【论文学习】YOLOv1-YOLOv4
文章目录
- You Only Look Once,Unified ,Real-Time Object Detection
-
- Abstract
- Introduction
- Unified Detection
-
- Network Design
- Training
- Inference
- Limitations of YOLO
- Comparison to Other Detection Systems
- YOLO9000:Better,Faster,Stronger
-
- Abstract
- Introduction
- Better
-
- Batch Normalization批量歸一化
- High Resolution Classifier 高分辨率分類器
- Convolutional With Anchor Boxes帶錨框的捲積
- Dimension Clusters維度集群
- Direct location prediction 直接定位預測
- Fine-Grained Features 細粒度特徵
- Multi-Scale Training 多尺度訓練
- Further Experiments 更多的實驗
- Faster
-
- Training for classification為分類的訓練
- Stronger
-
- Hierarchical classification分級分類
- Dataset combination with WordTree
- Joint classification and detection
- An Inctemental Improvement
-
- The Deal
-
- Bounding Box Prediction邊界框預測
- Class Prediction類別預測
- Predictions Across Scales跨尺度預測
- Feature Extractor 特徵提取
- Training 訓練
- How we do
- Things we tried that didn't work
- YOLOv4:Optimal Speed and Accuracy of Object Detection
-
- Abstract
- Introduction
- Related work
-
- Object detection models
- Bag of freebies
- Bag of specials
-
- receptive field
- attention
- activation function
- NMS
- Methodology
-
- Selection of architecture
- Selection of BoF and BoS
- Additional improvements
- YOLOv4
- Experiments
-
-
- Influence of different features on Classifier training
- Influence of different features on Detector training
- Influence of different backbones and pretrained weightings on Detector training
- Influence of different mini-batch size on Detector training
-
You Only Look Once,Unified ,Real-Time Object Detection
Abstract
we frame object detection as a regression problem to spatially separated bouding boxes and associated probabilities
作為空間分離的邊界框和相關概率的回歸問題
Introduction
Current detection systems repurpose classifiers to perform detection.To detect an object, these
systems take a classifier for that object and evaluate it at various locations and scales in a test image. System like deformable parts models(DPM) use a sliding window approach where the classifier is run at evenly spaced locations over the entire image
當前的檢測系統重新利用分類器來執行檢測。為了檢測物體,這些系統採用該對象的分類器,並在測試圖像中的不同位置和尺度上對其進行評估。 類似可變形部件模型(DPM) 的系統使用滑動窗口方法,其中分類器在整個圖像上均勻分佈的位置運行。
其他像R-CNN的(region proposal)區域提議方法的實現步驟是
- first generate potential bounding boxes in an image and then run a classififer on these proposed boxes首先在圖像中生成潛在的邊界框,然後在這些提議的框上運行分類器
- classification 識別檢測
- post-processing is used to refine the bouding boxes,eliminate duplicate detections and rescore the boxes based on other objects in the scene.後處理用於細化邊界框,消除重複檢測並根據場景中的其他對像對邊界框重新評分。
總結,these complex pipelines are slow and hard to optimize because each individual component must be trained separately這些複雜的管道很慢且難以優化,因為每個單獨的組件都必須單獨訓練
hier ist yolo
we reframe object detection as a single regression problem,straight from pixel to bouding box coordinates and class probabilities
我們將目標檢測重新定義為一個單一的回歸問題,直接從像素到邊界框坐標和類別概率
YOLO的優點概括為
-
檢測速度快
further more,YOLO achieves more than twice the mean average precision of other real-time systems.
-
感受野大
YOLO reasons globally about the image when making predictions.YOLO 在進行預測時對圖像進行全局推理
YOLO sees the entire image during training and test time so it implicitly encodes contextual information about the classes as well as their appearance.YOLO 在訓練和測試期間看到整個圖像,因此它隱式編碼有關類別及其外觀的上下文信息
-
YOLO learns generalizable representations of objects.YOLO 學習對象的概括表示
Unified Detection
統一檢測。
我們將目標檢測的獨立組件(separate components)統一到一個神經網絡中。
每个邊界框bounding box包含5个预测x,y,w,h,和confidence
每个網格單元grid cell还会预测一个C,conditional class probabilities條件類概率。Pr(Class|Object)
我們只預測每個網格單元的一組類概率,而不管框的數量。
Our system models detection as a regression problem,It divides the image into an SxS grid and for each cell predicts B bounding boxes,confidence for those boxes and C class probabilities.These predictions are encoded as an SXSX(BX5+C) tensor
S=7,B=2,C=20
Network Design
The initiali convolutional layers of the network extract features from the image while the fully connected layers predict the output probabilities and coordinates.
網絡的初始卷積層從圖像中提取特徵,而全連接層預測輸出概率和坐標。
Our network architecture is inspired by the GoogLeNet model for image classification .Out network has 24 convolutional layers followed by 2 fully connected layers
Instead of the inception modules used by GoogLeNet,we simply use 1x1 reduction layers followed by 3x3 convolutional layers .
