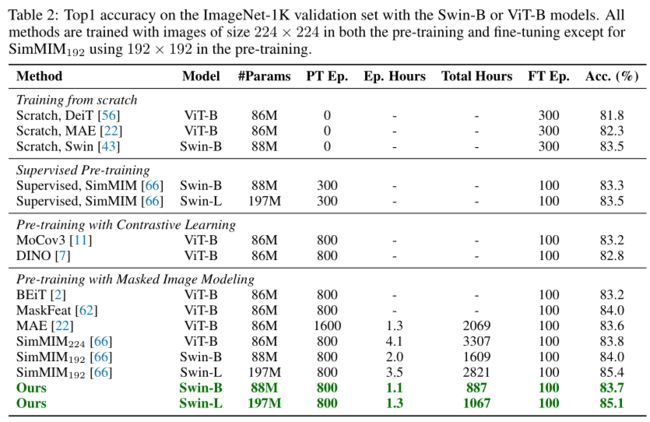
上表展示了本文方法在ImageNet-1K上和其他SOTA方法的对比结果。

最后,作者评估了本文预训练的模型到MS-COCO目标检测和实例分割的迁移学习性能。可以看出,与有监督的预训练Swin-B相比,本文的方法在所有指标方面都表现得更好。此外,作者还观察到,本文的方法在密集预测任务上的性能仍与SimMIM相当。
05
总结
在本文中,作者提出了一种使用层次视觉Transformer(如Swin Transformer)的掩蔽图像建模(MIM)的绿色方法,允许层次模型丢弃mask patch,只对可见patch进行操作。将高效的群体窗口注意力机制与基于DP算法的最优分组策略相结合,本文的方法可以训练层次模型,并将速度提高约2.7倍,GPU内存消耗减少70%,同时在ImageNet分类方面仍具有竞争力,并具有下游MS-COCO目标检测基准的优势。
参考资料
[1]https://arxiv.org/abs/2205.13515
[2]https://github.com/LayneH/GreenMIM

END
欢迎加入「Transformer」交流群备注:TFM
