ExpMRC: Explainability Evaluation for Machine ReadingComprehension
题目:ExpMRC:机器阅读理解的可解释性评估
作者:Yiming Cui, Ting Liu, Wanxiang Che, Zhigang Chen, Shijin Wang
发布地方:arXiv
面向任务:阅读理解类问答
论文地址:https://arxiv.org/abs/2105.04126
论文代码:GitHub - ymcui/expmrc: ExpMRC: Explainability Evaluation for Machine Reading Comprehension
摘要
强大的预训练语言模型(PLMs,Pre-trained Language Models)在一些机器阅读理解(Machine Reading Comprehension,MRC)数据集上的性能已经达到了人类水平。然而对于现实应用,在给出答案的同时有必要给出答案的推理过程,目的可以进一步提高MRC系统的可靠性。
本文中提出了一个名为ExpMRC的新基准(benchmark)[1],用于评估MRC系统的可解释性。ExpMRC包含四个子集,包括SQuAD、CMRC 2018、RACE+和C3以及答案推理句的附加标注。MRC系统不仅要给出正确答案,还要给出解释。
[1]我的理解benchmark(基准)在这里表示为最有代表性且被广泛认可的一种标准和规则,即评估MRC系统的可解释性,其所用的ExpMRC数据集就是benchmark data,后边用的方法Predicted Answer Sent、Pseudo-datatraining等都是benchmark method。另外baseline(基线)的意思是与你提出的算法或模型进行对比的东西,比如22年张三提出一种新的评估MRC可解释性的模型A,这时候会选择用该文作者的Predicted Answer Sent、Pseudo-data training等作为基线,与张三的A模型进行对比,结果发现效果很好,后来到了23年,李四提出一种新的评估MRC可解释性的模型B,这时候可能会选择用张三的A模型进行对比,那么这时张三的A模型就是基线。
1 介绍
机器阅读理解是一项要求机器阅读和理解给定段落并回答问题的任务,在过去几年中受到了广泛关注。尽管在一些MRC数据集上,最先进的系统借助预先训练的语言模型达到人类的性能,这些系统的可解释性仍然不确定。仅给出最终预测的答案无法说服用户,因为这些结果缺乏解释性。于是,可解释人工智能(Explainable Artificial Intelligence,XAI)近年来受到了前所未有的关注。XAI的目标是产生更多可解释的机器学习模型,同时保持模型输出的高精度,并让人类了解其内在机制。
为了更好地评估MRC模型的可解释性,本文提出了一种用于多语言(汉语、英语)和多任务机器阅读理解(片段(span)抽取,多项选择)的综合基准(benchmark)ExpMRC,它评估了答案及其解释的准确性。ExpMRC包含四个子集,包括SQuAD、CMRC 2018、RACE+和C3,其都有对答案推理的附加标注。MRC模型不仅要给出答案,还应给出推理句作为证据。
生成的数据集包含11K(11000)个人类标注的推理句,涵盖4K(4000)个问题。本文的贡献如下。
①提出了一个新的MRC基准(benchmark),称为ExpMRC,其目的是评估最终答案预测的准确性及其解释。
②提出了几个适用于ExpMRC的无监督方法。
③在ExpMRC上的实验结果表明,当前预训练的语言模型在解释预测答案方面仍远不能令人满意,这表明所提出的ExpMRC具有挑战性,ExpMRC存在较大的进步空间。
2 相关工作
