Coursera-吴恩达-深度学习-改善深层神经网络:超参数调试、正则化以及优化-week2-编程作业
本文章内容:
Coursera吴恩达深度学习课程,
第二课,改善深层神经网络:超参数调试、正则化以及优化(Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization)
第二周:优化算法 (Optimization algorithms)
编程作业,记错本。
包含ji个部分,
1 - Gradient Descent
- (Batch) Gradient Descent:
- Stochastic Gradient Descent:
2 - Mini-Batch Gradient descent
1.Shuffle:Create a shuffled version of the training set (X, Y) as shown below. Each column of X and Y represents a training example.
2.Partition:Partition the shuffled (X, Y) into mini-batches of size mini_batch_size (here 64).
Python floor() 函数: floor() 返回数字的下舍整数。
| 我的:mini_batch_X = shuffled_X[:, 0:k] mini_batch_Y = shuffled_Y[:, k].reshape((1,m)) |
正确:
mini_batch_X = shuffled_X[:, num_complete_minibatches * mini_batch_size: ] |
| 反思:循环 |
3 - Momentum
Because mini-batch gradient descent makes a parameter update after seeing just a subset of examples, the direction of the update has some variance, and so the path taken by mini-batch gradient descent will "oscillate" toward convergence. Using momentum can reduce these oscillations.
1. Initialize the velocity.
2.implement momentum

| 我的: v["dW" + str(l+1)] += v["dW" + str(l)] |
| 正确: |
| 反思:
|
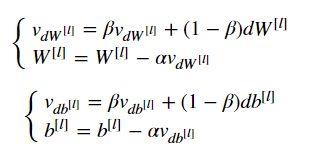
How do you choose ββ?
- The larger the momentum β is, the smoother the update because the more we take the past gradients into account. But if β is too big, it could also smooth out the updates too much.
- Common values for β range from 0.8 to 0.999. If you don't feel inclined to tune this, β=0.9 is often a reasonable default.
- Tuning the optimal β for your model might need trying several values to see what works best in term of reducing the value of the cost function J.
4 - Adam
| 我的: v_corrected["dW" + str(l+1)] = v["dW" + str(l+1)] /(1 - np.exp(t)) |
| 正确: |
反思: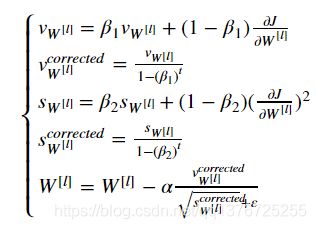 |
几点总结:
神经网络训练中,傻傻分不清Epoch、Batch Size和迭代
原文:https://www.jiqizhixin.com/articles/2017-09-25-3
梯度的含义是斜率。
下降的含义是代价函数的下降。
算法是迭代的,意思是需要多次使用算法获取结果,以得到最优化结果。
只有在数据很庞大的时候(在机器学习中,几乎任何时候都是),我们才需要使用 epochs,batch size,迭代这些术语
一次性将数据输入计算机是不可能的。因此,需要把数据分成小块传递给计算机,在每一步的末端更新神经网络的权重,拟合给定的数据。
完整的数据集通过神经网络一次并且返回一次,这个过程称为一个 epoch。
为什么要使用多于一个 epoch?
在神经网络中传递完整的数据集一次是不够的,而且我们需要将完整的数据集在同样的神经网络中传递多次。但是,我们使用的是有限的数据集,并且我们使用一个迭代过程即梯度下降,优化学习过程和图示。因此仅仅更新权重一次或者说使用一个 epoch 是不够的。
随着 epoch 数量增加,神经网络中的权重的更新次数也增加,曲线从欠拟合变得过拟合。
BATCH SIZE
是一个batch的大小,一个 batch 中的样本总数。记住:batch size 和 number of batches 是不同的。
BATCH 是什么?
在不能将数据一次性通过神经网络的时候,就需要将数据集分成几个 batch。
- Shuffling and Partitioning are the two steps required to build mini-batches
- Powers of two are often chosen to be the mini-batch size, e.g., 16, 32, 64, 128.
迭代
理解迭代,只需要知道乘法表或者一个计算器就可以了。迭代是 batch 需要完成一个 epoch 的次数。记住:在一个 epoch 中,batch 数和迭代数是相等的。
比如对于一个有 2000 个训练样本的数据集。将 2000 个样本分成大小为 500 的 batch,那么完成一个 epoch 需要 4 个 iteration。
理解总结:
(1)batchsize:每批的大小。
(2)iteration:1个iteration = 使用batchsize个样本训练一次;
(3)epoch:1个epoch = 使用训练集中的全部样本训练一次;