ChatGPT低成本复现流程开源!任意单张消费级显卡可体验,显存需求低至1.62GB
明敏 发自 凹非寺
量子位 | 公众号 QbitAI
首个开源的ChatGPT低成本复现流程来了!
预训练、奖励模型训练、强化学习训练,一次性打通。
最小demo训练流程仅需1.62GB显存,随便一张消费级显卡都能满足了。单卡模型容量最多提升10.3倍。
相比原生PyTorch,单机训练速度最高可提升7.73倍,单卡推理速度提升1.42倍,仅需一行代码即可调用。
对于微调任务,可最多提升单卡的微调模型容量3.7倍,同时保持高速运行,同样仅需一行代码。
要知道,ChatGPT火是真的火,复现也是真的难。
毕竟ChatGPT是不开源的,市面上至今没有开源预训练权重、完全开源的低成本训练流程,而且千亿级别大模型的训练本身就是个难题。
但ChatGPT军备赛已经愈演愈烈,为了抓住趋势,如谷歌等都在打造对标竞品。快速复现ChatGPT是应趋势所需。
开源加速方案Colossal-AI正是为此而来。
并且在提供开源完整复现流程的同时,把成本降了下来!
开源地址:https://github.com/hpcaitech/ColossalAI
降显存开销是关键
ChatGPT的效果好,主要是由于在训练过程中引入了人类反馈强化学习(RLHF),但这也直接导致ChatGPT的复现训练难度飙升。
其训练流程主要分为三个阶段:
1、监督微调:从Prompt库中采样,收集其人工回答,利用这些数据来微调预训练大语言模型;
2、奖励模型:从Prompt库中采样,使用大语言模型生成多个回答,人工对这些回答进行排序后,训练奖励模型(RM),来拟合人类的价值判断。
3、基于第一阶段的监督微调模型和第二阶段的奖励模型,利用强化学习算法对大语言模型进一步训练。
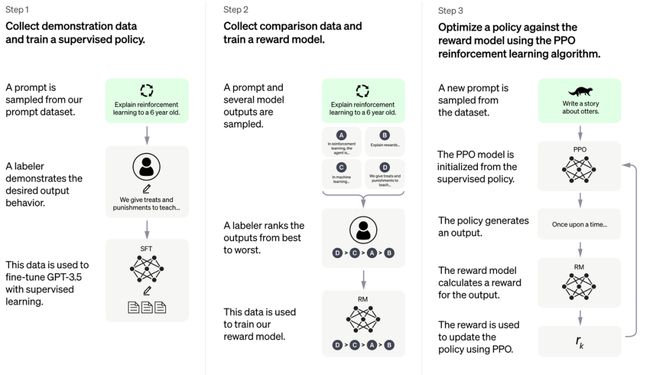
△RLHF的三个阶段
对于ChatGPT训练而言,第三阶段是核心部分。
OpenAI采用了强化学习中近端策略优化算法(PPO),借此引入奖励信号,使得语言模型生成内容更加符合人类评判标准。
但强化学习的引入,也意味着更多模型调用。
例如,使用基于Actor-Critic(AC)结构的PPO算法,需要在训练时进行Actor、Critic两个模型的前向推理和反向传播,以及监督微调模型、奖励模型的多次前向推理。
在ChatGPT基础的InstructGPT论文中,Actor和监督微调模型都使用了1750亿参数的GPT-3系列模型,Critic和奖励模型则使用了60亿参数的GPT-3系列模型。
如此大规模的模型参数,意味着想要启动原始ChatGPT训练流程,需要数千GB的显存开销,单张GPU显然无法容纳,常见的数据并行技术也不能搞定。
即便引入张量并行、流水并行对参数进行划分,也需要至少64张80GB的A100作为硬件基础。而且流水并行本身并不适合AIGC的生成式任务,bubble和调度复杂会导致效率受限。
单张消费级显卡都能体验
Colossal-AI基于ZeRO,Gemini, LoRA, Chunk-based内存管理等方法,提出了一系列单卡、单机多卡、大规模并行解决方案。
对于基于GPT-3系列模型的ChatGPT,Colossal-AI能用原本一半的硬件资源启动1750亿参数模型训练,从64卡降低到32卡。
如果继续用64卡,则将训练时间压缩到更短,节省训练成本、加速产品迭代。
而为了能让更大范围的开发者体验复现ChatGPT,除了1750亿参数版本外,Colossal-AI还提供单卡、单机4/8卡的类ChatGPT版本,以降低硬件限制。
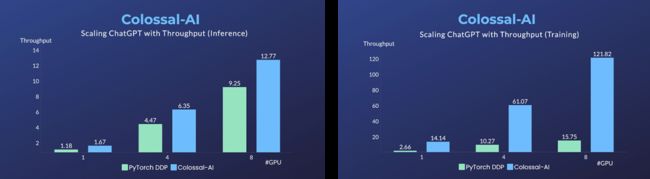
要知道,在单机多卡服务器上,即便把显卡规格提升为A100 80GB,由于ChatGPT的复杂性和内存碎片,PyTorch最大也只能启动基于GPT-L(774M)这样的小模型ChatGPT。
用PyTorch原生的DistributedDataParallel (DDP) 进行多卡并行扩展至4卡或8卡,性能提升有限。
Colossal-AI最高可提升单机训练速度7.73倍,单卡推理速度1.42倍,还可继续扩大规模并行。

为了尽可能降低训练成本和上手门槛,Colossal-AI还提供了在单张GPU上即可尝试的ChatGPT训练流程。
相比于PyTorch在约10万元的A100 80GB上,最大仅能启动7.8亿参数模型,Colossal-AI将单卡容量提升10.3倍至80亿参数。
对于基于1.2亿参数小模型的ChatGPT训练,最低仅需1.62GB显存,任意单张消费级GPU即可满足。
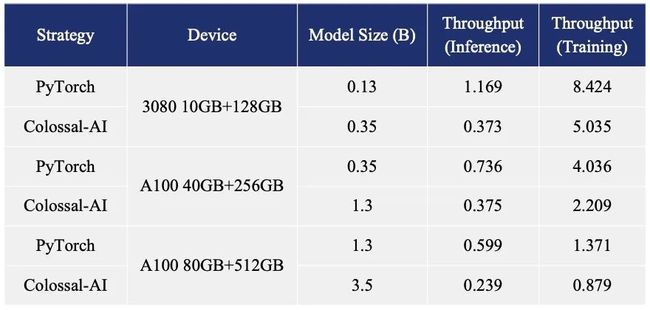
此外,Colossal-AI也致力于降低基于预训练大模型的微调任务成本。以ChatGPT可选的开源基础模型OPT为例,相比PyTorch,Colossal-AI可将提升单卡微调模型容量3.7倍(原始计算量显著增大),同时保持高速运行。
一行代码快速上手
到了具体操作部分,如上复现流程中的多个步骤,基于Colossal-AI开源方案,都能实现一行代码快速上手。
先看模型使用方面。
尽管ChatGPT背后的大语言模型GPT-3.5不开源,但如GPT、OPT、BLOOM等主流开源模型可作为替代。
Colossal-AI为Hugging Face社区的这些模型,提供了开箱即用的ChatGPT复现代码,可覆盖三个阶段的训练。
以GPT为例,添加一行代码指定使用Colossal-AI作为系统策略即可快速使用。
from chatgpt.nn import GPTActor, GPTCritic, RewardModel
from chatgpt.trainer import PPOTrainer
from chatgpt.trainer.strategies import ColossalAIStrategy
strategy = ColossalAIStrategy(stage=3, placement_policy='cuda')
with strategy.model_init_context():
actor = GPTActor().cuda()
critic = GPTCritic().cuda()
initial_model = deepcopy(actor).cuda()
reward_model = RewardModel(deepcopy(critic.model)).cuda()
trainer = PPOTrainer(strategy, actor, critic, reward_model, initial_model, ...)
trainer.fit(prompts)使用下列命令,即可快速启动单卡、单机多卡、1750亿版本训练,并测试各种性能指标(包括最大显存占用、吞吐率和TFLOPS等):
# 使用单机单卡训练GPT2-S,使用最小的batch size,Colossal-AI Gemini CPU策略
torchrun --standalone --nproc_pero_node 1 benchmark_gpt_dummy.py --model s --strategy colossalai_gemini_cpu --experience_batch_size 1 --train_batch_size 1
# 使用单机4卡训练GPT2-XL,使用Colossal-AI Zero2策略
torchrun --standalone --nproc_per_node 4 benchmark_gpt_dummy.py --model xl --strategy colossalai_zero2
# 使用4机32卡训练GPT-3,使用Colossal-AI Gemini CPU策略
torchrun --nnodes 4 --nproc_per_node 8 \
--rdzv_id=$JOB_ID --rdzv_backend=c10d --rdzv_endpoint=$HOST_NODE_ADDR \
benchmark_gpt_dummy.py --model 175b --strategy colossalai_gemini_cpu --experience_batch_背后原理如何?
核心方案还是Colossal-AI。
它从诞生起就面向大模型应用,可基于PyTorch高效快速部署AI大模型训练和推理,是这一领域的明星项目了,GitHub Star超八千颗,并成功入选SC、AAAI、PPoPP、CVPR等国际AI与HPC顶级会议的官方教程。
目前,Colossal-AI已成功帮助一家世界五百强企业,开发具备在线搜索引擎能力增强的类ChatGPT聊天机器人模型。
此前,它们还为Stable Diffusion、OPT、AlphaFold等前沿模型,提供了多样高效的大规模多维并行分布式解决方案。
主创人员为加州伯克利大学杰出教授James Demmel和新加坡国立大学校长青年教授尤洋。
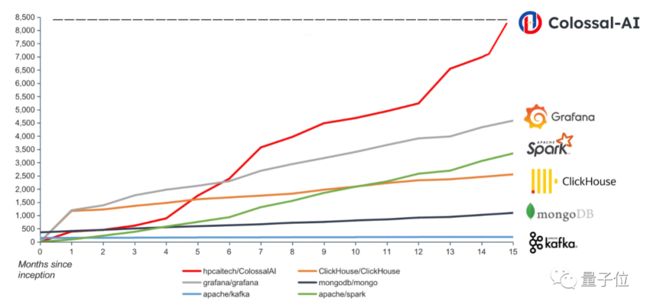
△Colossal-AI与当今主要开源项目同期开源数据对比
具体到细节原理上,LoRA、ZeRO+Gemini是关键。
低成本微调的LoRA
在微调部分,Colossal-AI支持使用低秩矩阵微调(LoRA)方法。
LoRA方法认为大语言模型是过参数化的,其在微调中的参数改变量是一个低秩的矩阵,可以将其分解为两个更小的的矩阵的乘积,即
![]()
在微调时,固定大模型参数,只调整低秩矩阵参数,从而显著减小训练参数量。在微调之后,进行推理部署之前,只需要将参数加回原有矩阵即可,即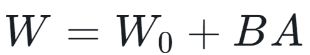 ,不增加模型的推理延迟。
,不增加模型的推理延迟。

△LoRA示意图,仅需训练A、B
减少内存冗余的ZeRO+Gemini
Colossal-AI 支持使用无冗余优化器 (ZeRO) 来优化内存使用,这种方法可以有效减少内存冗余,并且相比传统的数据并行策略,不会牺牲计算粒度和通信效率,同时可以大幅提高内存使用效率。
为了进一步提升 ZeRO 的性能,Colossal-AI 引入了自动Chunk机制。
通过将运算顺序上连续的一组参数存入同一个 Chunk中(Chunk 是一段连续的内存空间),可以确保每个 Chunk 的大小相同,从而提高内存使用效率。
使用Chunk 方式组织内存可以保证 PCI-e 和 GPU-GPU之间的网络带宽得到有效利用,减小通信次数,同时避免潜在的内存碎片。
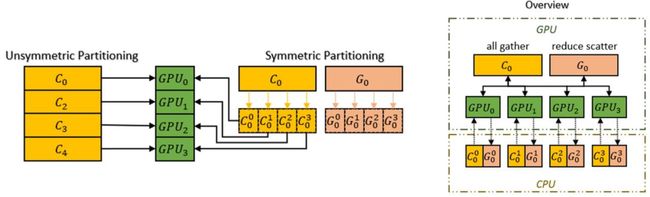
△Chunk机制
此外,Colossal-AI的异构内存空间管理器Gemini支持将优化器状态从 GPU 卸载到 CPU ,以节省 GPU 内存占用。
可以同时利用 GPU 内存、CPU 内存(由 CPU DRAM 或 NVMe SSD内存组成)来突破单GPU内存墙的限制,进一步扩展了可训练模型规模。
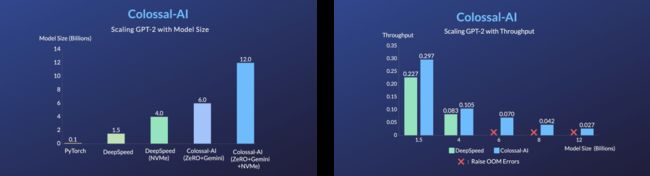
△通过ZeRO+Gemini提升硬件的模型容量
One More Thing
尽管此次开源包含了复现ChatGPT的完整算法流程和必要软件系统,但想要走到实际应用落地,还至少需要数据、算力等方面的支持。
参考开源大模型BLOOM、开源AI画画工具Stable Diffusion的经验,这背后都需要包括个人开发者、算力、数据模型等可能合作方的支持共建——
此前,超过1000个科学家联合发起、耗时一年多炼出了号称和GPT-3一样强大的语言模型BLOOM。还有AI画画趋势的头号明星Stable Diffusion,也是由Stability AI、EleutherAI和LAION多方联合完成的。
复现ChatGPT也是如此,Colossal-AI正在发起这一开发活动。
如果你对这项工作感兴趣or有好的想法,可通过以下方式与他们取得联系:
在GitHub发布issue或提交PR
加入Colossal-AI用户微信或Slack群交流
点击“阅读原文”填写合作提案
发送合作提案到邮箱[email protected]
传送门:
开源地址:
https://github.com/hpcaitech/ColossalAI
参考链接:
https://www.hpc-ai.tech/blog/colossal-ai-chatgpt
— 完 —
点这里关注我,记得标星哦~