机器阅读理解一直被视为测试机器对人类语言理解程度的一项重要任务。在早期阶段,由于大多数模型仅根据每个数据集的训练数据进行训练,而没有太多先验知识,因此它们的表现并不令人印象深刻。然而,随着这些年中出现的预训练语言模型,如BERT、RoBERTa、ELECTRA等,许多系统可以在多个MRC数据集(如SQuAD 1.1和2.0)上实现比普通人类更好的性能。
在达到“过度人性化”的表现之后,还有一个问题需要解决。这些决策过程和解释仍然不清楚,这引发了人们对其可靠性的担忧。在这种背景下,XAI变得比以往任何时候都重要,不仅在NLP中,而且在人工智能的各个方向上。然而,大多数前沿系统都是在神经网络上开发的,这些方法的可解释性研究非常重要,这仍然是一个正在进行的研究课题。
在NLP中,一些研究人员进行了分析,以更好地理解基于BERT架构的内部机制。例如,Kovaleva等人发现,多头注意机制中不同头部之间存在重复的注意模式,表明其过度参数化。但也许最热门的讨论是,人们的注意力是否可以解释。一些研究人员认为,注意力不能作为解释,如Jain和Wallace(2019)证实,使用完全不同的注意力权重也可以实现相同的预测。相反,一些工作对这一主题持积极态度。这些工作给我们带来了基于注意力的模型的不同观点,但对于这一重要话题仍然没有共识。
在MRC中,在可解释性方面最相关的工作是HotpotQA的创建,这是一个多跳可解释的问答数据集。HotpotQA要求机器检索相关文档,并提取一段span作为答案,以及它的证据句子。已经提出了多种模型,以使用带有标记的训练数据的监督学习方法来解决这一任务。然而,不幸的是,几乎所有的工作都专注于在基准(benchmark)测试中获得更高的分数,而没有特别关注解释性。
最重要的是,尽管已经做出了各种努力,可解释性是所有机器阅读理解任务和不同语言的普遍需求,但不仅限于英语多跳QA。另一个问题是,为每个任务注释证据是不可行的,应该寻求无监督的方法,其不依赖任何注释的证据来最小化人工成本。
在此背景下,本文提出的ExpMRC特别关注评估四项任务的可解释性,包括中英文的(片段提取和多项选择MRC)。ExpMRC不提供带注释的训练数据,旨在迫使团队专注于设计无监督方法,以提高其在不同MRC任务甚至不同语言中的通用性。ExpMRC是多任务和多语言环境下的第一个MRC基准,不仅可用于解释性评估,还可用于其他各种方向,如跨语言研究等。
3 ExpMRC
3.1 子集选择
本文数据集的目的是提供一个综合的MRC基准(benchmark),不仅评估预测的准确性,而且评估其解释效果。本文采用了几个已经存在的MRC数据集以及新的数据来形成ExpMRC数据集。ExpMRC由以下数据集组成,包括两个片段抽取MRC数据集和一个多项选则MRC数据。
①SQuAD是片段抽取MRC数据集(英文)。即给定一个维基百科段落,MRC系统应该提取一个段落中的片段(字串)作为问题的答案。
②CMRC 2018也是一个片段抽取MRC数据集(中文)。除了传统的训练/开发/测试,本文还发布了一个挑战集,该挑战集需要多跳推理。
③C3是一个多项选择MRC数据集(中文)。系统在阅读文章和问题后选择正确的选项作为答案。
④作者团队有一些内部收集的多项选择MRC数据,它类似于RACE(为中学生设计的题库),另外这些数据包含回答问题的附加推理句。因此,将这个新子集表示为RACE+。
上述数据集示例如表1所示:

表1,ExpMRC中的示例。答案和正确选项的推理句用粗体标记,答案片段用蓝色标记。
接下类,为四个子集进行答案推理句的注释。
3.2 证据注释
有些问题答案的推理句是无法注释或者说注释的意义不大,例如:
①答案片段是问题和答案的简单组合,没有太多句法或语义差异。
②问题需要外部知识解决,不能仅从文章中推断。
③整篇文章的结论性问题,如“这篇文章的最佳标题是什么?,这篇文章的主旨是什么”等。
将这些问题去除后进行注释。首先,注释者需阅读问题和正确答案;然后,他们应该从文章中选择(复制并粘贴)一段可以作为答案推理的段落。推理句尽量是能够支持答案的最小段落片段,不应该总是完整的句子或子句(意思是这句话能回答问题且长度最短)。并鼓励注释者选择需要推理技巧的证据,尽管这在这些数据集中不是常见的情况,尤其是在片段提取MRC中(大多数问题不需要推理)。
