目标检测数据集标注-VOC格式
目录
一、了解Voc数据格式
1. Anotations目录
2. JPEGImages目录
3. ImageSets目录
二、自己标准目标检测数据
1. 安装标注工具
2. 配置环境
3. 创建文件夹
4. 标注数据
深度学习工程师在数据标注上是必不可少的内容之一。
-
一、了解Voc数据格式
利用深度学习方法如Faster R-CNN或YOLOv3等进行目标检测时需要训练数据集,我们很少会根据自己的数据集格式修改代码,更多的是按照一定格式修改自己的数据格式,而PASCAL VOC为图像识别和分类提供了一整套标准化的数据集,为了方便我们目标检测的进行,可以先来详细的记录一下PASCAL VOC的格式。
Pascal VOC数据集下载地址:The PASCAL Visual Object Classes Homepage
数据集下载后解压得到一个名为VOCdevkit的文件夹,该文件夹结构如下:

1. Anotations目录
目录存放xml文件:
Annotations文件夹中存放的是xml格式的标签文件,每一个xml文件都对应于JPEGImages文件夹中的一张图片,包含了图片的重要信息:图片的名称,图片中object的类别及其bounding box坐标。
内容如下:
VOC2007
000051.jpg
The VOC2007 Database
PASCAL VOC2007
flickr
291539949
kristian_svensson
Kristian Svensson
500
375
3
0
其中重要字段解析如下:
| 标签 |
解释 |
| filename |
文件名 |
| source |
图像来源(不重要) |
| size |
图像尺寸(长宽以及通道),包含了width,height和depth |
| segmented |
是否用于分割 |
| object |
需检测到的物体,包含了物体名称name,拍摄角度pose,是否截断truncated,难以识别difficult,object对应的bounding box信息 bndbox |
| bndbox |
包含左下角和右上角x,y坐标 (xmin,ymin,xmax,ymax |
以下程序可以将XML标签中目标绘制在图像中,具体步骤为:
1.用xml.etree.ElementTree库中的parse方法解析xml文件;
2.获取xml文件的根节点;
3.寻找object节点用find() 和findall(), .text表示获取节点中的内容;
4.cv2绘图,rectangle画框,putTEXT标注类别。
代码:
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os,cv2
xml_file='Annotations/000282.xml'
tree=ET.parse(xml_file)
root=tree.getroot()
imgfile='JPEGImages/000282.jpg'
im = cv2.imread(imgfile)
for object in root.findall('object'):
object_name=object.find('name').text
Xmin=int(object.find('bndbox').find('xmin').text)
Ymin=int(object.find('bndbox').find('ymin').text)
Xmax=int(object.find('bndbox').find('xmax').text)
Ymax=int(object.find('bndbox').find('ymax').text)
color = (4, 250, 7)
cv2.rectangle(im,(Xmin,Ymin),(Xmax,Ymax),color,2)
font = cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(im, object_name, (Xmin,Ymin - 7), font, 0.5, (6, 230, 230), 2)
cv2.imshow('01',im)
#cv2.imwrite('02.jpg', im)2. JPEGImages目录
存放的是数据集的原图片,像素尺寸大小不一。
3. ImageSets目录
ImageSets存放的是每一种计算机视觉任务类型所对应的文件夹,各个文件夹均存放txt格式文件,txt中记录图片名:
| 文件夹 |
数据信息 |
| Layout |
具有人体部位的数据 |
| Main |
一般存放图像物体识别的数据 |
| Segmentation |
用于语义,实例分割的数据 |
目标检测主要用到Main文件夹中的txt文件(训练自己的数据时,我们需要自己生成):
| 文件夹 |
数据信息 |
| train |
训练使用的图片名称(无后缀) |
| val |
验证使用的图片名称(无后缀) |
| trainval |
以上两者的合并 |
| test |
测试使用的图片名称(无后缀) |
-
二、自己标准目标检测数据
1. 安装标注工具
数据标注工具labelImg,可以通过可视化的操作界面进行画框标注,就能自动生成VOC格式的xml文件,该工具是基于Python语言编写的,这样就支持在Windows、Linux的跨平台运行。
下载地址为:https://github.com/tzutalin/labelImg
解压,得到LabelImg-master文件夹:
2. 配置环境
安装说明:
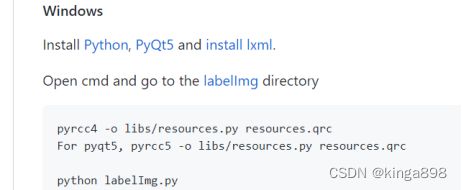
终端进入LabelImg-master 目录下 ,依次执行如下命令即可
# 更新源
python.exe -m pip install --upgrade pip
# 安装qt5:
pip install pyqt5 lxml
# 加载资源
pyrcc5 -o libs/resources.py resources.qrc
# 启动软件
python labelImg.py
3. 创建文件夹
按照VOC数据集的要求,创建以下文件夹:
(1)Annotations:用于存放标注后的xml文件;
(2)ImageSets/Main:用于存放训练集、测试集、验收集的文件列表;
(3)JPEGImages:用于存放原始图像;

4. 标注数据
将源图片集放在JPEGImages文件夹里面,注意图片的格式必须是jpg格式的。打开labelImg标注工具,然后点击左侧的工具栏“Open Dir”按钮,选择刚才放猫的JPEGImages文件夹。这时,主界面将会自动加载第一张猫照片。
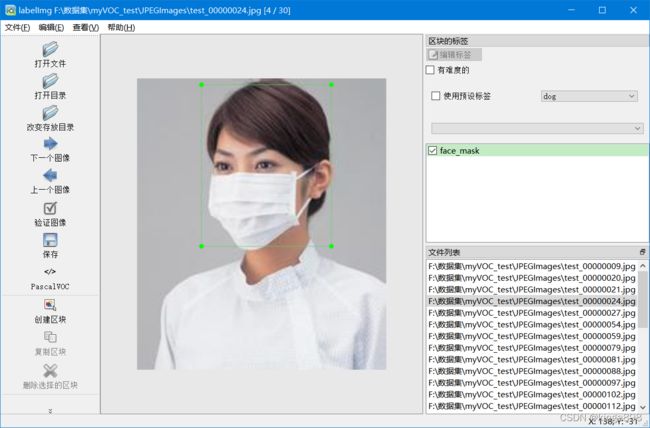
点击左侧工具栏的“Create RectBox”按钮,然后在主界面上点击拉个矩形框,将猫圈出来。
圈定后,将会弹出一个对话框,用于输入标注物体的类别,这里输入cat作为object类别。
然后点击左侧工具栏的“Save”按钮,选择刚才创建的Annotations作为保存目录,系统将自动生成VOC2007格式的xml文件保存起来。这样就完成了一张猫照片的物体标注了。
接下来点击左侧工具栏的“Next Image”进入下一张图像,按照以上步骤,画框、输入名称、保存,如此反复,直到把所有照片都标注好,保存起来。
保存在Anotations目录下图片名字对应的xml文件上,内容如下:
JPEGImages
test_00000024.jpg
F:\数据集\myVOC_test\JPEGImages\test_00000024.jpg
Unknown
188
220
3
0