我們的網絡架構受到用於圖像分類的 GoogLeNet 模型的啟發。Out 網絡有 24 個卷積層,後面跟著 2 個全連接層
我們沒有使用 GoogLeNet 使用的初始模塊,而是簡單地使用 1x1 縮減層,然後是 3x3 卷積層。
Training
adding both convolutional and connected layers to pretrained networks can improve performance.
预训练的权重提升精度
Our final layer predicts both class probabilities and bounding box coordinates,We normalize the bounding box width and height by the image width and height so that they fall between 0 and 1
归一化边界框
在最后一层是用线性激活函数。leakly relu

Leaky ReLu 中的
ai是固定的
we optimize for sum-squared-error in the output of our model
使用误差平方和作为optimize
We use sum-squared error because it is easy to optimize, however it does not perfectly align with our goal of maximizing average precision. It weights localization error equally with classification error which may not be ideal. Also, in every image many grid cells do not contain any object. This pushes the “confidence” scores of those cells towards zero, often overpowering the gradient from cells that do contain objects. This can lead to model instability, causing training to diverge early on.
本地权重会导致分类误差,并且使模型在训练早期出现分歧
為了解決這個問題,我們增加了邊界框的損失
協調預測並減少不包含對象的框的置信度預測的損失。 我們
使用兩個參數,λcoord 和 λnoobj 來完成這個。 我們
設置 λcoord = 5 和 λnoobj = .5。
增加bounding box的损失函数,减少predictions的loss
YOLO 預測每個網格單元的多個邊界框。在訓練時,我們只需要一個邊界框預測器對每個對象負責。 我們分配一個預測變量
“負責responsible”預測基於哪個對象prediction 與 ground 的當前 IOU 最高真相。
這導致邊界框預測器之間的專業化。 每個預測器都能更好地預測特定尺寸、長寬比或對像類別,從而提高整體召回率
請注意,損失函數僅懲罰分類如果對象存在於該網格單元中,則錯誤(因此前面討論的條件類概率)。 如果該預測變量是對地面實況框“負責responsible”(即具有最高該網格單元中任何預測器的 IOU)。
Our learning rate schedule is as follows: For the first epochs we slowly raise the learning rate from 10−3 to 10−2 . If we start at a high learning rate our model often diverges due to unstable gradients如果我們以高學習率開始,我們的模型通常會因梯度不穩定而發散。. We continue training with 10−2 for 75 epochs, then 10−3 for 30 epochs, and finally 10−4 for 30 epochs.
我們引入了高達原始圖像大小 20% 的隨機縮放和平移。 我們還在 HSV 顏色空間中將圖像的曝光和飽和度隨機調整了 1.5 倍。
Inference
the grid design enforces spatial diversity网格增加空间多样性
Limitations of YOLO
-
YOLO 對邊界框預測施加了很強的空間約束,因為每個網格單元只能預測兩個框並且只能有一個類別。 這種空間約束限制了我們的模型可以預測的附近物體的數量。
-
由於我們的模型學會了預測邊界框數據,它很難泛化到新的或不尋常的對象,寬高比或配置。 我們的模型還使用相對粗糙的特徵來預測邊界框,因為我們的架構有多個下採樣層輸入圖像
-
最後,當我們訓練一個接近檢測性能的損失函數時,我們的損失函數處理錯誤。小邊界框與大邊界框相同盒子。 大盒子中的小錯誤通常是良性的,但小盒子裡的小錯誤對 IOU 的影響要大得多。
我們的主要錯誤來源是不正確的本地化。
Comparison to Other Detection Systems
检测图片方式大多是滑动窗口,或者是区域子集
Deformable parts models
DPM uses a disjoint pipeline to extract static features,classify regions ,predict bouding boxes for high scoring,DPM 使用不相交的管道來提取靜態特徵,對區域進行分類,預測邊界框以獲得高置信度,
YOLO取代了所有這些不同的部分,使用單個卷積神經網絡。 網絡同時執行特徵提取、邊界框預測、非最大抑制和上下文推理。 網絡不是靜態特徵,而是在線訓練特徵並針對檢測任務優化它們。 我們的
統一架構帶來更快、更準確的模型
R-CNN
R-CNN 及其變體使用區域建議而不是滑動窗口來查找圖像中的對象。 选择性搜索 生成潛在的邊界框,卷積網絡提取特徵,SVM 對框進行評分,一個線性模型調整邊界框,非最大抑制消除重複檢測。 這個每個階段。複雜的管道必須獨立精確調整,結果系統非常慢。
YOLO與 R-CNN 有一些相似之處。 每格單元格提出潛在的邊界框並對其進行評分。使用卷積特徵的框。 然而,我們的系統對網格單元提案施加空間限制,有助於減輕對同一對象的多次檢測。
Other Fast Detectors
Fast and Faster R-CNN 專注於通過共享計算和使用神經網絡代替提議區域,而不是選擇性搜索。來加速 R-CNN 框架。
Deep MultiBox
MultiBox can also perform single object detection by replacing the confidence prediction with a single class prediction. However, MultiBox cannot perform general object detection and is still just a piece in a larger detection pipeline, requiring further image patch classification. Both YOLO and MultiBox use a convolutional network to predict bounding boxes in an image but YOLO is a complete detection system.
