图像超分经典网络 SRGAN 解析 ~ 如何把 GAN 运用在其他视觉任务上
生成对抗网络(GAN)是一类非常有趣的神经网络。借助GAN,计算机能够生成逼真的图片。近年来有许多“AI绘画”的新闻,这些应用大多是通过GAN实现的。实际上,GAN不仅能做图像生成,还能辅助其他输入信息不足的视觉任务。比如SRGAN,就是把GAN应用在超分辨率(SR)任务上的代表之作。
在这篇文章中,我将主要面向深度学习的初学者,介绍SRGAN[1]这篇论文,同时分享以下知识:
- GAN的原理与训练过程
- 感知误差(Perceptual Loss)
- 基于的GAN的SR模型框架
讲完了知识后,我还会解读一下MMEditing的SRGAN的训练代码。看懂这份代码能够加深对SRGAN训练算法的理解。
SRGAN 核心思想
早期超分辨率方法的优化目标都是降低低清图像和高清图像之间的均方误差。降低均方误差,确实让增强图像和原高清图像的相似度更高。但是,图像的相似度指标高并不能代表图像的增强质量就很高。下图显示了插值、优化均方误差、SRGAN、原图这四个图像输出结果(括号里的相似度指标是PSNR和SSIM)。

从图中可以看出,优化均方误差虽然能让相似度指标升高,但图像的细节十分模糊,尤其是纹理比较密集的高频区域。相比之下,SRGAN增强出来的图像虽然相似度不高,但看起来更加清晰。
为什么SRGAN的增强结果那么清楚呢?这是因为SRGAN使用了一套新的优化目标。SRGAN使用的损失函数既包括了GAN误差,也包括了感知误差。这套新的优化目标能够让网络生成看起来更清楚的图片,而不仅仅是和原高清图像相似度更高的图片。
下面,我们来一步一步学习SRGAN的框架。
GAN 的原理
GAN[2]是一套搭建神经网络的框架。给定一个图片数据集 p g p_g pg,GAN的目的是训练出一个生成网络 G G G,使得G能够凭空生成出和 p g p_g pg中大多数图片都类似的图片。比如说 p g p_g pg是一个小猫图片数据集,那么 G G G就应该能凭空生成出小猫图片。当然, G G G不是真的没有任何输入,真的能够凭空生成一幅图片。为了生成出不一样的图片, G G G要求输入一个随机量,这个随机量叫做噪声 z z z。这样,只要输入的噪声 z z z变了, G G G的输出 G ( z ) G(z) G(z)就变了,就能画出长相不一样的小猫了。
为了指导图像生成, G G G应该有一个“老师”告诉它该怎么画出更像的图片。这个“老师”叫做判别网络 D D D。 D D D就是一个二分类网络,它能够严格地判定出一幅图片是否来自数据集 p g p_g pg。如果 p g p_g pg是一个小猫数据集,那么 D D D就应该能判定一张图片是不是小猫。这样,如果 G G G生成出来的图片 G ( z ) G(z) G(z)已经非常逼真,连 D D D都觉得 G ( z ) G(z) G(z)来自数据集 p g p_g pg,那么 G G G就是一个很成功的网络了。
如果只是生成小猫,我们直接拿小猫图片和其他图片就能训练出一个 D D D了。问题是,大多数情况下我们只有数据集 p g p_g pg,而难以获得一个 p g p_g pg的反例数据集。GAN的想法,则巧妙地解决了这个问题:刚开始, G G G生成出来的图片肯定是很差的,这些图片肯定不像 p g p_g pg。所以,我们以 G ( z ) G(z) G(z)为反例,和 p g p_g pg一起训练出一个 D D D来。等 D D D的判定能力强了以后,又拿 D D D回头训练 G G G。这样, D D D的审美水平逐渐提高, G G G的绘画能力也逐渐提高。最终, D D D能成功分辨出一幅图片是否来自 p g p_g pg,而 G G G生成出来的图片和 p g p_g pg中的看起来完全相同,连 D D D也分辨不出来。就这样,我们得到了一个很棒的生成网络 G G G。
规范地来说,给定一个数据集 p g p_g pg,我们希望训练出两个网络 D , G D, G D,G。 D D D能够判断一幅输入图片是否来自 p g p_g pg:
D ( x ) = { 1 x ∈ p g 0 x ∉ p g D(x) = \left\{ \begin{aligned} &1 & x \in p_g \\ &0 & x \notin p_g \end{aligned} \right. D(x)={10x∈pgx∈/pg
G G G则能够根据来自噪声分布 p z p_z pz的 z z z生成一个真假难辨的图片 G ( z ) G(z) G(z),使得 D ( G ( z ) ) = 1 D(G(z))=1 D(G(z))=1。
为了达到这个目标,二分类器 D D D应该最小化这样一个的交叉熵误差:
L ( y ^ , y ) = − ( y l o g y ^ + ( 1 − y ) l o g ( 1 − y ^ ) ) L(\hat{y}, y)=-(y \ log\hat{y} + (1-y) \ log(1-\hat{y})) L(y^,y)=−(y logy^+(1−y) log(1−y^))
