从零理解熵、交叉熵、KL散度
大家或许在课本或故事里接触过“熵”这个概念:“熵表示混乱程度。熵只会越变越多,熵增会让宇宙最终走向灭亡”。“熵”也常常出现在机器学习的概念中,比如分类任务会使用到一种叫做“交叉熵”的公式。
那么,“熵”究竟是什么呢?熵的数学单位和意义并没有生活中的其他事物那么直观。我们可以说一元一元的钱、一吨一吨的铁、一升一升的水,却很难说出一单位的熵表示什么。在这篇文章里,我会从非常易懂的例子中引入熵这个概念,并介绍和熵相关的交叉熵、相对熵(KL散度) 等概念,使大家一次性理解熵的原理。
熵的提出——尽可能节省电报费
假设现在是一个世纪以前,人们用电报来传输信息。为了刊登天气预报,报社每天会从气象中心接收电报,获知第二天的天气。这样的电报应该怎么写呢?
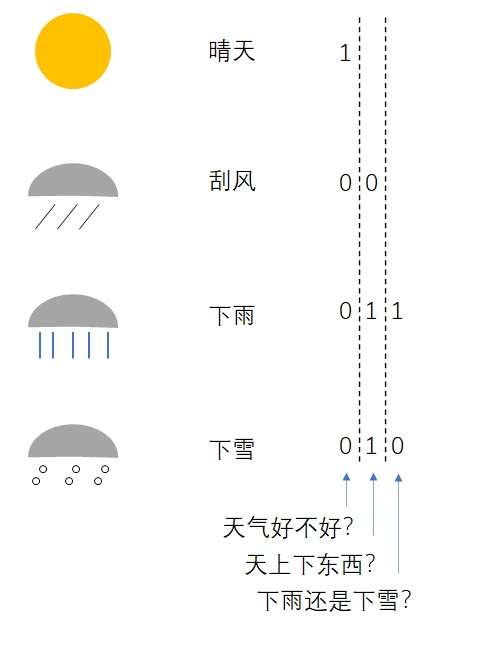
我们先假设明天的天气只有“好”和“坏”两种情况。好天气,就是晴天或多云;坏天气,就是刮风或下雨。这样,电报就可以写成“明天天气很好”或者“明天天气不好”。

这种电报的描述确实十分清楚。但是,电报是要收费的——电报里的字越多,花费的钱越多。为了节约成本,我们可以只在电报里写一个字。天气好,就发一个“好”;天气差,就发一个“坏”。由于报社和气象中心已经商量好了,这一条电报线只用来发送明天的天气这一种信息,所以“好”和“坏”只是指代明天的天气,不会有任何歧义。通过这种方式,发电报的成本大大降低了。
但是,这种方式还不是最省钱的。通讯其实使用的是二进制编码。比如如果用两个二进制位,可以表示00, 01, 10, 11这种不同的信息。而汉字有上万个,为了区分每一个汉字,一般会使用16个二进制位,以表示个不同的汉字。要传输一个汉字,就要传输16个0或1的数字。而要表示明天的天气,最节省的情况下,只要一个二进制位就好了——0表示天气不好,1表示天气很好。

这样,我们得出了结论:最节省的情况下,用1位二进制数表示明天的天气就行了。1位二进制数有单位,叫做比特(bit)。因此,我们还可以说:明天天气的熵是1比特。没错,熵的意思就是最少花几比特的二进制数去传递一种信息。发明出“熵”的人,很可能正在思考怎么用更短的编码去节省一点电报费。
熵与平均编码长度
明天的天气只有两种可能:好、坏。这一情况太简单了,以至于我们可以脱口而出:这个问题的熵是1。
可当问题更复杂、更贴近实际时,熵的计算就没那么简单了。明天的天气,可能有4种情况:

这个问题的熵是多少呢?
刚刚我们也看到了,1个二进制数表示2种情况,2个二进制数表示4种情况。现在有4种情况,只要两位编码就行了:

因此,这个问题的熵是2。
但有人可能对这种编码方式感到不满:“这种编码太乱了,每个二进制位都没有意义。我有一种更好的编码方式。”
确实如此。要表示四种情况,不是非得用2位的编码,而可以用1-3位的编码分别表示不同的信息。可是,这两种方案哪个更节省一些呢?我们不能轻易做出判断。假如大部分时候都是晴天,那么用第二种方案的话很多时候只需要1位编码就行了;而假如大部分时候都是下雨或下雪,则用第一种方案会更好一些。为了判断哪种方案更好,我们还缺了一个重要的信息——每种天气的出现概率。
假如我们知道了每种天气的出现概率,就可以算出某种编码的平均编码长度,进而选择一种更优的编码。让我们看一个例子。假设四种天气的出现概率是80%/10%/5%/5%,则两种编码的平均长度为:
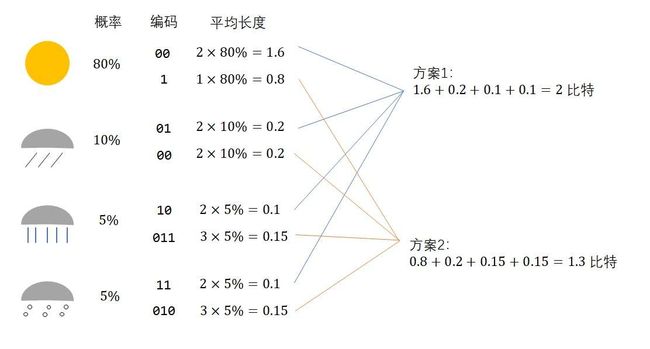
用每种天气的出现概率,乘上每种天气的编码的长度,求和,就可以算出该编码下表示一种天气的平均长度。从结果来看,第二种编码更好一些。事实上,第二种编码是这种概率分布下最短的编码。
只有四种天气,我们还可以通过尝试与猜测,找出最好的编码。可是,如果天气再多一点,编码方式就更复杂了。想找出最好的编码就很困难了。有没有一种能够快速知道最优平均编码长度的方式呢?
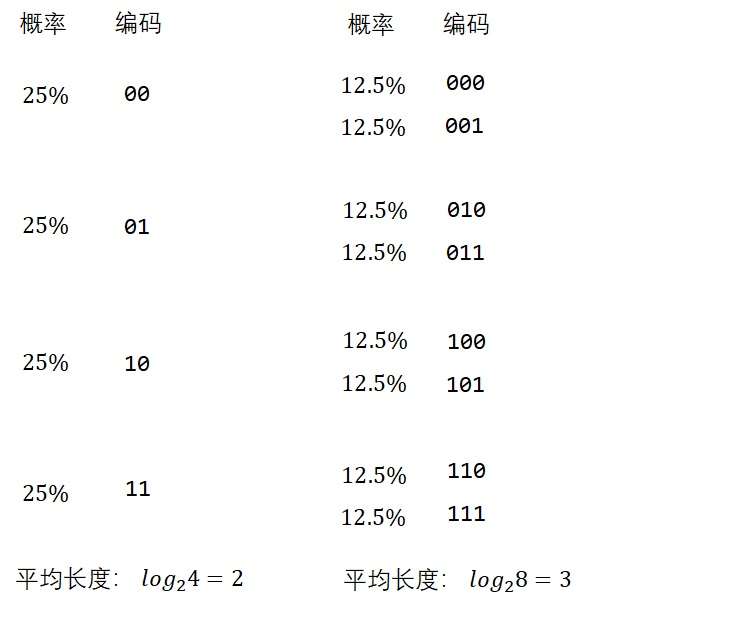
让我们从简单的例子出发,一点一点找出规律。假如四种天气的出现概率都是25%,那问题就很简单了,直接令每种天气的编码都是2位就行了。由于每种天气的出现概率都相等,让哪种天气的编码长一点短一点都是不合理的。类似地,假如有八种天气,每种天气的概率都是12.5%,那么应该让每种天气都用3位的编码。
这里的“2位”、“3位”是怎么算出来的呢?很简单,对总的天气数取对数即可。有4种天气,就是;有8种天气,就是。
现在,让问题再稍微复杂一点。假如还是晴天、刮风、下雨、下雪这四种天气,每种天气的概率都是25%。现在,报社觉得区分下雨和下雪太麻烦了,想把下雨或下雪当成一种出现概率为50%的天气来看待。这种情况下的最优编码是什么呢?
原来下雨的编码是10,下雪的编码是11。既然它们合并了,把编码也合并一下就行。10和11,共同点是第一位都是1。因此,合并后的编码就是1。这样,我们可以得到新问题下的编码方案。刚刚的四种天气均分的编码方案是最优的,那么这种把两种编码合并后的方案也是最优的。