3.3 质量保证
对于所有类型的MRC数据,注释每个推理句的报酬约为0.5美元。注释者是来自中国的英语专业或中文专业的研究生,具体取决于数据集的语言。此外,为了避免过度工作和降低注释质量,设置了每日注释数量的硬性限制。达到极限(300)后,系统将自动锁定,并将在第二天解锁。
由于本文的数据集每个问题有两个或多个可供参考的推理句,因此不会向当前注释者显示已注释的推理句,以增加多样性并避免复制和粘贴行为。在初步注释之后,逐一检查所有推理句,以最大限度地确保高质量数据集。最后,效果就是只需阅读推理句和问题就能找出正确答案,以确保注释有效。
3.4 统计
表2列出了提出的ExpMRC的统计数据。注意,表2中的“token”表示中文字符和英文单词(中文文本的话表示一个字或者一个中文标点符号,英文文本的话表示一个英文单词或者一个英文的标点符号)。对于所有子集,为每个问题提供2-4个可供参考的推理句。问题类型在每个任务开发集中的分布如图1所示:RACE+和C3中关于“who、when、where”的问题较少,这表明这些子集要困难得多。
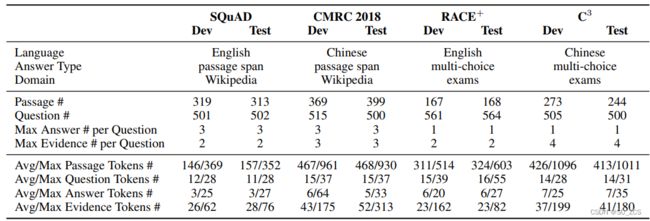
表2:提出的ExpMRC的统计数据。
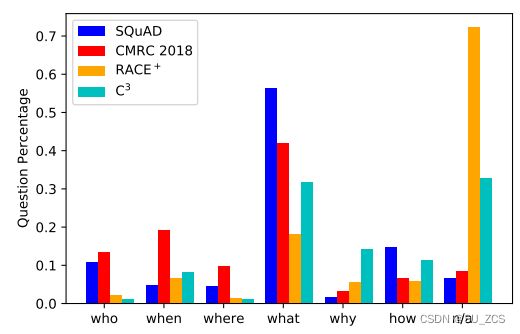
图1:问题类型分布。
4 基线
鉴于提出的ExpMRC旨在评估系统解释文本的可解释性,本文主要关注基线系统的无监督方法2。使用预先训练的语言模型作为主干(backbones)[2]来生成问题的答案。然后,应用几种方法来生成推理句,并将其分为非学习基线和机器学习基线。
[2] 自己的方法可以是在这个主干网络(例如AlexNet、VGG、ResNet等)上进行一些组件的添加,或者与其他网络进行组合。
4.1 非学习基线
使用预测答案和问题作为寻找推理句的线索,只考虑在这些基线中提取句子级别的推理句,尽管基本事实可能并不总是一个完整的句子。首先用“.!?”把这段话分成几个句子作为分隔符。然后选择其中一个句子作为推理句。为了找到更准确的证据,采用了三种方法。
①最相似的句子(MostSimilar Sentence):计算预测答案片段(或选择文本)和每个段落句子之间的token级F1分数。然后选择F1最高的句子作为推理句预测。
②加上问题的最相似句子(MostSimilar Sentence with Question):类似于“最相似句子”设置,使用问题文本和预测答案作为查找最相似段落句子的关键。
③答案句子(AnswerSentence):直接提取包含答案预测的句子作为证据。
这些方法在很大程度上依赖于答案预测的准确性,因为错误的预测将直接影响推理句的查找过程。
4.2 机器学习基线
由于ExpMRC中没有提供训练数据,本文使用伪训练方法(pseudo-trainingapproach)来实现机器学习基线系统。使用真实答案和问题文本来找到最相似的段落句子作为伪推理句,以形成伪训练数据。
然后,使用伪训练数据和PLM来训练(答案预测和推理句预测)的模型。具体来说,在原始答案预测任务的基础上,在PLM的最终隐藏表示之上添加了一个额外的任务头作为推理句预测,如图2所示。
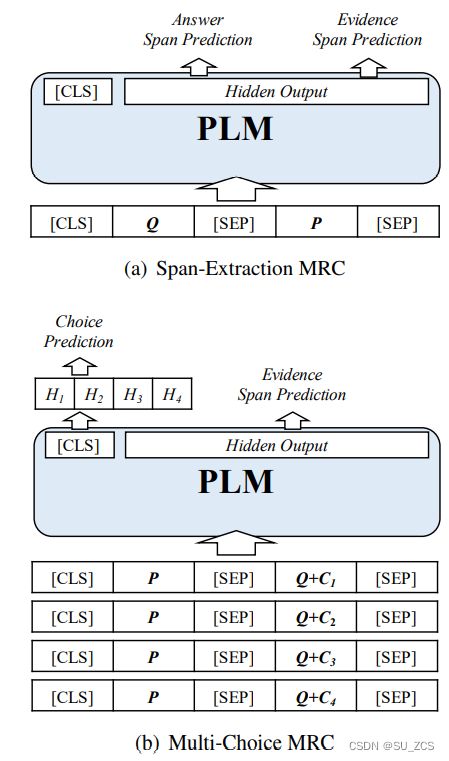
图2:基线的神经网络架构。
①片段抽取MRC:问题和段落串联后被输入PLM,使用具有两个全连接层的最终隐藏表示来预测答案片段的开始和结束位置。
②多项选择MRC:段落、问题和每个选项的串联后被输入PLM,以获得四个集合表示(假设有四个候选选择)。然后使用softmax激活的全连接层来预测最终选项。
ps,pe∈Rn是预测答案开始和结束位置的概率。然后,计算推理句预测的开始和结束位置的标准交叉熵损失。

最终训练损失是答案预测损失LA和推理句预测损失LE之和,λ∈[0,1]。