其中, y ^ = D ( x ) \hat{y}=D(x) y^=D(x)是预测结果为真的概率, y y y是0或1的标签。
对于来自数据集的图片 x ∼ p g x \sim p_g x∼pg, D D D使用的标签 y y y应该是1,误差公式化简为:
L ( x ) = − l o g D ( x ) , x ∼ p g L(x)=-logD(x), x \sim p_g L(x)=−logD(x),x∼pg
对于 G G G生成的图片 G ( z ) G(z) G(z), D D D使用的标签 y y y应该是0,误差公式化简为:
L ( z ) = − l o g ( 1 − D ( G ( z ) ) ) , z ∼ p z L(z)=-log(1-D(G(z))), z \sim p_z L(z)=−log(1−D(G(z))),z∼pz
我们每步拿一张真图 x x x和一张假图 D ( G ( z ) ) D(G(z)) D(G(z))训练 D D D。这样,每步的误差公式就是上面两个式子加起来:
L D ( x , z ) = − ( l o g D ( x ) + l o g ( 1 − D ( G ( z ) ) ) ) , x ∼ p g , z ∼ p z L_D(x, z)=-(logD(x) + log(1-D(G(z)))), x \sim p_g, z \sim p_z LD(x,z)=−(logD(x)+log(1−D(G(z)))),x∼pg,z∼pz
反过来, G G G应该和 D D D对抗,最大化上面那个误差,想办法骗过 D D D。这个“对抗”就是GAN的名称“生成对抗网络”的由来。但是, G G G不能改变 D ( x ) D(x) D(x)那一项。因此, G G G使用的误差函数是:
L G ( z ) = l o g ( 1 − D ( G ( z ) ) ) , z ∼ p z L_G(z)=log(1-D(G(z))), z \sim p_z LG(z)=log(1−D(G(z))),z∼pz
使用上面这两种误差,就可以训练神经网络了。训练GAN时,每轮一般会训练 k ( k > = 1 ) k(k>=1) k(k>=1)次 D D D,再训练1次 G G G。这是为了先得到一个好的判别器,再用判别器去指导生成器。
GAN只是一套通用的框架,并没有指定神经网络 D , G D, G D,G的具体结构。在不同任务中, D , G D, G D,G一般有不同的结构。
基于GAN的超分辨率网络
如前文所述,以优化均方误差为目标的超分辨率模型难以复原图像的细节。其实,超分辨率任务和图像生成任务类似,都需要一个“老师”来指导优化目标。SRGAN把GAN框架运用到了超分辨率任务上。原来的生成器 G G G随机生成图像,现在用来输出高清图像;原来的判定器 D D D用来判定图像是否属于某数据集,现在 D D D用来判断一幅图像是否是高清图像。
具体来说,相比基础的GAN,在SRGAN中, D D D的输入是高清图像 I H R I^{HR} IHR。而 G G G的输入从随机噪声 z z z变成了高清图像退化后的低清图像 I l R I^{lR} IlR。这样, G G G就不是在随机生成图像,而是在根据一幅低清图像生成一幅高清图像了。它们的误差函数分别是:
L D = − ( l o g D ( I H R ) + l o g ( 1 − D ( G ( I l R ) ) ) ) L G = l o g ( 1 − D ( G ( I l R ) ) ) \begin{aligned} L_D&=-(logD(I^{HR}) + log(1-D(G(I^{lR}))))\\ L_G&=log(1-D(G(I^{lR}))) \end{aligned} LDLG=−(logD(IHR)+log(1−D(G(IlR))))=log(1−D(G(IlR)))
借助GAN的架构,SRGAN能够利用 D D D指导高清图像生成。但是,超分辨率任务毕竟和图像生成任务有一些区别,不能只用这种对抗误差来约束网络。因此,除了使用对抗误差外,SRGAN还使用了一种内容误差。这种内容误差用于让低清图片和高清图片的内容对齐,起到了和原均方误差一样的作用。
基于感知的内容误差
在介绍SRGAN的内容误差之前,需要对“内容误差”和“感知误差”这两个名词做一个澄清。在SRGAN的原文章中,作者把内容误差和对抗误差之和叫做感知误差。但是,后续的大部分文献只把这种内容误差叫做感知误差,不会把内容误差和对抗误差放在一起称呼。在后文中,我也会用“感知误差”来指代SRGAN中的“内容误差”。
在深度卷积神经网络(CNN)火起来后,人们开始研究为什么CNN能够和人类一样识别出图像。经实验,人们发现两幅图像经VGG(一个经典的CNN)的某些中间层的输出越相似,两幅图像从观感上也越相似。这种相似度并不是基于某种数学指标,而是和人的感知非常类似。
VGG的这种“感知性”被运用在了风格迁移等任务上。也有人考虑把这种感知上的误差运用到超分辨率任务上,并取得了不错的结果[3]。下图是真值、插值、基于逐像素误差、基于感知误差的四个超分辨率结果。