晴天和刮风的编码长度是2。这个很好理解。25%是4种天气平均分的概率,因此编码长度是。下雨/下雪的编码长度是1,这个又是怎么得到的呢?50%,可以认为是2种天气平均分的概率,这时的编码长度是。
由于一般我们只知道每种天气的概率,而不太好算出每种天气被平均分成了几份。因此,我们可以把上面两个对数运算用概率来表达。
更一般地,假设某种天气的出现概率是。我们可以根据规律猜测,当这种天气的编码长度是时,整个编码方案是最优的。事实上,这个猜测是正确的。
我们来算一下最优编码方案下的平均编码长度,看看每次接收天气预报的电报平均下来要花几个比特。假设第种天气的出现概率是,那么最优平均编码长度就是:
这就是我们经常见到的熵的计算公式了。没错,上一节我们对于熵的定义并不是那么准确。熵其实表示的是理想情况下,某个信息系统的最短平均编码长度。
在这个公式里,由于被累加的情况是离散的,我们使用了求和符号。对于连续的情况,要把求和变成求积分。
这个定义有几个要注意的地方。首先,熵是针对某个信息系统的平均情况而言的。这说明,用熵来描述的信息必须要能够分成许多种,就像很多种天气一样。同时,每种具体的信息都得有一个出现概率。我们不是希望让某一次传输信息的编码长度最短,而是希望在大量实验的情况下,令平均编码长度最短。
另外,为什么要说“理想情况下”呢?试想一下,假如有6种天气,每种天气的出现概率相等。这样,每种天气都应该用位编码来表示。可是,并不是一个整数。实际情况中,我们只能用2~3位编码来表示6种天气。由于编码长度必须是整数,这种最优的编码长度只是说理论上成立,可能实际上并不能实现。
求解最优整数编码的算法叫做“哈夫曼编码”,这是一个经典的算法题。感兴趣的话可以查阅有关资料。
推而广之,熵除了指编码长度这种比较具体的事物以外,还可以表示一些其他的量。这个时候,“编码长度”就不一定是一个整数了,算出来的熵也就更加有实际意义。因此,与其用“无序度”、“信息量”这些笼统的词汇来概括熵,我们可以用一些更具体的话来描述熵:
对于一个信息系统,如果它的熵很低,就说明奇奇怪怪的信息较少,用少量词汇就可以概括;如果它的熵很高,就说它包括了各式各样的信息,需要用更精确的词汇来表达。
最后,再对熵的公式做一个补充。一般情况下,算熵时,对数的底不是2,而是自然常数e。由换底公式
可知,对数用不同的底只是差了一个常数系数而已,使用什么数为底并不影响其相对大小。在使用熵时,我们也只关心多个熵的相对大小,而不怎么会关注绝对数值。
以2为底时,熵的单位是比特。以e为底时,熵的单位是奈特(nat)。
用交叉熵算其他方案的平均编码长度
理解了熵的概念后,像交叉熵这种衍生概念就非常好理解了。在学习所有和熵有关的概念时,都可以把问题转换成“怎么用最节省的编码方式来描述天气”。
假设电报员正在和气象中心商量天气的编码方式。可是,这个电报员刚来这个城市不久,不知道这里是晴天比较多,还是下雨比较多。于是,对于晴天、刮风、下雨、下雪这四种天气,他采用了最朴素的平均法,让每种天气的编码都占2位。
大概100天后,电报员统计出了每种天气的出现频率。他猛然发现,这个城市大部分时间都在下雨。如果让下雨的编码只占1位,会节省得多。于是,他连忙修改了编码的方式。
这时,他开始后悔了:“要是早点用新的编码就好了。两种方案的平均编码长度差了多少呢?”假设各种天气的出现概率如下,我们可以计算出新旧方案的平均编码长度。