MultiBox還可以通過替換置信度來執行單個對象檢測
使用單類預測進行預測。 然而,MultiBox 不能執行一般的對象檢測,仍然只是
更大的檢測管道中的一塊,需要進一步的圖像塊分類。 YOLO 和 MultiBox 都使用了
卷積網絡來預測圖像中的邊界框,但 YOLO 是一個完整的檢測系統。
OverFeat
OverFeat efficiently performs sliding window detection but it is still a disjoint system
OverFeat 有效地執行滑動窗口檢測,但它仍然是一個不相交的系統
MutliGrasp
MultiGrasp only needs to predict a single graspable region for an image containing one object. It doesn’t have to estimate the size, location, or boundaries of the object or predict it’s class,MultiGrasp只需要預測包含圖像的單個可抓取區域一個對象。 它不必估計大小、位置、或對象的邊界或預測它的類別。
YOLO9000:Better,Faster,Stronger
Abstract
First,we propose various improvements to the YOLO detection method,both novel and drawn from prior work
YOLO检测方法改进
outperforming state-of-art methods like Faster R-CNN with ResNet and SSD while still running significantly faster.
性能依旧比Faster R-CNN和SSD好
Introduction
most detection methods are still constrained to a small set of objects
目标检测受限于小目标检测
labelling images for detection is far more expensive than labelling for classification or tagging 为检测标记图像比分类或标记要昂贵的多。
we propose a new method to harness the image amount of classification data we already have and use it to expand the scope of current detection systems.Our method uses a hierachical view of object classification that allows us to combine distinct datasets together使用对象分类的层次试图,允许我们将不同的数据集集合起来。
We also propose a joint training algorithm(連接訓練算法) that allows us to train object detectors on both detection and classification data. Our method leverages labeled detection images to learn to precisely localize objects while it uses classification images to increase its vocabulary and robustness.我们的方法利用標記的檢測圖像來學習精確定位對象,同時使用分類圖像來增加詞彙量和魯棒性
Better
YOLO suffers from a variety of shortcomings relative to state-of-the-art detection systems. Error analysis of YOLO compared to Fast R-CNN shows that YOLO makes a significant number of localization errors. Furthermore, YOLO has relatively low recall compared to region proposal-based methods. Thus we focus mainly on improving recall and localization while maintaining classification accuracy
存在兩個問題
- 定位錯誤多
- 較低的召回率
Computer vision generally trends towards larger, deeper networks
Instead of scaling up our network, we simplify the network and then make the representation easier to learn與擴大網絡結構不同,我們讓特徵更容易學習。
Batch Normalization批量歸一化
batch normalization leads to significant improvements in convergence while eliminating the need for other forms of regularization
批量歸一化顯著提高收斂性,同時消除了對其他形式的正則化的需要。
High Resolution Classifier 高分辨率分類器
For YOLOv2 we first fine tune the classification network at the full 448 × 448 resolution for 10 epochs on ImageNet. This gives the network time to adjust its filters to work better on higher resolution input. We then fine tune the resulting network on detection. This high resolution classification network gives us an increase of almost 4% mAP.
擴大圖片尺寸,給網絡時間去調整過濾器在高分辨率圖片上,表現更好
Convolutional With Anchor Boxes帶錨框的捲積
Instead of predicting coordinates directly Faster R-CNN predicts bounding boxes using hand-picked priors 精心挑選的先驗
Predicting offsets instead of coordinates simplifies the problem and makes it easier for the network to learn
預測偏差比直接預測坐標簡單,模型也好學習
We remove the fully connected layers from YOLO and use anchor boxes to predict bounding boxe
使用錨框預測邊界框
anchor box:根據預測的形狀來設計的box
bouding box:根據預測的分類來設計的box
When we move to anchor boxes we also decouple the class prediction mechanism from the spatial location and instead predict class and objectness for every anchor box.
