最细! 卷积神经网络的历史和 各层的作用
目录
一 历史发展
二 卷积层
2.1 卷积层的作用
2.1.1提取图像的特征
2.1.2 局部感知,参数共享
2.1.3 二维卷积运算
2.1.4 特征图和感受野
2.1.5 卷积中的填充和步幅
2.1.6 卷积层的多输入通道
三 池化层
3.1 池化层的作用
3.1.1最大池化层和平均池化层
四 归一化层
4.1 归一化的作用
4.2 什么是归一化?
五:神经网络的应用
5.1 图像和分类识别
5.2 自然语言处理(NLP)
5.3 图像着色
一 历史发展

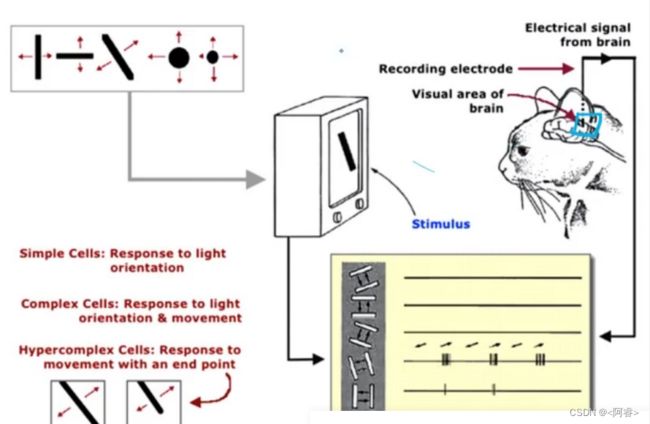
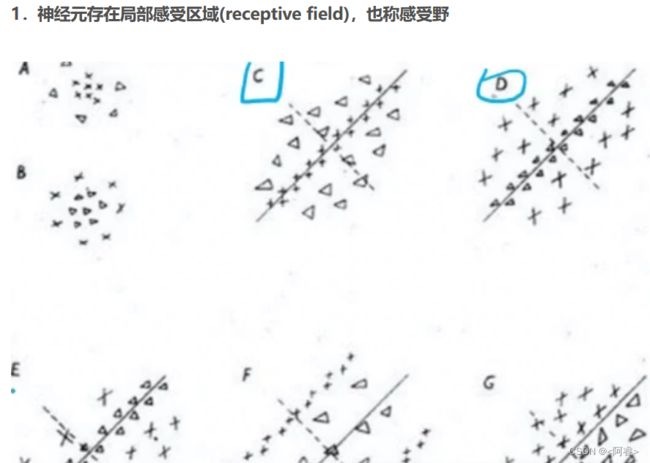
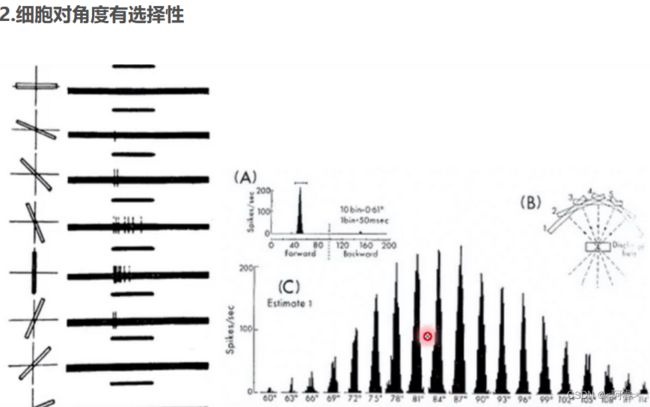

对CNN启发
(1)视觉系统是分层、分级的进行处理,从低级到高级的抽象过程→堆叠使用卷积和池化
(2)神经元实际上是存在局部的感受区域的,具体说来,它们是局部敏感→神经元局部连接
继续在19世纪80年代到2012年发展