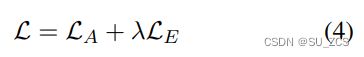
5 评估方法
5.1 评估指标
对于答案评估,使用F1来评估SQuAD和CMRC 2018。对于RACE+和C3,我们使用精确率(Accuracy)进行评估。
对于推理句评估,使用F1。
另外,还提供了一个总体F1指标,以对系统进行全面评估。对于每个实例,计算答案度量和推理句度量的得分。每个实例的总F1通过将两个项相乘而获得。最后,通过平均所有实例级别F1来获得所有实例的总体F1。
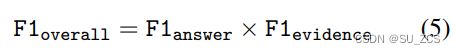
6 实验
6.1 设置
表3 实验设置
参数、任务 |
值、模型 |
中文任务 |
MacBERT base/large |
英文任务 |
BERT-base和BERT-large-wwm |
初始学习率 |
3e-5 |
Epoch |
2 |
最大序列长度 |
512 |
问题长度 |
128 |
优化器 |
ADAM和权重衰减 |
Lambda |
0.1 |
6.2 基准结果
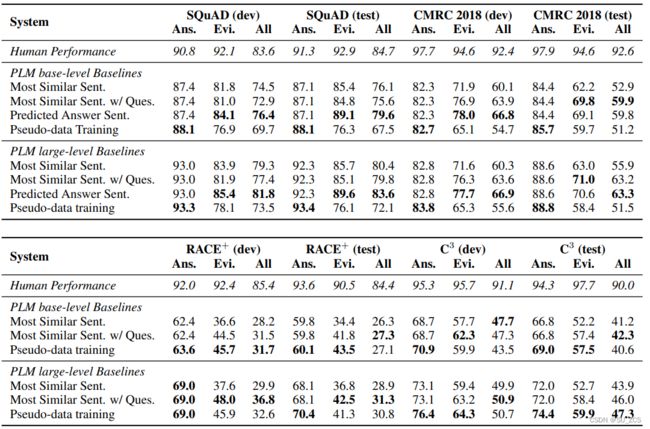
表4:SQuAD、CMRC 2018、RACE+和C3的基线结果
①性能最佳的基线仍然远远落后于人类的性能,这表明所提出的数据集具有挑战性。
②多项选择MRC子集中的差距大于片段抽取MRC中的差距。
③对于所有子集,为相似度匹配计算添加问题文本比仅使用预测答案更有效。
④对于片段抽取MRC,传统的token相似性方法似乎更有效,因为答案已经是一个段落中的片段。相反,伪数据训练方法在多项选择MRC中更有效,其中选项不是通过片段组成,不能直接映射,并且需要语义上的相似性计算,而不仅仅是token级计算。
⑤答案和推理句预测的提高并不一定会提高整体得分。例如,在C3的开发集中,伪数据训练large级基线在答案和推理句预测方面都比其他方法产生更好的性能。然而,其50.7的总得分低于表现最好的基线50.9。原因是更多的样本对于错误答案预测具有更好的推理句预测或对于正确答案预测具有更差的推理句预测,这会降低总体得分。
⑥尽管伪数据训练基线通常不会产生更好的总体分数,但可以看到答案预测准确性几乎一致的提高,例如在C3中使用大型PLM(例如开发+3.3,测试+2.4)。这表明使用伪证据有助于改进答案预测,当使用更有效的方法提取高质量伪数据时,会有另一个改进。
6.3 答案和证据平衡
为了平衡答案和推理句损失之间的比率,对推理句损失应用了lambda项。为了探究lambda项的影响,选择了不同的λ∈[0,1],并绘制了每个任务的5次运行平均性能。结果如图3所示。
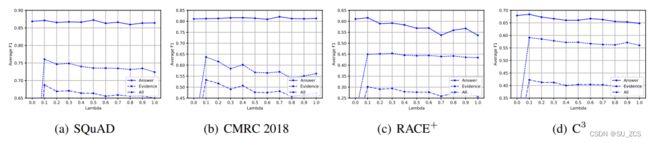
图3:lambda项对不同任务证据损失的影响。
通过增加lambda项,推理句得分和总体得分降低,这表明伪数据训练不能被视为与原始监督任务训练(答案预测)一样重要,因为伪数据不是由真实的推理句构建的。然而,当涉及到答案分数时,与多选择MRC任务相比,片段抽取跨MRC任务对lambda项不太敏感。
6.4 上限测试
除了“带问题的最相似句子”(MSS w/Ques.)和“预测答案句子”(PA Sent.),本文还提供了两个额外的基线。提取包含基本事实答案(GA Sent.)或注释推理句(GE Sent.)的句子,以测量那些仅提取句子级证据的系统的上限。结果如表4所示。
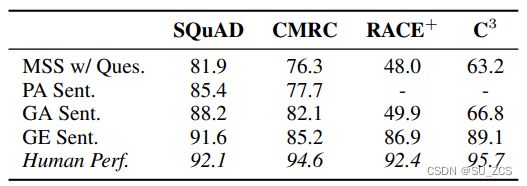
表4:开发集的证据表现。
片段提取MRC中的PA-GA和GA-GE差距非常小(约3%~5%),这表明当前系统在仅使用句子级推理句提取时将达到最高性能。相反,在多选择MRC中,看到了巨大的差距,这表明仅使用答案句子不足以实现强大的证据提取性能。除SQuAD任务外,其他任务产生5.5%~9.4%的差距,这表明在这些任务中找到确切的推理句仍然可以实现可观的改善。
7 结论
本文提出了一个评估机器阅读理解系统可解释性的综合基准。提出的ExpMRC基准包含四个数据集,包括片段抽取MRC和中英文多项选择MRC。ExpMRC旨在评估MRC系统,不仅对最终答案做出正确的预测,而且为答案提取正确的推理句。本文建立了几个基线系统来彻底评估ExpMRC,实验结果表明,传统的和最先进的预训练语言模型仍然在很大程度上低于人类的表现,这表明在解释提取方面应该做更多的工作。希望数据集的发布能够进一步加速MRC系统的可解释性和可解释性研究。
8 复现
| -- 根目录
| -- baseline # Baseline codes
| -- modeling.py
| -- optimization.py
| -- run_mc_mrc.py # 用于训练多项选择阅读理解数据集
| -- run_se_mrc.py # 用于训练片段抽取阅读理解数据集
| -- tokenization.py
| -- README.md # 训练脚本指示
| -- bert #预训练模型(需要自己下载)
| -- bert_config.json #bert的配置
| -- bert_model.ckpt.data-00000-of-00001 #初始模型权重
| -- bert_model.ckpt.index
| -- bert_model.ckpt.meta
| -- vocab.txt #词汇表
| -- data # 开发集,用于评估
| -- c3
| -- expmrc-c3-dev.json #c3的开发集
| -- cmrc2018
| -- expmrc-cmrc2018-dev.json #cmrc2018的开发集
| -- race
| -- expmrc-race-dev.json #race的开发集
| -- squad
| -- expmrc-squad-dev.json #squad的开发集
| -- pseudo_training_data # 伪数据,用于训练
| -- train-pseudo-c3
| -- train-pseudo-c3.json #c3的训练集
| -- train-pseudo-cmrc2018
| -- train-pseudo-cmrc2018.json #cmrc2018的训练集
| -- train-pseudo-race
| -- train-pseudo-race.json #race的训练集
| -- train-pseudo-squad
| -- train-pseudo-squad.json #squad的训练集
| -- sample_submission # ExpMRC的提交文件示例
| -- eval_expmrc.py # 用于评估 其中,PaT:Pseudo-data Training。设置train_batch_size=2 predict_batch_size=2,其余数据正在复现.....
System |
SQuAD(dev) |
CMRC 2018(dev) |
C3(dev) |
race(dev) |
||||||||
Ans |
Evi |
ALL |
Ans |
Evi |
ALL |
Ans |
Evi |
ALL |
Ans |
Evi |
ALL |
|
PaT(原文) |
88.1 |
76.9 |
69.7 |
82.7 |
65.1 |
54.7 |
70.9 |
59.9 |
43.5 |
62.4 |
36.6 |
28.2 |
PaT(P100*4) |
82.7 |
79.2 |
68.5 |
|
|
|
53.5 |
44.7 |
26.3 |
|||
PaT(2080Ti*1) |
82.4 |
79.3 |
68.0 |
53.3 |
44.4 |
26.6 |
||||||
PaT(3090*1) |
80.1 |
77.4 |
65.7 |
|
|
|
|
|
|
|
|
|