當我們移動錨框的時候,我們還將類別預測機制與空間位置分離,而不是為每個錨框預測類別和對象
Dimension Clusters維度集群
We encounter two issues with anchor boxes when using them with YOLO. The first is that the box dimensions are hand picked. The network can learn to adjust the boxes appropriately but if we pick better priors for the network to start with we can make it easier for the network to learn to predict good detections
盒子的維度是先驗的。也就是說如果我們一開始選擇的維度是較好的,模型的訓練也會更加順利。
Instead of choosing priors by hand, we run k-means clustering on the training set bounding boxes to automatically find good priors
我們不是手動選擇先驗,而是在訓練集邊界框上運行 k-means 聚類以自動找到好的先驗
If we use standard k-means with Euclidean distance larger boxes generate more error than smaller boxes.如果我們使用標準的 k-means
歐氏距離較大的框比較小的框產生更多的錯誤。
We run k-means for various values of k and plot the average IOU with closest centroid, see Figure 2. We choose k = 5 as a good tradeoff between model complexity and high recall.
我們對各種 k 值運行 k-means 並繪製具有最接近質心的平均 IOU,參見圖 2。我們選擇 k = 5 作為模型複雜性和高召回率之間的良好折衷。
Direct location prediction 直接定位預測
When using anchor boxes with YOLO we encounter a second issue: model instability, especially during early iterations.
使用錨框時對於 YOLO,我們遇到了第二個問題:模型不穩定,特別是在早期迭代期間。
For example, a prediction of tx = 1 would shift the box to the right by the width of the anchor box, a prediction of tx = −1 would shift it to the left by the same amount.
With random initialization the model takes a long time to stabilize to predicting sensible offsets.
隨機初始化模型,花很長時間,去穩定地預測合理偏差
Instead of predicting offsets we follow the approach of YOLO and predict location coordinates relative to the location of the grid cell. This bounds the ground truth to fall between 0 and 1. We use a logistic activation to constrain the network’s predictions to fall in this range.
限制位置預測使得更穩定,易於學習。
Fine-Grained Features 細粒度特徵
passthrough layer
We take a different approach, simply adding a passthrough layer that brings features from an earlier layer at 26 × 26 resolution.
添加一個穿透層,以26x26分辨率從從前層中提取特徵。
The passthrough layer concatenates the higher resolution features with the low resolution features by stacking adjacent features into different channels instead of spatial locations, 穿透層通過將相鄰特徵堆疊到不同的通道,而不是空間位置,將高分辨率特徵與低分辨率特徵連結起來。
Multi-Scale Training 多尺度訓練
We want YOLOv2 to be robust to running on images of different sizes so we train this into the model.
Instead of fixing the input image size we change the network every few iterations
每隔幾次迭代,我們將會改變圖片的輸入尺寸
This regime forces the network to learn to predict well across a variety of input dimensions
這種制度迫使網絡學會在各種輸入維度上進行良好預測
Further Experiments 更多的實驗
…
Faster
Most detection frameworks rely on VGG-16 as the base feature extractor . VGG-16 is a powerful, accurate classification network but it is needlessly complex. The convolutional layers of VGG-16 require 30.69 billion floating point operations for a single pass over a single image at 224 × 224 resolution.
大多數的目標檢測框架核心是VGG16,很準確但是也很複雜和慢
vgg16:
The YOLO framework uses a custom network based on the Googlenet architecture
YOLO使用GoogleNet作為參照,但是少了一些準確性
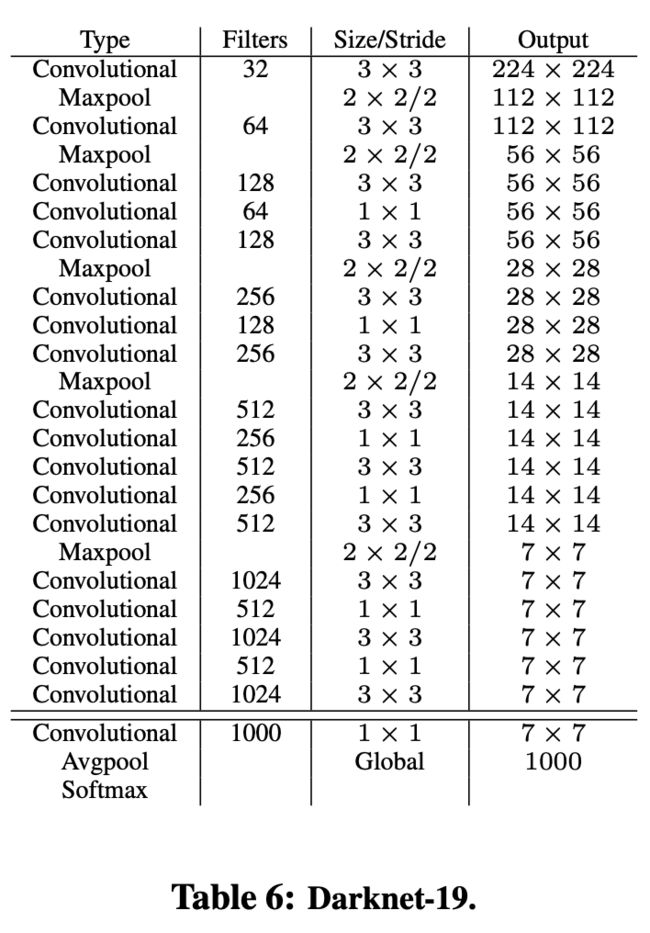
We propose a new classification model to be used as the base of YOLOv2. Our model builds off of prior work on network design as well as common knowledge in the field. Similar to the VGG models we use mostly 3 × 3 filters and double the number of channels after every pooling step [17]. Following the work on Network in Network (NIN) we use global average pooling to make predictions as well as 1 × 1 filters to compress the feature representation between 3 × 3 convolutions [9]. We use batch normalization to stabilize training, speed up convergence, and regularize the model [7].