SRGAN也使用了这种感知误差,以取代之前常常使用的逐像素均方误差。这种感知误差的计算方法如下:VGG有很多中间层,用于计算感知误差的中间层 i i i是可调的。假如我们用 ϕ i ( I ) \phi_{i}(I) ϕi(I)表示图像 I I I经VGG的第 i i i层的中间输出结果, ϕ i ( I ) x , y \phi_{i}(I)_{x, y} ϕi(I)x,y表示中间输出结果在坐标 ( x , y ) (x, y) (x,y)处的值,则感知误差的公式如下:
L p ( I H R , I L R ) i = 1 W H Σ x = 1 W Σ y = 1 H ( ϕ i ( I H R ) x , y − ϕ i ( G ( I L R ) ) x , y ) 2 L_{p}(I^{HR}, I^{LR})_{i}=\frac{1}{WH}\Sigma_{x=1}^{W}\Sigma_{y=1}^{H}(\phi_{i}(I^{HR})_{x, y}-\phi_{i}(G(I^{LR}))_{x, y})^2 Lp(IHR,ILR)i=WH1Σx=1WΣy=1H(ϕi(IHR)x,y−ϕi(G(ILR))x,y)2
直观上解释这个公式,就是先把高清图像 I H R I^{HR} IHR送入VGG,再把高清图像退化出来的低清图像 I L R I^{LR} ILR送入生成器,并把生成器的输出 G ( I L R ) G(I^{LR}) G(ILR)也送入VGG。两幅图片经VGG第 i i i层生成的中间结果的逐像素均方误差,就是感知误差。
算上之前的对抗误差,一个图像超分辨率网络的总误差如下:
L S R = L p + w L G L_{SR}=L_p + w L_G LSR=Lp+wLG
这里的 w w w用于调整两个误差的相对权重,原论文使用 w = 1 0 − 3 w=10^{-3} w=10−3。
SRGAN的其他模块
定义好了误差函数,只要在决定好网络结构就可以开始训练网络了。SRGAN使用的生成网络和判别网络的结构如下:
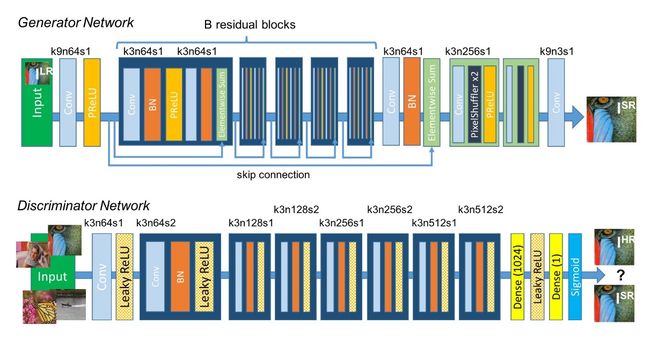
判别网络就是一个平平无奇的二分类网络,架构上没有什么创新。而生成网络则先用几个残差块提取特征,最后用一种超分辨率任务中常用的上采样模块PixelShuffle对原图像的尺寸翻倍两次,最后输出一个边长放大4倍的高清图像。
SRGAN的这种网络结构在当时确实取得了不错的结果。但是,很快就有后续研究提出了更好的网络架构。比如ESRGAN[4]去掉了生成网络的BN层,提出了一种叫做RRDB的高级模块。基于RRDB的生成网络有着更好的生成效果。
不仅是网络架构,SRGAN的其他细节也得到了后续研究的改进。GAN误差的公式、总误差的公式、高清图像退化成低清图像的数据增强算法……这些子模块都被后续研究改进了。但是,SRGAN这种基于GAN的训练架构一直没有发生改变。有了SRGAN的代码,想复现一些更新的超分辨率网络时,往往只需要换一下生成器的结构,或者改一改误差的公式就行了。大部分的训练代码是不用改变的。
总结
SRGAN是把GAN运用在超分辨率任务上的开山之作。如正文所述,SRGAN中的部分设计虽然已经过时,但它的整体训练架构被一直沿用了下来。现在去回顾SRGAN这篇论文时,只需要关注以下几点即可:
- 如何把GAN套用在超分辨率任务上
- GAN误差
- 感知误差
通过阅读这篇论文,我们不仅应该学会GAN是怎样运用在SR上的,也应该能总结出如何把GAN应用在其他任务上。GAN的本质是去学习一个分布,令生成的 G ( z ) G(z) G(z)看上去是来自分布 p g p_g pg,而不是像图像分类等任务去学习一个 x → y x \to y x→y的映射关系。因此,GAN会记忆一些和数据集相关的信息。在输入信息就已经比较完备的图像分类、目标检测等任务中,GAN可能没有什么用武之地。但是,在输入信息不足的超分辨率、图像补全等任务中,GAN记忆的数据集信息有很有用了。很多时候,GAN会“脑补”出输入图像中不够清楚的部分。
决定了要在某个任务中使用GAN时,我们可以在一个不使用GAN的架构上做以下改动:
- 定义一个分类网络 D D D。
- 在原loss中加一项由 D D D算出来的GAN loss。
- 在训练流程中,加入训练 D D D的逻辑。
看完正文后,如果你对GAN在SR上的训练逻辑还是不太清楚,欢迎阅读附录中有关SRGAN训练代码的解读。
附录:MMEditing 中的 SRGAN
MMEditing中的SRGAN写在mmedit/models/restorers/srgan.py这个文件里。学习训练逻辑时,我们只需要关注SRGAN类的train_step方法即可。
以下是train_step的源代码(我的mmedit版本是v0.15.1)。
def train_step(self, data_batch, optimizer):
"""Train step.
Args:
data_batch (dict): A batch of data.
optimizer (obj): Optimizer.
Returns:
dict: Returned output.
"""
# data
lq = data_batch['lq']
gt = data_batch['gt']
# generator
fake_g_output = self.generator(lq)
losses = dict()
log_vars = dict()
# no updates to discriminator parameters.
set_requires_grad(self.discriminator, False)
if (self.step_counter % self.disc_steps == 0
and self.step_counter >= self.disc_init_steps):
if self.pixel_loss:
losses['loss_pix'] = self.pixel_loss(fake_g_output, gt)
if self.perceptual_loss:
loss_percep, loss_style = self.perceptual_loss(
fake_g_output, gt)
if loss_percep is not None:
losses['loss_perceptual'] = loss_percep
if loss_style is not None:
losses['loss_style'] = loss_style
# gan loss for generator
fake_g_pred = self.discriminator(fake_g_output)
losses['loss_gan'] = self.gan_loss(
fake_g_pred, target_is_real=True, is_disc=False)
# parse loss
loss_g, log_vars_g = self.parse_losses(losses)
log_vars.update(log_vars_g)
# optimize
optimizer['generator'].zero_grad()
loss_g.backward()
optimizer['generator'].step()
# discriminator
set_requires_grad(self.discriminator, True)
# real
real_d_pred = self.discriminator(gt)
loss_d_real = self.gan_loss(
real_d_pred, target_is_real=True, is_disc=True)
loss_d, log_vars_d = self.parse_losses(dict(loss_d_real=loss_d_real))
optimizer['discriminator'].zero_grad()
loss_d.backward()
log_vars.update(log_vars_d)
# fake
fake_d_pred = self.discriminator(fake_g_output.detach())
loss_d_fake = self.gan_loss(
fake_d_pred, target_is_real=False, is_disc=True)
loss_d, log_vars_d = self.parse_losses(dict(loss_d_fake=loss_d_fake))
loss_d.backward()
log_vars.update(log_vars_d)
optimizer['discriminator'].step()
self.step_counter += 1
log_vars.pop('loss') # remove the unnecessary 'loss'
outputs = dict(
log_vars=log_vars,
num_samples=len(gt.data),
results=dict(lq=lq.cpu(), gt=gt.cpu(), output=fake_g_output.cpu()))
return outputs
一开始,图像输出都在词典data_batch里。函数先把低清图lq和高清的真值gt从词典里取出。
# data
lq = data_batch['lq']
gt = data_batch['gt']
之后,函数计算了 G ( I l q ) G(I^{lq}) G(Ilq),为后续loss的计算做准备。
# generator
fake_g_output = self.generator(lq)
接下来,是优化生成器self.generator的逻辑。这里面有一些函数调用,我们可以不管它们的实现,大概理解整段代码的意思就行了。
losses = dict()
log_vars = dict()