第一个卷积神经网络雏形:
1980年,日本学者福岛邦彦(KunihikoFukushima)借鉴猫视觉系统实验结论,提出具有层级结构的神经网络――新认知机,堆叠使用类似于S细胞和C细胞的两个结构。S细胞和C细胞可类比现代CNN的卷积和池化
缺点:没有反向传播算法更新权值,模型性能有限。
论文地址:
Fukushima K. Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position [J]. Biological cybernetics, 1980, 36(4): 193-202. ———————————————— 版权声明:本文为CSDN博主「TechArtisan6」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/zaishuiyifangxym/article/details/99733020 https://www.cs.princeton.edu/courses/archive/spr08/cos598B/Readings/Fukushima1980.pdf
https://www.cs.princeton.edu/courses/archive/spr08/cos598B/Readings/Fukushima1980.pdf


第一个大规模商用卷积神经网络―Lenet- 5
https://www.aminer.cn/pub/53e9a281b7602d9702b88a98/imagenet-classification-with-deep-convolutional-neural-networks
第一个技惊四座的卷积神经网络―—AlexNet
直到2012年,Imagenet图像识别大赛中,Hinton组的论文《ImageNet Classification with Deep Convolutional Neural Networks》中提到的Alexnet引入了全新的深层结构和dropout方法,一下子把error rate从25.8%降低到16.4%,颠覆了图像识别领域。
AlexNet有很多创新点,但现在看来是一项非常简陋的工作。他主要是让人们意识到原来那个福岛邦彦提出,Yann Lecun优化的Lenet结构是有很大改进空间的;只要通过一些方法能够加深这个网络到8层左右,让网络表达能力提升,就能得到出人意料的好结果。
论文地址:
AlexNethttps://www.aminer.cn/pub/53e9a281b7602d9702b88a98/imagenet-classification-with-deep-convolutional-neural-networks
二 卷积层
2.1 卷积层的作用
2.1.1提取图像的特征
并且卷积核的权重是可以学习的,由此可以猜测,在高层神经网络中,卷积操作能突破传统滤波器的限制, 根据目标函数提取出想要的特征 。卷积操作被广泛应用与图像处理领域,不 同卷积核可以提取不同的特征,例如边沿、线性、角等特征。在深层卷积神经网络中,通过卷积操作可 以提取出图像低级到复杂的特征。


2.1.2 局部感知,参数共享
局部感知:
●全连接神经网络的连接大大多于局部连接,这就意味:通过局部连接会大大减少数据量,局部连接的参数会有效的降低 加快训练的速度和效率.
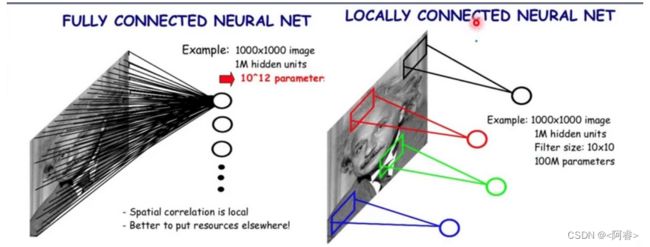

参数共享(权值共享(Convolution:卷积)):
●卷积层的每一个卷积滤波器重复的作用于整个感受野中,每一个卷积滤波器共享相同的参数。
●对图像进行特征提取时不用考虑局部特征的位置。使要学习的卷积神经网络模型参数数量大大降低。
卷积核通过在特征图中进行滑动,卷积核参数重复利用,参数共享

2.1.3 二维卷积运算

如图所示,输入是⼀个高和宽均为3的二维数组,将该数组的形状记为3×3或(3,3)。核数组的高和宽分别为2。该数组在卷积计算中又称卷积核或过滤器(filter)。卷积核窗口(又称卷积窗口)的形状取决于卷积核的高和宽,即2×2。图中的阴影部分为第⼀个输出元素及其计算所使用的输入和核数组元素:0 * 0 + 1 * 1 + 3 * 2 + 4 * 3 = 19。
假设输入形状是 n h × n w , 卷积核窗口的形状是 k h × k w,那么输出形状将会是:
2.1.4 特征图和感受野
二维卷积层输出的二维数组可以看作是输入在空间维度 ( 宽和高 ) 上某一级的表征,也叫 特征图 (feature map) 。影响元素 x 的前向计算的所有可能输入区域 ( 可能大于输入的实际尺寸 ) 叫做 x 的 感受野 (receptive field) 。以上图为例, 输入中阴影部分的四个元素0134是输出中阴影部分19元素的感受野
卷积核:具可学习参数的算子,用于对输入图像进行特征提取,输出通常称为特征图(feature maps) 以下为通过卷积核之后输出的特征图