我們最後的模型叫做darknet-19,訓練參數進一步減少
Darknet19:
Training for classification為分類的訓練
We train the network on the standard ImageNet 1000 class classification dataset for 160 epochs using stochastic gradient descent with a starting learning rate of 0.1, polynomial rate decay with a power of 4, weight decay of 0.0005 and momentum of 0.9 using the Darknet neural network framework
我們在標準 ImageNet 1000 類分類數據集上訓練網絡 160 個時期,使用隨機梯度下降,起始學習率為 0.1,多項式速率衰減為 4,權重衰減為 0.0005,動量為 0.9,使用 Darknet 神經網絡框架
Stronger
We propose a mechanism for jointly training on classification and detection data.
我們提出了一種聯合訓練分類和檢測數據的機制。
During training we mix images from both detection and classification datasets. 1⃣️When our network sees an image labelled for detection we can backpropagate based on the full YOLOv2 loss function. 2⃣️When it sees a classification image we only backpropagate loss from the classificationspecific parts of the architecture.
1⃣️當網絡看到一個標記為檢測的圖像,基於完整的yolov2損失函數進行反向傳播
2⃣️當網絡看到一個分類圖像,從架構的分類特定部分中反向傳播損失
This approach presents a few challenges. Detection datasets have only common objects and general labels, like “dog” or “boat”. Classification datasets have a much wider and deeper range of labels. ImageNet has more than a hundred breeds of dog
这种方法带来了一些挑战 检测数据集只有通用对象和通用标签,如“狗”或“船”。分类数据集的标签范围更广、更深。ImageNet有一百多种狗
If we want to train on both datasets we need a coherent way to merge these labels.
使用連貫方法去merge類別
Most approaches to classification use a softmax layer across all the possible categories to compute the final probability distribution. Using a softmax assumes the classes are mutually exclusive
使用softmax是相互排斥的,
We could instead use a multi-label model to combine the datasets which does not assume mutual exclusion. This approach ignores all the structure we do know about the data, for example that all of the COCO classes are mutually exclusive
我們可以改為使用多標籤模型來組合
不假設互斥的數據集。 這種方法忽略了我們所知道的關於數據的所有結構,
例如,所有 COCO 類都是互斥的
Hierarchical classification分級分類
we simplify the problem by building a hierarchical tree from the concepts in ImageNet.
在ImageNet中建立概念的分級樹
To build this tree we examine the visual nouns in ImageNet and look at their paths through the WordNet graph to
the root node, in this case “physical object”. Many synsets
only have one path through the graph so first we add all of
those paths to our tree. Then we iteratively examine the
concepts we have left and add the paths that grow the tree
by as little as possible. So if a concept has two paths to the
root and one path would add three edges to our tree and the
other would only add one edge, we choose the shorter path.為了構建這棵樹,我們檢查了 ImageNet 中的視覺名詞並查看它們通過 WordNet 圖的路徑
根節點,在本例中為“物理對象”。 許多同義詞集
只有一條路徑通過圖表,所以首先我們添加所有
那些通往我們樹的路徑。 然後我們反複檢查
我們留下的概念並添加生長樹的路徑
盡可能少。 所以如果一個概念有兩條路徑
根和一條路徑會為我們的樹添加三個邊,而
其他只會添加一條邊,我們選擇較短的路徑。
So if a concept has two paths to the root and one path would add three edges to our tree and the other would only add one edge, 找到最短路徑
The final result is WordTree, a hierarchical model of visual concepts. To perform classification with WordTree we predict conditional probabilities at every node for the probability of each hyponym of that synset given that synset. For example, at the “terrier” node we predict:最終的結果是 WordTree,一種視覺概念的層次模型。 為了使用 WordTree 進行分類,我們
在給定同義詞集的情況下,為該同義詞集的每個下位詞的概率預測每個節點的條件概率。
. During training we propagate ground truth labels up the tree so that if an image is labelled as a “Norfolk terrier” it also gets labelled as a “dog” and a “mammal”, etc. . 在訓練中
我們在樹上傳播真值標籤,這樣如果一個圖像被標記為“諾福克梗”,它也會被標記為
“狗”和“哺乳動物”等
Performance degrades gracefully on new or unknown object categories. For example, if the network sees a picture of a dog but is uncertain what type of dog it is, it will still predict “dog” with high confidence but have lower confidences spread out among the hyponyms
在未知目標上表現良好
Dataset combination with WordTree
We simply map the categories in the datasets to synsets in the tree.
Joint classification and detection
An Inctemental Improvement
The Deal
Bounding Box Prediction邊界框預測
在訓練期間,我們使用誤差平方和損失。 如果
一些坐標預測的基本事實是 t^*
我們的梯度是地面真實值(從地面計算
真值框)減去我們的預測:t^* - t*
通過反轉上面的等式可以很容易地計算出這個真實值。
Class Prediction類別預測
Each box predicts the classes the bounding box may contain using multilabel classification. We do not use a softmax as we have found it is unnecessary for good performance, instead we simply use independent logistic classifiers. During training we use binary cross-entropy loss for the class predictions.
每個框使用多標籤分類預測邊界框可能包含的類。 我們不使用 softmax,因為我們發現它對於良好的性能是不必要的,而是我們簡單地使用獨立的邏輯分類器。 在訓練期間,我們使用二元交叉熵損失進行類別預測。
Predictions Across Scales跨尺度預測
YOLOv3 predicts boxes at 3 different scales,Our systeam extracts features from those scales using a similar concept to feature pyramid networks
YOLOv3 預測 3 種不同尺度的框,我們的系統使用與特徵金字塔網絡類似的概念從這些尺度中提取特徵。
From our base feature extractor we add several convolutional layers. The last of these predicts a 3-d tensor encoding bounding box, objectness, and class predictions.
從我們的基本特徵提取器中,我們添加了幾個卷積層。 最後一個預測 3-d 張量編碼邊界框、目標性和類別預測。
Feature Extractor 特徵提取
我們使用一個新的網絡來執行特徵提取。
我們的新網絡是 YOLOv2、Darknet-19 中使用的網絡和新奇的殘差網絡材料之間的混合方法。
這種模型叫做Darknet53

This new network is much more powerful than Darknet19 but still more efficient than ResNet-101 or ResNet-152
Training 訓練
We use multi-scale training,lots of data augmentation,batch normalization,all the standard stuff .
How we do
pass
Things we tried that didn’t work
Here’s the stuff we can remember
-
Anchor box:
anchor box xy offset prediction
-
Linear:
linear xy prediction instead of logistic
-
Focal loss:
-
Dual IOU thresholds and truth assignments
YOLOv4:Optimal Speed and Accuracy of Object Detection
Abstract
we assume that such universal features include Weighted-Residual-Connections(WRC).Cross-Stage-Partial-connections (CSP),
Introduction
the majority of CNN-based object detectors are largely applicable only for recommendation systems
基於CNN的目標檢測很大程度上取決了操作系統。
Improving the real-time object detector accuracy enables using them not only for hint generating recommendation systems,but also for stand-alone process management and human input reduction
通過改進實時對象檢測器,不僅可以將其用於生成推薦系統,還可以用於獨立的過程管理和減少人工輸入。
The most accurate modern neural networks do not operate in real time and require large number of GPUs for training with a large mini-batch-size
最精確的現代神經網路不能實时運行,並且需要大量GPU來進行大規模的小批量訓練
The main goal of this work is designing a fast operating speed of an object detector in production systems and optimization for parallel compuations
設計生產系統中物體監測器的快速運行速度並優化並行計算,而不是低體積的理論指標。
Related work
Object detection models
a modern detector is usually composed of two parts,a backbone which is pre-trained on ImageNet and a head which is used to predict classes and bounding boxes of objects
現代目標檢測分為倆個步驟1⃣️backbone預訓練模型2⃣️head預測類別概率
關於head的部分有
-
one-stage object detector單通道檢測器
yolo,ssd
-
two-stage object detector雙通道檢測器
R-CNN series
It is also possible to make a two-stage object detector an anchor-free object detector
雙通道也能發展成anchor-free
Object detectors developed in recent years often insert some layers between backbone and head,and these layers are usually used to collect feature maps from different stages.