# no updates to discriminator parameters.
set_requires_grad(self.discriminator, False)
if (self.step_counter % self.disc_steps == 0
and self.step_counter >= self.disc_init_steps):
if self.pixel_loss:
losses['loss_pix'] = self.pixel_loss(fake_g_output, gt)
if self.perceptual_loss:
loss_percep, loss_style = self.perceptual_loss(
fake_g_output, gt)
if loss_percep is not None:
losses['loss_perceptual'] = loss_percep
if loss_style is not None:
losses['loss_style'] = loss_style
# gan loss for generator
fake_g_pred = self.discriminator(fake_g_output)
losses['loss_gan'] = self.gan_loss(
fake_g_pred, target_is_real=True, is_disc=False)
# parse loss
loss_g, log_vars_g = self.parse_losses(losses)
log_vars.update(log_vars_g)
# optimize
optimizer['generator'].zero_grad()
loss_g.backward()
optimizer['generator'].step()
为了只训练生成器,要用下面的代码关闭判别器的训练。
# no updates to discriminator parameters.
set_requires_grad(self.discriminator, False)
正文说过,训练GAN时一般要先训好判别器,且训练判别器多于训练生成器。因此,下面的if语句可以让判别器训练了self.disc_init_steps步后,每训练self.disc_steps步判别器再训练一步生成器。
if (self.step_counter % self.disc_steps == 0
and self.step_counter >= self.disc_init_steps):
if语句块里分别计算了逐像素误差(比如均方误差和L1误差)、感知误差、GAN误差。虽然SRGAN完全抛弃了逐像素误差,但实际训练时我们还是可以按一定比例加上这个误差。这些误差最后会用于训练生成器。
if self.pixel_loss:
losses['loss_pix'] = self.pixel_loss(fake_g_output, gt)
if self.perceptual_loss:
loss_percep, loss_style = self.perceptual_loss(
fake_g_output, gt)
if loss_percep is not None:
losses['loss_perceptual'] = loss_percep
if loss_style is not None:
losses['loss_style'] = loss_style
# gan loss for generator
fake_g_pred = self.discriminator(fake_g_output)
losses['loss_gan'] = self.gan_loss(
fake_g_pred, target_is_real=True, is_disc=False)
# parse loss
loss_g, log_vars_g = self.parse_losses(losses)
log_vars.update(log_vars_g)
# optimize
optimizer['generator'].zero_grad()
loss_g.backward()
optimizer['generator'].step()
训练完生成器后,要训练判别器。和生成器的误差计算方法类似,判别器的训练代码如下:
# discriminator
set_requires_grad(self.discriminator, True)
# real
real_d_pred = self.discriminator(gt)
loss_d_real = self.gan_loss(
real_d_pred, target_is_real=True, is_disc=True)
loss_d, log_vars_d = self.parse_losses(dict(loss_d_real=loss_d_real))
optimizer['discriminator'].zero_grad()
loss_d.backward()
log_vars.update(log_vars_d)
# fake
fake_d_pred = self.discriminator(fake_g_output.detach())
loss_d_fake = self.gan_loss(
fake_d_pred, target_is_real=False, is_disc=True)
loss_d, log_vars_d = self.parse_losses(dict(loss_d_fake=loss_d_fake))
loss_d.backward()
log_vars.update(log_vars_d)
optimizer['discriminator'].step()
这段代码有两个重点:
- 在训练判别器时,要用
set_requires_grad(self.discriminator, True)开启判别器的梯度计算。 fake_d_pred = self.discriminator(fake_g_output.detach())这一行的detach()很关键。detach()可以中断某张量的梯度跟踪。fake_g_output是由生成器算出来的,如果不把这个张量的梯度跟踪切断掉,在优化判别器时生成器的参数也会跟着优化。
函数的最后部分是一些和MMEditing其他代码逻辑的交互,和SRGAN本身没什么关联。
self.step_counter += 1
log_vars.pop('loss') # remove the unnecessary 'loss'
outputs = dict(
log_vars=log_vars,
num_samples=len(gt.data),
results=dict(lq=lq.cpu(), gt=gt.cpu(), output=fake_g_output.cpu()))
return outputs
只要理解了本文的误差计算公式,再看懂了这段代码是如何训练判别器和生成器的,就算是完全理解了SRGAN的核心思想了。
参考资料
[1] (SRGAN): Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
[2] (GAN): Generative Adversarial Nets
[3] (Perceptual Loss):Perceptual Losses for Real-Time Style Transfer and Super-Resolution
[4] (ESRGAN): ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks