论文解读: PP-YOLOE: An evolved version of YOLO

论文地址:https://arxiv.org/pdf/2203.16250.pdf
发表时间:2022
PP-YOLOE基于PP-YOLOv2改进实现,其中PP-YOLOv2的整体架构包含了具有可变形卷积的ResNet50-vd的主干,使用带有SPP层和DropBlock的PAN做neck,以及轻量级的IoU感知头。在PPYOLOv2中,ReLU激活功能用于主干,而mish激活功能用于颈部。PP-YOLOv2只为每个GT对象分配一个锚定框。除了分类损失、回归损失和目标损失外,PP-YOLOv2还使用IoU损失和IoU感知损失来提高性能。PP-YOLOE的网络结构如下所示

1、模型基本结构
1.1 结构说明
PP-YOLOE使用宽度系数α和深度系数β控制网络中backbone和neck的结构。backbone的默认宽度设置为[64、128、256、512、1024],深度设置为[3,6,6,3]。neck的默认宽度设置和深度设置分别为[192,384,768]和3。针对s、m、l和x模型的结构缩放系数如下所示
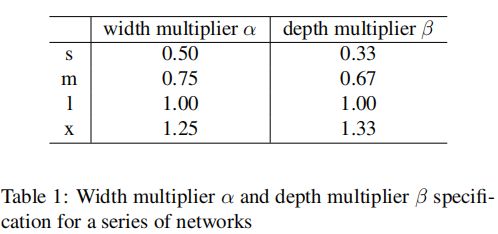
1.2 Backbone
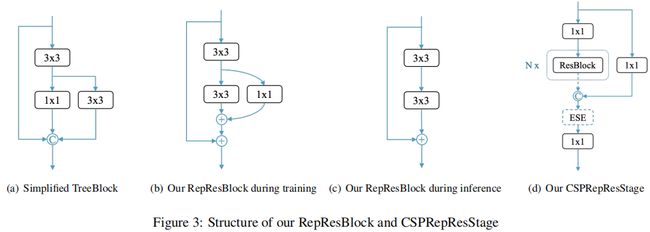
CSPNet是YOLOv5和YOLOX中流行的backbone,基于该启发设计了RepResBlock集成了residual连接和dense连接的特点。Block的设计如下所示,先简化concat操作为add操作(a
图->b图),然后在推理阶段将b图结构转化为c图(RepResBlock的结构)。所设计的CSPRepResStage结构如图d所示,使用了ESE(Effective Squeeze and Extraction)进行通道上的attention。其实现代码可参考3.2,其中的激活函数为swish。
1.3 Neck
使用CSPPAN做Neck,其中的block也是CSPRepResStage,但是删除了shortcut和和ESE层(因为在Neck中特征已经提取的很极值了,不需要再度attention)。其中的激活函数为SiLU(Swish)=f (x) = x · sigmoid (x)
1.4 Head
为提升速度与性能,基于TOOD中的T-head进行改进,提出了ET-head。使用ESE层替换了T-head中的layer attention(?存疑,T-head也是SE层),并将回归分支的对齐简化为Distribution Focal Loss(DFL)层,其使用的的激活函数为SiLU(Swish)。通过这些改变,ET-Head在V100上提升了0.9ms。
1.5 PPYOLOE+
PPYOLOE+表示在object365中进行了预训练(其模型结构配置文件与PPYOLOE一模一样,只是在backbone中block分支中增加alpha参数)的PPYOLOE模型。两个模型在ATSSAssigner与TaskAlignedAssigner的epoch数上存在不同,ppyoloe的static_assigner_epoch为100,ppyoloe+的为30【经过预训练后ppyoloe+对ATSSAssigner的依赖降低】.
2、模型特点
2.1 锚框机制
Anchor-free(Anchor-base模型引入超参数,依赖手工设计,对不同的数据集需要单独聚类),在每个像素上放置一个锚点,为三个检测头设置GT尺寸的上届和下界。计算GT的中心,选择最近的锚点做正样本。Anchor-free方式使mAP比Anchor-base下降0.3,但是速度有所提升,具体如下表所示。

2.2 标签分配
使用TOOD中的TAL(Task Aligned Learing),显性的对齐分类最优点和位置回归最优点。注TOOD论文中,提出任务对齐头部(T-Head)和任务对齐学习(TAL)。T-head在学习任务交互特征和任务特定特征之间提供了更好的平衡,并通过任务对齐预测器学习对齐的灵活性提高,TAL通过设计的样本分配方案和任务对齐损失,明确地拉近(甚至统一)两个任务的最优锚点 TAL包含任务对齐指标、正样本选择标准,并将任务对齐指标与原先的的分类损失、回归损失进行联立[其本质就是根据任务对齐指标调节不同样本在反向传播时loss的权重,具体可以参考https://hpg123.blog.csdn.net/article/details/128725465]。PP-YOLOE其实也尝试过多种标签对齐方式,具体如下所示,可见TAL效果是最佳的。

2.3 loss设计
对于分类和定位任务,分别选择了varifocal loss(VFL)和distribution focal loss(DFL)。PP-Picodet成功将VFL和DFL语义到目标检测中。VFL与quality focal(QFL)不同,VFL使用目标评分来衡量正样本loss的权重(可提升正样本loss的贡献,使模型更多关注高质量正样本,解决了NMS过程中classification score 和 IoU/centerness score 训练测试不一致【训练时两个孤立,nms时两个联立】),两者都使用带有IOU感知的分类评分作为预测目标。整体loss设计如下所示,其中 t ^ \hat{t} t^表示标准化的目标分数,使用ET-head提升了0.5的map
L o s s = α ⋅ loss V F L + β ⋅ loss G I o U + γ ⋅ loss D F L ∑ i N p o s t ^ L o s s=\frac{\alpha \cdot \operatorname{loss}_{V F L}+\beta \cdot \operatorname{loss}_{G I o U}+\gamma \cdot \operatorname{loss}_{D F L}}{\sum_{i}^{N_{p o s}} \hat{t}} Loss=∑iNpost^α⋅lossVFL+β⋅lossGIoU+γ⋅lossDFL
DFL(distribution focal loss):为了解决bbox不灵活的问题,提出使用distribution[将迪克拉分布转化为一般分布]预测bbox[预测top、left、right、bottom]。

2.4 训练细节
使用带动量的SGD,其中momentum为0.9,权重衰减为5e-4,使用余弦学习率调度器,总共epoch为300,预热epoch为5。学习率为0.01,batchsize为64,8个32G的V100多卡训练。训练过程中使用decay=0.9998的EMA策略(可以参考)。只使用了基本的数据增强,包括随机裁剪、随机水平翻转、颜色失真和多尺度(尺度范围为320到768,步长为32),测试尺度为640。具体性能对比如下标所示。

3、关键步骤实现
3.1 网络细节与TODO的差异
ppyoloe的下采样倍数为32, 16, 8,可以修改backbone、neck、head的输出chanel,增加输出级别以适应不同尺度的目标检测。其所设计的backbone、neck、head本质上是可以替换的,只是区别于TODO(其在resnetXt101上最佳map为48.3,在resnetXt101-dcn上最佳map为51.1,预计是没有使用PAN[PAN论文中可以将MAsk R-CNN提升3-5个点],且resnetXt101与CSPReResnet存在差异[CSPReResNet在参数量上分别有CSP和REP上的优势],然后再bbox回归中ppyoloe使用的dfl和GIOU),在backbone上做了修改,在T-head上做了轻量化。
architecture: YOLOv3
norm_type: sync_bn
use_ema: true
ema_decay: 0.9998
ema_black_list: ['proj_conv.weight']
custom_black_list: ['reduce_mean']
YOLOv3:
backbone: CSPResNet
neck: CustomCSPPAN
yolo_head: PPYOLOEHead
post_process: ~
CSPResNet:
layers: [3, 6, 6, 3]
channels: [64, 128, 256, 512, 1024]
return_idx: [1, 2, 3]
use_large_stem: True
CustomCSPPAN:
out_channels: [768, 384, 192]
stage_num: 1
block_num: 3
act: 'swish'
spp: true
PPYOLOEHead:
fpn_strides: [32, 16, 8]
grid_cell_scale: 5.0
grid_cell_offset: 0.5
static_assigner_epoch: 100
use_varifocal_loss: True
loss_weight: {class: 1.0, iou: 2.5, dfl: 0.5}
static_assigner:
name: ATSSAssigner
topk: 9
assigner:
name: TaskAlignedAssigner
topk: 13
alpha: 1.0
beta: 6.0
nms:
name: MultiClassNMS
nms_top_k: 1000
keep_top_k: 300
score_threshold: 0.01
nms_threshold: 0.7
3.2 SMLX版本
PPYOLOE存在S、M、L、X等版本,是由depth_mult和width_mult两个参数控制模型的深度,故此可以通过修改depth_mult和width_mult得到其他版本的PPYOLOE模型。
在以下配置文件中,depth_mult用于控制layers内(backbone中stage的深度,默认为[3,6,6,3])的参数(故其最小值为1/3),width_mult用于控制channels内(stem和backbone中stages的宽度)的参数。
CSPResNet:
layers: [3, 6, 6, 3]
channels: [64, 128, 256, 512, 1024]
return_idx: [1, 2, 3]
use_large_stem: True
use_alpha: True
CustomCSPPAN:
out_channels: [768, 384, 192]
stage_num: 1
block_num: 3
act: 'swish'
spp: true
use_alpha: True
depth_mult: 0.33
width_mult: 0.50
其版backbone的实现代码为:
@register
@serializable
class CSPResNet(nn.Layer):
__shared__ = ['width_mult', 'depth_mult', 'trt']
def __init__(self,
layers=[3, 6, 6, 3],
channels=[64, 128, 256, 512, 1024],
act='swish',
return_idx=[1, 2, 3],
depth_wise=False,
use_large_stem=False,
width_mult=1.0,
depth_mult=1.0,
trt=False,
use_checkpoint=False,
use_alpha=False,
**args):
super(CSPResNet, self).__init__()
self.use_checkpoint = use_checkpoint
channels = [max(round(c * width_mult), 1) for c in channels]
layers = [max(round(l * depth_mult), 1) for l in layers]
act = get_act_fn(
act, trt=trt) if act is None or isinstance(act,
(str, dict)) else act
if use_large_stem:
self.stem = nn.Sequential(
('conv1', ConvBNLayer(
3, channels[0] // 2, 3, stride=2, padding=1, act=act)),
('conv2', ConvBNLayer(
channels[0] // 2,
channels[0] // 2,
3,
stride=1,
padding=1,
act=act)), ('conv3', ConvBNLayer(
channels[0] // 2,
channels[0],
3,
stride=1,
padding=1,
act=act)))
else:
self.stem = nn.Sequential(
('conv1', ConvBNLayer(
3, channels[0] // 2, 3, stride=2, padding=1, act=act)),
('conv2', ConvBNLayer(
channels[0] // 2,
channels[0],
3,
stride=1,
padding=1,
act=act)))
n = len(channels) - 1
self.stages = nn.Sequential(*[(str(i), CSPResStage(
BasicBlock,
channels[i],
channels[i + 1],
layers[i],
2,
act=act,
use_alpha=use_alpha)) for i in range(n)])
self._out_channels = channels[1:]
self._out_strides = [4 * 2**i for i in range(n)]
self.return_idx = return_idx
if use_checkpoint:
paddle.seed(0)
def forward(self, inputs):
x = inputs['image']
x = self.stem(x)
outs = []
for idx, stage in enumerate(self.stages):
if self.use_checkpoint and self.training:
x = paddle.distributed.fleet.utils.recompute(
stage, x, **{"preserve_rng_state": True})
else:
x = stage(x)
if idx in self.return_idx:
outs.append(x)
return outs
@property
def out_shape(self):
return [
ShapeSpec(
channels=self._out_channels[i], stride=self._out_strides[i])
for i in self.return_idx
]
3.3 cls loss实现
ppdet/modeling/heads/ppyoloe_head.py#L337,默认使用varifocal_loss,
if self.use_varifocal_loss:
one_hot_label = F.one_hot(assigned_labels,
self.num_classes + 1)[..., :-1]
loss_cls = self._varifocal_loss(pred_scores, assigned_scores,
one_hot_label)
else:
loss_cls = self._focal_loss(pred_scores, assigned_scores, alpha_l)
assigned_scores_sum = assigned_scores.sum()
if paddle.distributed.get_world_size() > 1:
paddle.distributed.all_reduce(assigned_scores_sum)
assigned_scores_sum /= paddle.distributed.get_world_size()
assigned_scores_sum = paddle.clip(assigned_scores_sum, min=1.)
loss_cls /= assigned_scores_sum
_varifocal_loss的具体实现如下,为正样本设置的权重为assigned_scores【同时训练目标也为assigned_scores】,为负样本设置的权重为alpha * pred_score.pow(gamma)。与focal loss相比【正负样本中难易样本都是对等的】,VFL中正负样本中的难易样本是不对等的。
def _varifocal_loss(pred_score, gt_score, label, alpha=0.75, gamma=2.0):
weight = alpha * pred_score.pow(gamma) * (1 - label) + gt_score * label
loss = F.binary_cross_entropy(
pred_score, gt_score, weight=weight, reduction='sum')
return loss
3.4 bbox loss实现
bbox loss包含边框的l1 loss、iou loss和新增的dfl loss,其使用的iou_loss 为GIoULoss()
loss_l1, loss_iou, loss_dfl = \
self._bbox_loss(pred_distri, pred_bboxes, anchor_points_s,
assigned_labels, assigned_bboxes, assigned_scores,
assigned_scores_sum)
loss = self.loss_weight['class'] * loss_cls + \
self.loss_weight['iou'] * loss_iou + \
self.loss_weight['dfl'] * loss_dfl
out_dict = {
'loss': loss,
'loss_cls': loss_cls,
'loss_iou': loss_iou,
'loss_dfl': loss_dfl,
'loss_l1': loss_l1,
}
bbox loss中各类loss的关键计算代码如下,其中loss_dfl设计较为复杂,或可将bbox loss替换为SIOU、EIOU等。
bbox_mask = mask_positive.unsqueeze(-1).tile([1, 1, 4])
pred_bboxes_pos = paddle.masked_select(pred_bboxes,
bbox_mask).reshape([-1, 4])
assigned_bboxes_pos = paddle.masked_select(
assigned_bboxes, bbox_mask).reshape([-1, 4])
bbox_weight = paddle.masked_select(
assigned_scores.sum(-1), mask_positive).unsqueeze(-1)
loss_l1 = F.l1_loss(pred_bboxes_pos, assigned_bboxes_pos)
loss_iou = self.iou_loss(pred_bboxes_pos,
assigned_bboxes_pos) * bbox_weight
loss_iou = loss_iou.sum() / assigned_scores_sum
dist_mask = mask_positive.unsqueeze(-1).tile(
[1, 1, (self.reg_max + 1) * 4])
pred_dist_pos = paddle.masked_select(
pred_dist, dist_mask).reshape([-1, 4, self.reg_max + 1])
assigned_ltrb = self._bbox2distance(anchor_points, assigned_bboxes)
assigned_ltrb_pos = paddle.masked_select(
assigned_ltrb, bbox_mask).reshape([-1, 4])
loss_dfl = self._df_loss(pred_dist_pos,
assigned_ltrb_pos) * bbox_weight
loss_dfl = loss_dfl.sum() / assigned_scores_sum
其中_df_loss考虑到真实的分布通常不会距离标注的位置太远,希望网络能够快速地聚焦到标注位置附近的数值,使得他们概率尽可能大。
DFL ( S i , S i + 1 ) = − ( ( y i + 1 − y ) log ( S i ) + ( y − y i ) log ( S i + 1 ) ) \operatorname{DFL}\left(\mathcal{S}_{i}, \mathcal{S}_{i+1}\right)=-\left(\left(y_{i+1}-y\right) \log \left(\mathcal{S}_{i}\right)+\left(y-y_{i}\right) \log \left(\mathcal{S}_{i+1}\right)\right) DFL(Si,Si+1)=−((yi+1−y)log(Si)+(y−yi)log(Si+1))
def _df_loss(self, pred_dist, target):
target_left = paddle.cast(target, 'int64')
target_right = target_left + 1
weight_left = target_right.astype('float32') - target
weight_right = 1 - weight_left
loss_left = F.cross_entropy(
pred_dist, target_left, reduction='none') * weight_left
loss_right = F.cross_entropy(
pred_dist, target_right, reduction='none') * weight_right
return (loss_left + loss_right).mean(-1, keepdim=True)
其详细理论介绍可以参考https://zhuanlan.zhihu.com/p/147691786,有益效果为:QFL和DFL的作用是正交的,他们的增益互不影响,所以结合使用更香(我们统一称之为GFL)。在基于Resnet50的backbone的ATSS(CVPR20)的baseline上1x训练无multi-scale直接基本无cost地提升了一个点,在COCO validation上从39.2 提到了40.2 AP。实际上QFL还省掉了原来ATSS的centerness那个分支,不过DFL因为引入分布表示需要多回归一些变量,所以一来一去inference的时间基本上也没什么变化。