神經網絡通過增加網絡層數來手機不同角度的特徵。
we can call it the neck of the an object detector
我們將這個稱為網絡的頸部
Usually,a neck is composed of serveral bottom-up paths and serveral top-down paths
目標檢測的頸部通常有自下而上,或自上而下的路徑組成。
To sum up,an ordinary object detector is composed of serval parts
總計來說,目標檢測由以下組成
-
**Input:**Image,Patches,Image Pyramid
-
Backbone:(VGG16,ResNet-50,SpineNet)(gpu platform),EfficientNet-B0/B7,CSPResNeXt50,CSPDarkNet53
-
Neck:
collect features map from different stages從不同階段收集特徵圖
- **Additional blocks:**SPP,ASPP,RFB,SAM
- **Path-aggregation blocks:**PPN,PAN,NAS-FPN,Fully-connected FPN,BiFPN,ASFF,SFAM
-
Heads:
- Dense Prediction(one-stage):
- RPN,SSD,YOLO,RetinaNet(anchor based)
- CornetNet,CenterNet,MatrixNet,FCOS,(anchor free)
- Sparse Prediction(two-stage):
- Faster R-CNN,R-FCN,Mask R-CNN(anchor based)
- RepPoints(anchor free)
- Dense Prediction(one-stage):
Bag of freebies
usually a convolutional object detector is trained offline.Therefore,researchers always like to take this advantage and develop receive better accuracy without increasing the inference cost使用更好的訓練方法而不增加推理成本
we can call these methods that only change the training strategy or only increase the training cost as ‘bag of freebies’
這種只改變訓練策略,或者增加訓練成本的方法,稱呼為bag of freebies免費包
what is often adopted by object detection methods and meets the definition of bag of freebies is data augmentation.
对象检测方法经常采用的并且符合freebies包定义的是数据增强。
The purpose of data augmentation is to increase the variablity of the input images ,so that the designed object detection model has higher robustness to the images obtained from different enviroments
數據增強的目標是在不同環境下,模型有更高的魯棒性。
photometric distoritions ,geometric distoritions
常見的數據增強方法有photometric distoritions光度失真 ,geometric distoritions幾何失真
the data augmentation methods mentioned above are all pixel-wise adjustments .逐像素調整
in addition,some researchers engaged in data augmentation put their emphasis on simulating object occlusion issues.將重點放在模擬對象遮擋的發布者上
in addition to above mentioned methods,style transfer GAN is also used for data augmentation,and such usuages can effectively reduce the texture bias learned by CNN甚至用GAN 產生的圖片來訓練CNN
Different from the various approaches proposed above,some other bag of freebies methods are dedicated to solving the problem that the semantic distribution in the datase may have bias
致力解決數據集中語義分佈存在偏差的問題,
In dealing with the problem of semantic distribution bias,a very important issue is that there is a problem of data imbalance between different classessm,and this problem is often solved by hard negative example mining or online hard example mining in two-stage object detector
不同類之間存在數據不平衡的問題,這一問題通常通過雙通道檢測中的硬否定示例挖掘或在線硬示例挖掘解決。
。。。。
Bag of specials
for those plugin modules and post-processing methods that **only increase the inference cost by a small amount but can signifficantly improve the accuracy of object detection.**we can call them ‘bag of specials’
增加小部分的推理時間,但明顯增加模型精度的預處理方法
Generally speaking these plugin modules are for enhancing certain attributes in these plugin modules are for enhancing certain attributes in a model ,such as enlarging receptive field,introducing attention mechasim,or strengthening feature intergration catpability
常見的方法有增大感受嘢,注意力機制等
receptive field
common modules that can be used to enhance receptive filed are SPP,ASPP,and RFB
擴大感受野的方法有SPP,ASPP,RFB
The SPP modul was originated from Spatial Pyramid Matching(SPM)
SPP模块源自空间金字塔匹配(SPM)
SPMs original method was to split feature map into serval
dxdequal blocks,wheredcan be {1,2,3},thus forming spatial pyramid,and then extracting bag of word features.
SPP intergrates SPM into CNN and use max-pooling operation instead of bag-of-word-operation
SPM最初的方法是将特征图分割成几个“dxd”相等的块,其中“d”可以是{1,2,3}从而形成空间金字塔,然后提取单词特征包。SPP将SPM集成到CNN中,并使用最大池操作而不是单词包操作
Since the SPP module proposed by… will output one dimensional feature vector
SPP模塊輸出一維特鎮向量。
Under a design,a relatively large kxk max-pooling effectively increase the receptive field of backbone feature
在设计中,相对较大的“kxk”最大池有效地增加了主干特征的感受野
the difference in operation between ASPP module and improved SPP module is mainly from the original
kxkkernel size,max-pooling of stride equals to 1 to several 3x3 kernel size .
attention
The attention module that is often used in object detection is mainly divided into channel-wise attention and point-wise attention.
In terms of feature intergration,the early practice is use skip connection or hyper-column to intergrate low-level physical feature to high-level semantic feature
在特征集成方面,早期的实践是使用跳过连接或超列t将低级物理特征集成到高级语义特征
activation function
in the research of deep learning ,some people put their focus on searching for good activation function.
in 2010,Nair and hinton propose ReLU to substantially solve the gradient vanish problem which is frequently encountered in traditional tanh and sigmoid activation function2010年,Nair和hinton提出了ReLU,以实质上解决传统tanh和sigmoid激活函数中经常遇到的梯度消失问题
LReLU and PReLU is to solve the problem that the gradient of ReLU is zero when the ouput is less than zero
NMS
the post-processing method commonly used in deep learning-based object detection is NMS,which can be used to filter those BBoxes,that badly predict the same object and only retain the candidate BBoxes with higher response.在基于深度学习的对象检测中通常使用的后处理方法是NMS,它可以用于过滤那些预测相同对象的BBox,并且只保留具有较高响应的候选BBox。
The NMS tries to improve is consistent with the method of optimizing an objective function
NMS试图改进与优化目标函数的方法一致
Methodology
Selection of architecture
Our objective is to find the optimal balance among the input network resolution, the convolutional layer number, the parameter number (filter size2 * filters * channel / groups), and the number of layer outputs (filters).