就像计算熵一样,我们来用公式表示一下这个不那么好的平均编码长度。之前,电报员为什么会都用2位来表示每一种天气?这是因为,他估计每种天气的出现概率都是25%。也就是说,在算某一个实际概率分布为的信息系统时,我们或许用了概率分布去估计。在刚刚那个问题里,就表示所有天气的出现概率相等,就是雨天较多的那个实际概率分布。这样,较差的平均编码长度计算如下:
这是不是和熵的公式
很像?没错,这就是交叉熵的公式。交叉熵表示当你不知道某个系统的概率分布时,用一个估计的概率分布去编码得到的平均编码长度。表示的是每一条信息的编码长度,由于编码长度是由我们自己决定的,只能用估计的分布来算,所以它里面用的是这个分布。而算期望时,得用真实的概率分布。因此,这个式子外面乘上的是。
交叉熵有一个很重要的性质:交叉熵一定不大于熵。熵是最优的编码长度,你估计出来的编码方案,一定不会比最优的更好。所有交叉熵的应用基本上都是利用了这一性质。
在机器学习中,我们会为分类任务使用交叉熵作为损失函数。这正是利用了交叉熵不比熵更大这一性质。让我们以猫狗分类为例看看这是怎么回事。
在猫狗分类中,我们会给每张图片标一个one-hot编码。如果图片里是猫,编码就是[1, 0];如果是狗,编码就是[0, 1]。one-hot编码,其实就是一个概率分布,只不过某种事件的出现概率是100%而已。可以轻松地算出,one-hot编码的熵是0。
机器学习模型做分类任务,其实就是在估计的one-hot编码表示的概率分布。模型输出的概率分布就是交叉熵公式里的,实际的概率分布,也就是one-hot编码,就是交叉熵公式里的。由于熵是0,交叉熵的值一定大于等于0。因此,交叉熵的值可以表示它和熵——最优的概率分布的信息量——之间的差距。
用KL散度算方案亏了多少
用交叉熵算出旧方案的平均编码长度后,电报员打算统计一下旧编码浪费了多少编码量。既然熵是最优编码的编码长度,那么交叉熵减去熵就能反映出旧编码平均浪费了多少编码长度。这个计算过程如下:

可以总结出,如果我们还是用分布去估计分布的的话,则这其中损失的编码量可以用下面的公式直接计算。
这个公式描述的量叫做相对熵,又叫做KL散度。KL散度的定义非常易懂,它只不过是交叉熵和熵的差而已,反映了一个分布与另一个分布的差异程度。最理想情况下,,则KL散度为0。
当然,KL散度不是一个距离指标。从公式中能够看出,,这个指标并不满足交换律。
KL散度常用来描述正态分布之间的差异。比如VAE(变分自编码器)中,就用了KL散度来比较估计的分布和标准正态分布。计算正态分布间的KL散度时,我们不用从头推导,可以直接去套一个公式。
设一维正态分布的公式如下:
则KL散度为:
在看计算机方向的论文时,如果碰到了KL散度,我们不需要深究其背后的数学公式,只需要理解KL散度的原理,知道它是用来做什么的即可。
总结
在各个学科中,都能见到“熵”的身影。其实,大部分和熵有关的量都是在最基本的熵公式之上的拓展。只要理解了熵最核心的意义,理解其他和熵相关的量会非常轻松。希望大家能够通过这篇文章里的例子,直观地理解熵的意义。
参考资料
我的这篇文章基本照抄了三篇介绍熵的文章。这三篇文章写得非常易懂,强烈推荐阅读。
Entropy Demystified
Cross-Entropy Demystified
KL Divergence Demystified
有关KL散度的推导可以参见这篇博文:
KL散度(Kullback-Leibler Divergence)介绍及详细公式推导