在卷积神经网络中,感受野(Receptive Field)的定义是卷积神经网络每一层输出的特征图(feature map)上的像素点在输入图片上映射的区域大小。再通俗点的解释是,特征图上的一个点对应输入图上的区域,如图所示。

2.1.5 卷积中的填充和步幅
填充( padding )在进行卷积运算时,输入矩阵的边缘会比矩阵内部的元素计算次数少,且输出矩阵的大小会在卷积运算中 相比较于输入的尺寸变小。因此,可在输入矩阵的四周补零,称为 padding ,其大小为 P 。比如当 P=1 时, 原输入 3*3 的矩阵如下,实线框中为原矩阵,周围使用 0 作为 padding 。
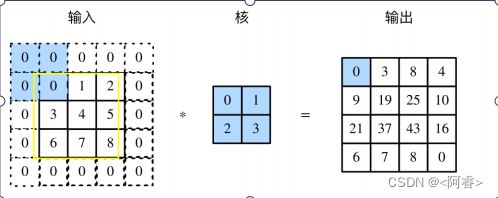
一 般来说,如果在高的两侧一共填充ph行,在宽的两侧一共填充pw列,那么输出形状将会是:

如图:(3-2+2+1)*(3-2+2+1) = 4*4
步幅( stride )在先前的例子里。卷积窗口从输入数组的 最左上方开始,按从左往右、从上往下的顺序 ,依次在输入数组上滑动。每次滑动的行数和列数称为 步幅 (stride) ,先前的例子里,在高和宽两个方向上步幅均为 1 。当然,根据实际 情况也可以使用更大的步幅。如下图所示 ( 实际输入为 3*3 ,高、宽各以 0 值填充 1 行 / 列 ) ,在高上步幅为 3 、在宽上步幅为 2 的卷积运算。可以看 到,输出第一列第二个元素时 , 卷积窗口向下滑动了 3 行 Sh=3,而在输出第一行第二个元素时卷积窗口向右滑动了 2列 Sw=2 。当卷积窗口在输入上再向右滑动 2 列时,由于输入元素无法填满窗口 , 无结果输出。图中的阴影部分为输出元素 及其计算所使用的输入和卷积核数组元素 : 0*0+0*1+1*2+2*3=8 、 0*0+6*1+0*2+0*3=6 。

一般来说,当高上步幅为sh,宽上步幅为sw时,输出形状为:
![]()
如图:(3-2+2+3)/3 *(3-2+2+2)/2 = 2*2
2.1.6 卷积层的多输入通道
多输入通道 (multi-channel)前面例子中用到的输入和输出都是二维数组, 但真实数据的维度经常更高 。例如,彩色图像在高和宽 2 个维度外还有 RGB ( 红、绿、蓝 ) 3 个颜色通道。假设彩色图像的高和宽分别是 h 和 w( 像素 ), 那么它可以表示为一 个 3 * h * w 的多维数组。将大小为 3 的这一维称为通道 (channel) 维。当输入数据含多个通道时,一般需要构造一个 输入通道数与输入数据的通道数相同的卷积核 ,从而能够与含多通道的输入数据做卷积运算。
图示:

计算方式

三 池化层
3.1 池化层的作用
池化层通常会在卷积层之间周期性插入一个池化层,其作用是逐渐 降低数据体的空间尺寸 ,这样就能够 减少网络中参数 的数量,减少计算资源耗费,同时也能够有效地控制过拟合。1. invariance( 不变性 ) ,这种不变性包括 translation( 平移 ) , rotation( 旋转 ) , scale( 尺度 ) 。特征不变性,也就是在图像处理中经常提到的特征的尺度不变性,池化操作就是图像的 resize ,平时一张狗的图像被缩小了一倍还能认出这是一张 狗的照片,这说明这张图像中仍保留着狗最重要的特征,一看就能判断图像中画的是一只狗,图像压缩时去掉的信 息只是一些无关紧要的信息, 而留下的信息则是具有尺度不变性的特征,是最能表达图像的特征。2. 特征降维(下采样): 保留主要的特征同时减少参数( 降维,效果类似 PCA) 和计算量, 防止过拟合,提高模型泛化能力 。 同时减小了下一层的输入大小,进而减少计算量和参数个数。3.在一定程度上防止过拟合,更方便优化。
4.实现非线性(类似relu)。
5.扩大感受野。
在神经网络中:
图示为计算过程:

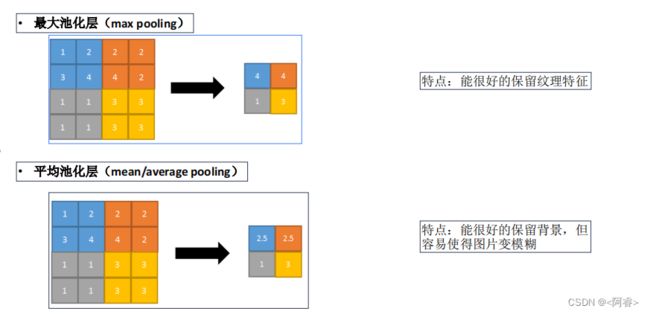
3.1.1最大池化层和平均池化层
四 归一化层
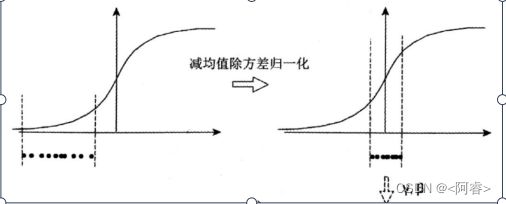
!主要还是为了克服神经网络难以训练的弊端!internal covariate shift:数据尺度/分布异常,导致训练困难!
4.1 归一化的作用
归一化的作用
以前在神经网络训练中,只是对输入层数据进行归一化处理,却没有在中间层进行归一化处理虽然对输入数据进行了归一化处理,但是输入数据经过 f(w*a+b) 这样的线性乘加操作以及非线性处理之后,其数据分布很可能 被改变,而随着深度网络的多层运算之后, 数据分布的变化将越来越大。如上左图是没有经过任何处理的输入数据,曲线是 sigmoid 函数,如果数据在梯度很小的区域,那么 学习率就会很慢甚至陷入长时间的停滞 。 减均值 除方差 后,数据就被移到中心区域如上右图所示,对于大多数激活函数而 言,这个区域的梯度都是最大的或者是有梯度的(比如 ReLU ),这可以看做是一种 对抗梯度消失的有效手段 。对于一层如此,如果对于每一层数据都那么做的话,数据的分布总是在随着变化敏感的区域,相当于不用考虑数据分布变化了,这样训练起来更有效率。
4.2 什么是归一化?
什么是归一化把数据变成 (0,1) 或者 (-1,1) 之间的小数,主要是为了数据处理方便提出来的,把数据映射到 0 ~ 1 范围之内处理,更加便捷快速。• BatchNorm : batch 方向做归一化,算 NHW 的均值,对小 batchsize 效果不好; BatchNorm 主要缺点是对batchsize 的大小比较敏感,由于每次计算均值和方差是在一个 batch 上,所以如果 batchsize 太小,则计算的均值、方差 不足以代表整个数据分布• LayerNorm : channel 方向做归一化,算 CHW 的均值,主要对 RNN 作用明显;• InstanceNorm :一个 channel 内做归一化,算 H*W 的均值,用在风格化迁移;因为在图像风格化中,生成结果主要依赖于某个图像实例,所以对整个 batch 归一化不适合图像风格化中,因而对 HW 做归一化。可以加速模型收敛,并且保持每个图像实例之间的独立。• GroupNorm :将 channel 方向分 group ,然后每个 group 内做归一化,算 (C//G)HW 的均值;这样与 batchsize 无关,不受其约束。

五:神经网络的应用
5.1 图像和分类识别
卷积神经网络为图像而生,但应用不限于图像。
在卷积神经网络还没有普及之前,通常由人工抽取图像中的特定信息(如轮廓检测,边缘检测, LBP, HOG 、 HAAR 等特征检测方法〉来实现图像分类任务,然后对这些特征编写特定的算法来对分类模式进行匹配 。 如此显式地抽取图像特征的方法,不仅在特征工程问题上耗费了工程师们大量的时间,而且仍然会存在着许多严峻的问题等待工程师们去解决。如图像受光照影响、物体旋转影响、物体平移等空间信息的改变,其图像中物体的特征也会随之改变等,从而导致之前的模式识别方法失效。
在 2012 年的 ImageNet 图像分类比赛上, AlexNet 网络模型大幅度地超越了其他选手,夺得了当年图像分类大赛的冠军 ,因为 Alex 使用并改进了卷积神经网络模型 。 从那以后,卷积神经网络在图像分类上一枝独秀,其中手写字体( Hand Written)的识别率己经超越人类的识别率,达到了 99.9%。国外众多快递公司已经开始应用卷积神经网络模型识别快递单上的手写字体,尽最大可能地节约企业成本、提高自身的系统运作效率 。

实例1: 目标检测 Object Detection


目标检测的 应用
人脸检测
●智能门控
●员工考勤签到
●智慧超市行人检测
●智能监控
●智能辅助驾驶
●暴恐检测(根据面相识别暴恐倾向)车辆检测
●自动驾驶
●违章查询、关键通道检测
●广告检测(检测广告中的车辆类型,弹出链接)
5.2 自然语言处理(NLP)
卷积神经网络不再是图像处理任务专用的神经网络模型。近两年来,学者们将卷积神经网络应用于自然语言处理( Natural Language Processing, NLP)领域的研究,己经有了十分出色的表现,新成果和顶级论文层出不穷 。自然语言处理任务在卷积神经网络模型中的输入不再是像素点,大多数情况下是以矩阵表示的句子。矩阵的每一行对应一个元素,如果一个元素代表一个单词,那么每一行代表一个单词的向量。卷积神经网络模型应用在计算机视觉中,卷积核每次只对图像中的一小块区域进行卷积操作,但在处理自然语言时,卷积核通常覆盖上下几行(几个单词)。因此,卷积核的宽度和输入矩阵的宽度需要相同。
深度学习在自然语言处理领域的应用

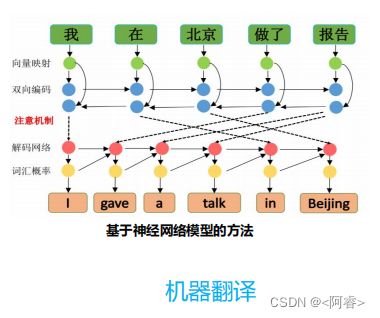


自然语言处理研究实现人与计算机之间用自然语言进行有效通信的各种理论和方法。自然语言处理技
术发展经历了 基于规则的方法 、 基于统计学习的方法 和 基于深度学习的方法 三个阶段。自然语言处理由浅入深的四个层面分别是 形式 、 语义 、 推理 和 语用 ,当前正处于由语义向推理的发展阶段。

5.3 图像着色
图像着色问题是指将颜色添加到灰度图像中,即灰度图像恢复色彩的过程。传统的做法是人工去对每一帧图像中的每一个像素和每一个物体进行着色,这是一项艰巨的任务。使用人力手工完成该任务会带来两个大问题:
- 耗费大量的人力资源和宝贵的时间;
- 对于同 一个事物,不同人的着色标准是有差异的。