找到輸入網絡分辨率,卷積層數,參數和層輸出數之間的最佳平衡
The next objective is to select additional blocks for increasing the receptive field and the best method of parameter aggregation from different backbone levels for different detector levels:
從不同backbone水平為不同的檢測器水平選擇額外的句塊來增加接受填充和參數聚集的最佳方式
A reference model which is optimal for classification is not always optimal for a detector. In contrast to the classifier, the detector requires the following:
最佳分類參攷模型為
對於檢測器來說並不總是最佳的。 與分類器不同,檢測器需要以下各項:
-
Higher input network size(resolution ) – for detecting multiple small-size objects
更高的輸入網絡大小(分辯率)–用於檢測多個小尺寸對象
-
More layers – for a higher receptive field to cover the increased size of input network
更深層數
-
More parameters – for greater capacity of a model to detect multiple objects of different sizes in a single image
更多參數
The influence of the receptive field with different sizes is summarized as follows:
不同大小的感受野的影響總結如下:
-
Up to the object size – allows viewing the entire object
最大對象大小
-
Up to network size – allows viewing the context around the object
最大網絡大小
-
Exceeding the network size – increase the number of connections between the image point and the final activation
超過網絡大小增加圖像點和最終獲得之間的連結數量
Selection of BoF and BoS
For improving the object detecting training ,a CNN usually uses the following :
-
Activations:
-
Bounding box regression loss:
-
Data augmentation:
-
Regularization method:
-
Normalization of the network activations by their mean and variance
網絡激活的均值和方差歸一化
-
Skip-connections
Additional improvements
In order to make the designed detector more suitable for training on single GPU,we made a additional design and improvement as follows:
-
We introduce a new method of data augmentation Mosaic,and Self-Adversarial Training(SAT)
數據增強方式:Mosaic和自對抗機制
-
we select optimal hyper -parameters while applying genetic algorithms
應用遺傳算法選擇最優超參數
-
we modify some existing methods to make our design suitable for efficient training and detection -modified SAM ,modified PAN,and Cross mini-Batch Normalization
Mosaic represents a new data augmentation method that mixes 4 training images,Thus 4 different contexts are mixed .
In addition,batch normalization calculates activation statistics from 4 different images on each layer,This significantly reduces the need for a largre min-batch-size
批量標準化從每個層的4個不同圖像中計算激活統計,大大減少了對批量的統計。
**Self-Adversarial Training (SAT) **also represents a new data augmentation technique that operates in 2 forward backward stages. In the 1st stage the neural network alters the original image instead of the network weights. In this way the neural network executes an adversarial attack on itself, altering the original image to create the deception that there is no desired object on the image. In the 2nd stage, the neural network is trained to detect an object on this modified image in the normal way
1⃣️神經網絡改變原始圖像而不是網路權重,通過這種方式神經網路對自己進行對抗性攻擊,改變原始圖像以製造所有所需對象的假象
2⃣️神經網路被訓練以正常形式檢測修改後的圖像上的對象
YOLOv4
Backbone:預訓練模型
Neck:從不同階段預測特徵圖
Head:預測類別概率
Backbone:CSPDarknet53
Neck:SPP,PAN

Head:YOLOv3
YOLO v4 uses:
- Bag of Freebies (BoF) for backbone: CutMix and Mosaic data augmentation, DropBlock regularization, Class label smoothing
- Bag of Specials (BoS) for backbone: Mish activation, Cross-stage partial connections (CSP), Multiinput weighted residual connections (MiWRC)
- Bag of Freebies (BoF) for detector: CIoU-loss, CmBN, DropBlock regularization, Mosaic data augmentation, Self-Adversarial Training, Eliminate grid sensitivity, Using multiple anchors for a single ground truth, Cosine annealing scheduler [52], Optimal hyperparameters, Random training shapes
- Bag of Specials (BoS) for detector: Mish activation, SPP-block, SAM-block, PAN path-aggregation block, DIoU-NMS
Experiments
Influence of different features on Classifier training
Influence of different features on Detector training
Influence of different backbones and pretrained weightings on Detector training
Influence of different mini-batch size on Detector training
we found that after training BoF and BoS training strategies s,the mini-batch has almost no effect on the detector’s performance .